
|
Sam Eldin Artificial Intelligence
Switch-Case Algorithm© |
|---|
|
Switch-Case Algorithm Table of Contents: • Introduction • Decision Tree • AI and Decision Tree • Pros and Cons of Decision Tree • Problem Definition • Existing Systems • Our Switch-Case Algorithm Alternative • Switch-Case Features • Decision-Maker to Expression Calculation Value as an Added Option • Switch-Case Limits • Decision-Maker to Expression Calculation Value • Our Switch-Case Algorithm Structure (not a Tree) • What is Our Switch-Case Algorithm? • What are the Processes-Steps of Our Switch-Case Algorithm? • What is our Switch-Case Algorithm Structure? • What are the Levels of Processing and Processing Power? • Integrating Our Switch-Case Algorithm with Other Algorithms • Data Classification • Our Machine Learning Engines and Data Classification Lookup Matrix • Our Switch-Case Algorithm and Data Classification • Our Machine Learning and Data Analysis-Processing and Data Classification • Our Machine Learning Engines • Where Does Our Switch-Case Algorithm Fit in the Overall Picture? • Different Businesses, Different Operations and Our Switch-Case AI Model-Agent Umbrella • Pharmacy and Insurance Companies Use Cases and The Needed Processes • Data Flow • Our Switch-Case AI Model Quick Presentation • Rationale Behind Choosing the Algorithm Introduction: Algorithms: Algorithms are procedures, often described in mathematical language or pseudocode, to be applied to a dataset to achieve a certain function or purpose. Models: Models are the output of an algorithm that has been applied to a dataset. Artificial Intelligence (AI) with all its hype is taking the world by storm and our attempt to master AI which requires lots of energy and time. As an Information Technology (IT) architect-analyst-developer-PM, I am trying to get on the bandwagon and be a part of AI future. Sadly, I am running into a lot of incomplete answers, unclear solutions, impractical padding and overkill of baseless AI material with no value. AI hallucinations can be the output of some of hottest AI tools. The goal is to learn AI and use my IT experiences and tools to hopefully master one aspect of AI. My decision was to create an AI training course and a simple AI model and combine both the education and real-world experience for optimum learning. We decided to use AI Decision Tree Model as our target system. We ran into a number of shortcomings with AI Decision Tree Model and that is one of our rationales to replace Decision Algorithm with our Switch-Case AI Model. Decision Tree: According to Google search: A decision tree is a tree-like model that acts as a decision support tool, visually displaying decisions and their potential outcomes, consequences, and costs. From there, the "branches" can easily be evaluated and compared in order to select the best courses of action. Decision tree analysis involves visually outlining the potential outcomes, costs, and consequences of a complex decision. These trees are particularly helpful for analyzing quantitative data and making a decision based on numbers. AI and Decision Tree: Decision trees in machine learning provide an effective decision-making method because they lay out the problem and all the possible outcomes. It enables developers to analyze the possible consequences of a decision, and as an algorithm accesses more data, it can predict outcomes for future data. Pros and Cons of Decision Tree: We need to present both the Pros and Cons of Decision Tree based on the following rating scale: 1. Low: Bad performance and Inaccurate predictions, significant discrepancies between actual and predicted outcomes 2. Medium: OK Performs well on most data but may struggle with complex or noisy data 3. High: Accurately predicts outcomes with high accuracy across different datasets Note: In term of The Cons categories, the High Score would mean the opposite of good performance. Decision Tree Rating Table: Our attempt here is to put a rough picture of the Pros and Cons of using Decision Tree as an AI Model-Agent.
Looking at Pros and Cons Rating Calculation Table we can see that the Decision Tree evaluation categories did not do scare high in the Pros (34 out of 75 maximum points) and secured very low in the Cons (67 out of 75 maximum points). The Decision Tree processes and analysis are very limited when it comes complex decisions and complex datasets. Problem Definition: Decision Tree algorithm and it's usage had been proven to work well in certain cases and not so well in others. It is more of "If-Else programming statement" with only two choices and no looping. Brach Left or Branch Right Bad data may send the parsing into one way with no return and no further options. The Decision Tree structuring may end with poor performance. Being a C, Java, C++ and other language programmer gave me the opportunity to use a number of programming statements and data structure. As an architect, these tools would add flexibility, power and help in building better classes, components, containers and business units. We are presenting an alternative to If-Else flow and structure with what is known as Switch-Case statement structure as our new Algorithm. We also named Switch-Case Algorithm. 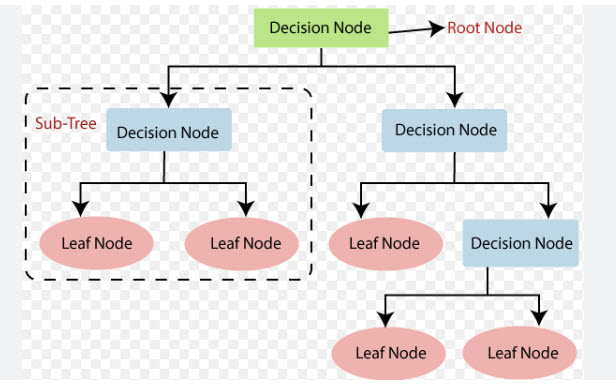
Image #1 - Decision Tree Structure Image Image #1 shows Decision Tree Structure with nodes and the flow from top to bottom and finally exiting the Decision Tree parsing, or building components. Such structure can perform well and also may have issues as one sided tree as Image #2. 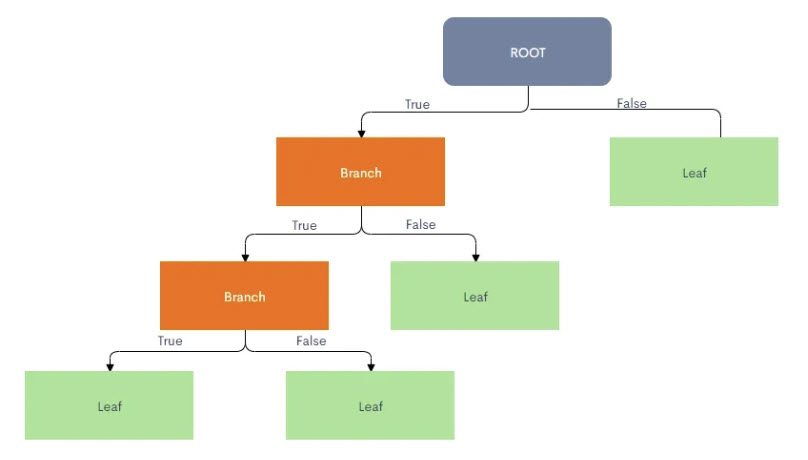
Image #2 - Uneven Tree Structure Image Image #2 shows Decision with Uneven Tree Structure. Existing Systems: ID3 Algorithm in Machine Learning: According to Google search: Decision trees are one of the most popular and intuitive algorithms in machine learning, valued for their simplicity and interpretability. Among these, the ID3 (Iterative Dichotomiser 3) algorithm stands out as a foundational method that paved the way for more advanced decision tree algorithms. 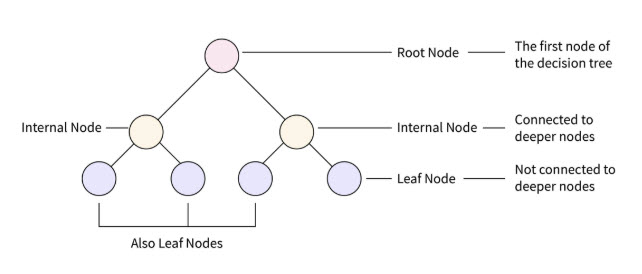
Image - ID3 Algorithm in Machine Learning Image The ID3 algorithm, a foundational method in machine learning for building decision trees, it is very simple, interpretability, and efficient handling of categorical data, but ID3 algorithm struggles with continuous data, overfitting, and lacks pruning mechanisms. Disadvantages of ID3: To avoid local optimum, search can be used to backtracking. ID3 can overfit to the training data. To avoid overfitting, smaller decision trees should be preferred over larger ones. ID3 algorithm usually produces small trees, but it does not always produce the smallest possible tree. Our Switch-Case Algorithm Alternative: Switch-Case Programming Structure: A programming switch statement is a control flow structure that allows the execution one of many code blocks based on the value of an expression. It is often used in place of if-else ladder when there are multiple conditional codes. The basic syntax of a switch-case structure in Java is as follows: switch(expression) { case x: // code block break; case y: // code block break; default: // code block } 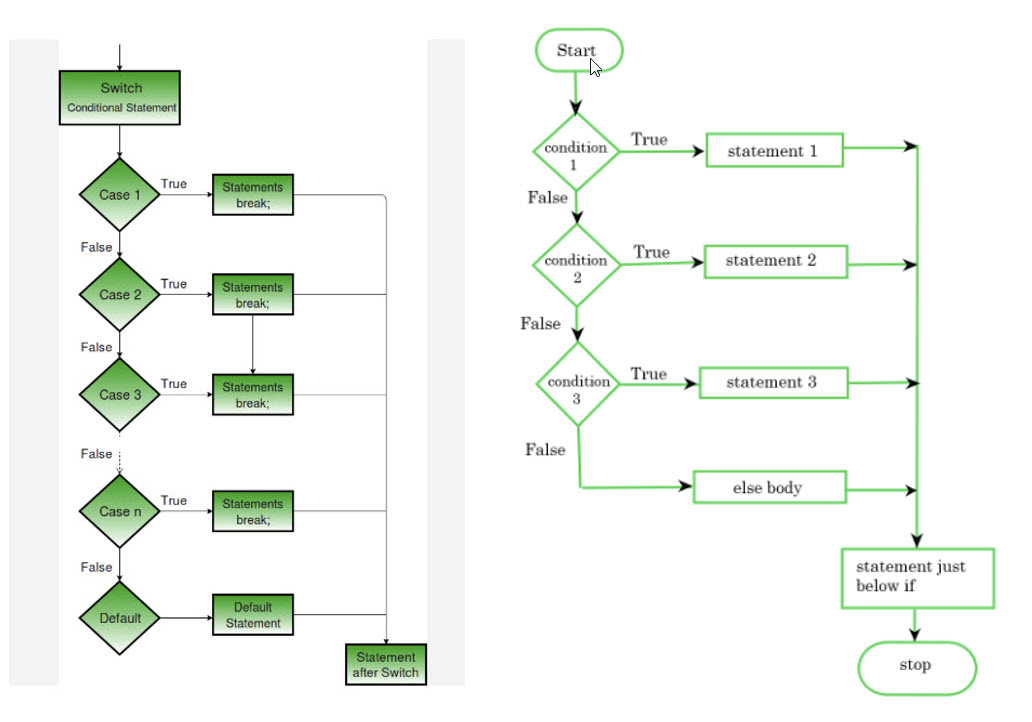
Image #3 - Switch Case + If Else Statements Structure Image Image #3 presents a comparison If-Else and Switch-Case, where the Switch-Case statement is more direction execution (more of Goto statement) with several options based on the value of the switch-case expression. As for the Decision Tree is very much an If-Else statement with only two branching (Left or Right branching). Switch-Case Features: Switch-Case Default: Both If-Else and Switch-Case statement have default, but the Switch-Case Default has far better setting: Range Cases: The following programming segment illustrates the use of range in switch case. int value = 55; switch (value) { case 50: case 51: case 52: // ... more cases case 59: System.out.println("Value is between 50 and 59"); break; case 60: case 61: case 62: // ... more cases case 69: System.out.println("Value is between 60 and 69"); break; default: System.out.println("Value is outside the specified ranges"); } Our "MISC" and "EXCEPTION" Addition to Switch-Case: In java and other programming languages, the default case or option with syntax "default" keyword is used to declare a block of code in situations where the tallied value doesn't match any of the case values in the list of the cases. default: // code block The syntax to declare it is followed by a block of code which will be executed if none of the cases are matched. This actually very practical approach to handle the default for a number of cases. switch(expression) { case x: // code block break; case y: // code block break; case MISC: // Miscellaneous break; case EXCEPTION: // Exception break; default: // code block } Since we are processing AI, Big Data and ML with possible a large number of exceptions and miscellaneous, we added both "MISC" and "EXCPTION" as options similar to the default. Parsing trees may need to have nested parsing and nested decisions, therefore, having nested cases statement within the cases would add multiple MISC, EXCPTION and defaults and that would add more parsing power to our Switch-Case Algorithm. Decision-Maker to Expression Calculation Value as an added option: The Switch-Case statement needs an integer expression or value to perform the logical flow of execution. We recommended and add a method call which would calculate the expression integer value for Switch-Case statement. With this method, we can build any number logic, statistic, educated guesses, or any AI and Big Data, ML analysis result. int expression = DecisionMakerMethod(…); switch(expression) { case x: // code block break; case y: // code block break; case MISC: // Miscellaneous break; case EXCPTION: // Exception break; default: // code block } Nested Cases: The following is an example of nested case with MISC_2, EXCEPTION_2 and default. switch(expression) { case x: // code block int expression_2 = DecisionMakerMethod(…); switch(expression_2) { case nested_2: // code block break; case MISC_2: // Miscellaneous break; case EXCPTION_2: // Exception break; default: // code block } break; case y: // code block break; case MISC: // Miscellaneous break; case EXCEPTION: // Exception break; default: // code block } With our recommendation of limiting the number of cases to only: 7 + MISC + EXCEPTION + default = 10 would help in managing the flow control of our parsing and tracking. Switch-Case Limits: We are recommending a limit of up to 7 cases (excluding ranges). Plus, we do have MISC and EXCPTION cases and default case, these are a total of 10 cases. When creating any system or structure, we need to remember that most human have a limit on the number that can be comprehended or handled. Therefore, we recommend that the cases (ranges are not included) should at most of seven-7 and not more. Architect, analysts, programmers and manager should be aware of our seven-7 limit when developing a system using our Switch-Case Algorithm. Decision-Maker to Expression Calculation Value: DecisionMakerMethod(…); Such method would help in creating-calculating an integer value based on the following educated options: 1. Statistical analysis - Statistical Value 2. Weight-Value 3. Data Patterns 4. Pattern Recognition 5. Probability 6. Calculations 7. Feedback Values 8. Predictions 9. Random Guess 10. Eliminating unlikely options 11. Relevant Data 12. Assumption 13. Misc 14. Exception 15. Guesstimate 16. Estimations 17. Frequencies 18. Patterns 19. Theoretically Data 20. Identify Patterns 21. Anticipate Behaviors 22. Personalize experiences 23. Forecast future events 24. Profiling 25. Frequencies 26. Educated Guess 27. Cushion (plus or minus 5%) In short, Intelligent Guessing, statistics, or any factors which would direct the selection option. Our Switch-Case Algorithm Structure (not a Tree): What are we trying to sell or provide? The Decision Tree had been used for long time and we believe we have a better solution which address the AI demands and cost reduction. The questions are: What is our Switch-Case Algorithm? What is our Switch-Case Algorithm Structure? What are the levels of processing and processing power? Comparison between Decision Tree and our Switch-Case Algorithm Structure. What are the wishful goals of Switch-Case Algorithm Structure? What is our Switch-Case Algorithm? Our Switch-Case Algorithm: Our Switch-Case Algorithm is: an intelligent expandable, reusable, iterate-able replacement of the Decision Tree algorithms, AI model and AI agents. What are the processes-steps of our Switch-Case Algorithm? The details needed for any algorithm to be built and executed for all cases including integration can be overwhelming and the amounts of details based on the business type and the target output would vary considerably. The following is the 2,000 Foot-View of Our Switch-Case Algorithm Processes needed: 1. Using and expanding the programming Switch Statement control flow 2. Added MISC and EXCEPTION cases to the Switch Case default 3. Provide more decision making and processes-points 4. Looping Options in the Switch-Case Control flow 5. Decision-making can be programmed, controlled and loop back for reuse 6. See the integration processes in Integrating Our Switch-Case Algorithm with other Algorithms section 7. Handling Big Data, ML matrices, AI options and AI control flow 
Image #4 - Switch-Case Algorithm Levels Structure Diagram Image Image #4 presents our Switch-Case Algorithm Structure using switch statement programming language control flow. The algorithm uses the default case, 7 other cases plus MISC and EXCEPTION cases (a total of 10 cases) to provide decision control options. Each of these decision control options or case can be nested to create another-addition 10 more decision control options. The algorithm has the ability of looping back from the beginning and that would also expand the options for iterating decisions and reusing the existing options (services). Image #4 presents the use of Decision-Maker control to direct the flow of executions of service or make nested or new decisions. Image #4 has three levels of nesting. The first level (Level #0) has 10 (what we recommend) decision points, the second nested level (Level #1) can have up to 100 decision points and the third nested level (Level #2) can have up to 1,000. The total of 1,110 decision-points. Looping back from the beginning or from a level higher would make the total of our algorithm decision-points in the tens of thousands. What is our Switch-Case Algorithm Structure? Note: Software Component: A software component is a modular, self-contained unit of software that encapsulates specific functionality, designed for reusability and maintainability, and can be deployed and composed independently. Software Container: A software container is a package of software that contains all the components needed to run an application in any environment. Image #5 presents a 2,000-Foot View of our Switch-Case Algorithm Structure. 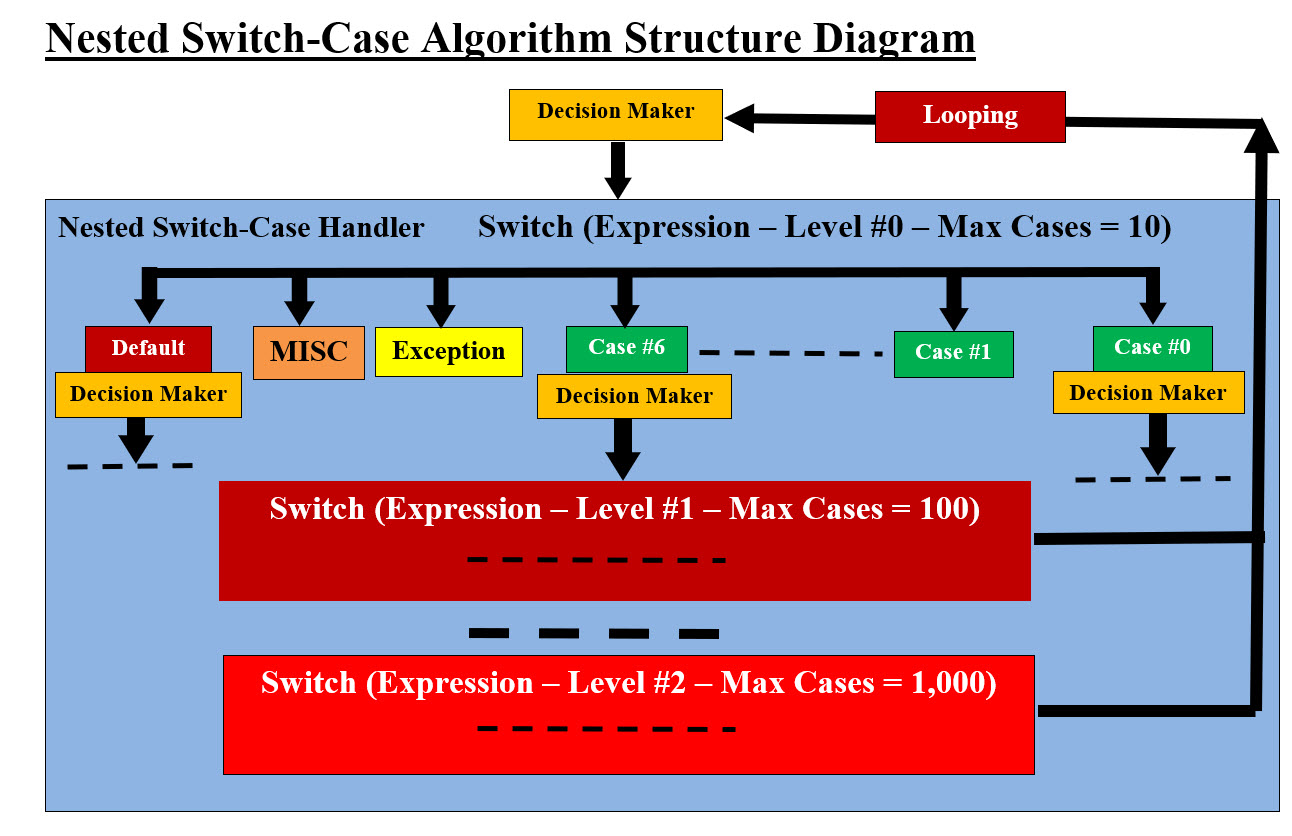
Image #5 - Nested Switch-Case Algorithm Structure Diagram Image The 2,000-Foot View of our Switch-Case Algorithm Structure is composed of: 1. Decision-Maker Object-component 2. Looping Object-component 3. Nested Outer-Level #Zero (0) container 4. Control Flow components - Arrows 5. Level #1 of containers and components 6. Level #2 of containers and components 7. Possible Level below Level #2 - not recommended 8. Looping or iterating Control Flow component The implantation and the development of each container, component, control flow and iteration are dependent on the business type and resources. For AI Model and Agents, we are in the process of implementing AI phone call services Model and Agent. AI models are primarily used to process data, while AI agents are used to interact with the environment and perform tasks. The primary difference between AI agents and AI models lies in their purpose and functionality. AI models are designed to process data and generate insights, while AI agents are built to interact with their environment and perform tasks autonomously. • AI Model runs the show • AI Agent tests the AI model What are the levels of processing and processing power? Looking at Image #5, the basic structure of our Switch-Case Algorithm is the Containers and Components. Containers would encompass other containers and components. The Container is the Switch-Case Statement structure with all of its 10 cases. The component is each case which would include the code for execution to perform the target goal. Each case can also be nested Switch-Case Container with 10 cases. The levels, cases and nesting of cases would add more Decision-Maker-Points for addressing target goals. Therefore, the number of Decision-Making-Point can be calculated as follows: Level #0 up to 10 cases total = 10 Level #1 up to 100 cases total = 110 Level #2 up to 1,000 cases total = 1,110 Level #3 we do not recommend sine things can get more complicated and add up to confusion and errors Comparison between Decision Tree and our Switch-Case Algorithm Structure: 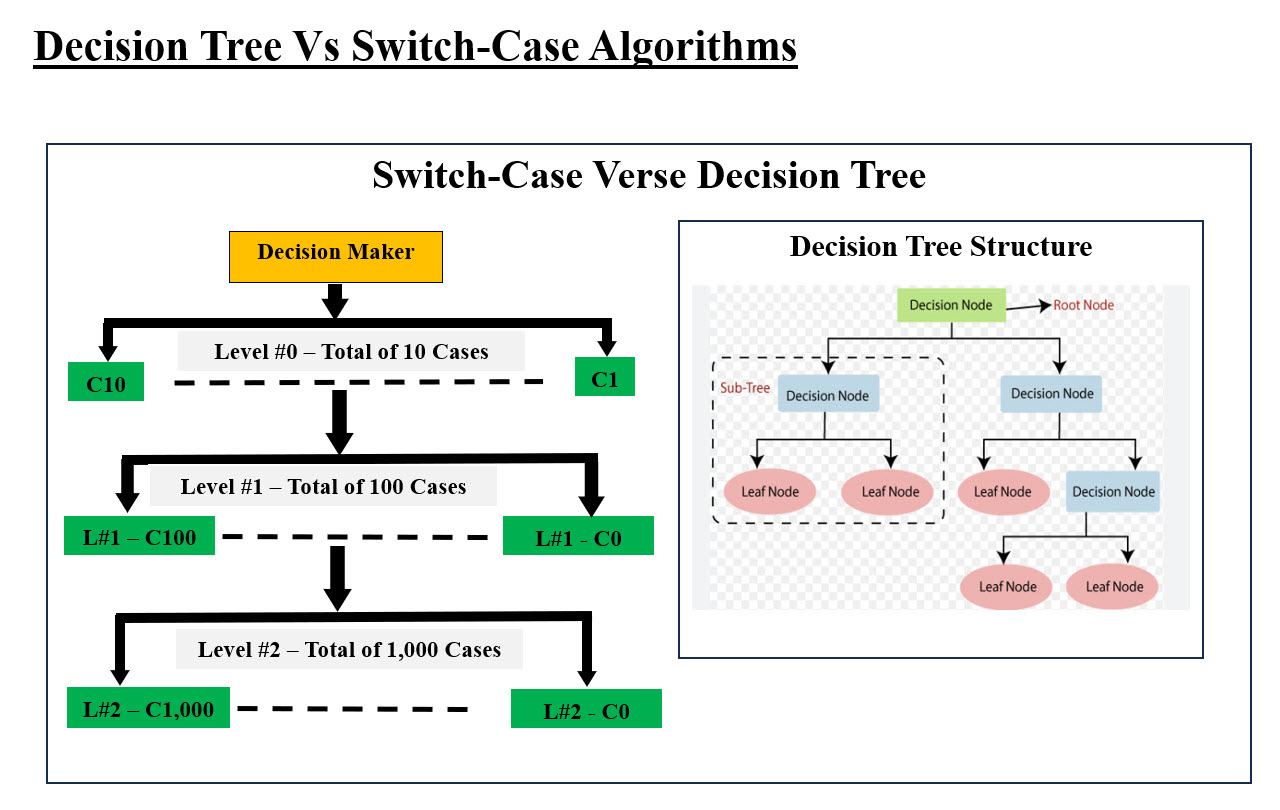
Image #6 - Comparison between Decision Tree and our Switch-Case Image Image #6 presents our Switch-Case Algorithm Structure verse Decision Tree Structure. In the Decision Tree structure which "If-Else Statement" with branching right or left with only two choices. The following Comparison Table would present the comparison and show the advantage of using our Switch-Case Algorithm over the Decision Tree Algorithm:
In a nutshell, if anyone would ask software language programmers which would they rather use "If-Else Statement" or "Switch-Case Statement." The answer is for sure will be "Switch-Case Statement." What are the wishful goals of Our Switch-Case Algorithm Structure? Our wishful goals of Switch-Case Algorithm Structure are:
Looking at all the listed categories, approaches and way of thinking, we see the fact that all these categories, approaches and way of thinking would have the following in common: • Default cases • Exceptions • Miscellaneous • The need to make educated-intelligent decisions • Have more than two options • Iteration options Our Switch-Case Algorithm Structure has all these common options built-in. Plus "Default, Exceptions and Miscellaneous" would help in bailing out difficult situations. As for AI Models, AI Agents, Big Data and ML, there are numerous decision and risk calculations which our Switch-Case Algorithm Structure would be almost the perfect foundation. Integrating Our Switch-Case Algorithm with other Algorithms: We need to examine the Decision Tree Algorithm(s) and how it integrates with other algorithms since we are a replacement to it. Decision Tree Algorithms can help in enhancing: • Interpretability • Predictive accuracy Decision tree algorithms can be integrated with various algorithms, including: Naive Bayes: Naive Bayes is a simple probabilistic classification algorithm based on Bayes' theorem, assuming features are conditionally independent, meaning the presence of one feature does not affect the presence of another. Gradient Boosting: Gradient boosting is a machine learning technique that combines multiple weak prediction models (like decision trees) to create a strong predictive model, iteratively improving performance by focusing on errors made by previous models. Gradient boosting is an algorithm that gradually increases its accuracy. To start the process, we need an initial guess or prediction. The initial guess is always the average of the target. M5 Model Tree: M5 model tree is a numerical prediction algorithm and its splitting criterion is based on the standard deviation of the values in the subset T of the training data that reaches a particular node (which is an analogue of entropy). Our Switch-Case Algorithm for General and Integration Processes: The details needed for any algorithm to be built and executed for all cases including integration can be overwhelming and the amounts of details based on the business type and the target output would vary considerably. The following is the 2,000 Foot-View of the needed processes: 1. Identify the problem 2. Define the following cases and the needed processes: 2.1 MISC 2.2 EXCEPTION 2.3 Default 3. Prepare Decision-Maker to Expression Calculation Value 4. Assign probabilities 5. Decision-Maker-Method (...) 6. Analysis and prepare the Nested Cases 7. Begin to structure the algorithm of each level structure 8. Estimate the number of: 8.1 Levels 8.2 Nesting 8.3 Total number of decision-making 8.4 Total number of code blocks 9. Looping Options in the Switch-Case Control flow 10. Decision-making can be programmed, controlled and loop back for reuse 11. Prepare Exist and End of Job processes and their code blocks 12. Identify decision alternatives 13. Estimate payoffs or costs 14. Determine the potential outcomes 15. Analyze-optimize and select the best decision 16. Loop back if needed Data Classification: What is data classification? Data classification is the process of analyzing structured or unstructured data and organizing it into categories based on a number of criteria and Special Contents. A common and effective approach to data classification involves categorizing data into the following levels: 1. Public data 2. Private data 3. Confidential data 4. Restricted data 5. Internal data 6. External 7. Purchased Our ML can use Our Switch-Case Algorithm to generate Data Classification Lookup Matrix as follows: int expression = DecisionMakerMethod(…); switch(expression) { case PUBLIC_DATA: // code block for Public data break; case PRIVATE_DATA: // code block for Private data break; case CONFIDENTIAL_DATA: // code block for Confidential data break; case RESTRICTED_DATA: // code block for Restricted data break; case INTERNAL_DATA: // code block for Internal data break; case EXTERNAL_DATA: // code block for External data break; case PURCHASED_DATA: // code block for Purchased data break; case MISC: // Miscellaneous break; case EXCPTION: // Exception break; default: // code block } Our Machine Learning Engines and Data Classification Lookup Matrix: Our ML would be creating Data Classification Lookup Matrix with, name, ID Number, handling indexes, security issue index, ... comments. Data Classification Lookup Matrix would guide ML engines on how to handle such types of Data Classification.
Data Classification Lookup Matrix presents a rough picture of what Data Classification Lookup Matrix would be. Data classification is a must for organizations and data classification helps organizations and answer important questions about their data: 1. Enable efficient data management 2. Manage risks 3. How they reduce or eliminate risks 4. Manage data governance policies 5. Reinforce data security 6. Aid regulatory compliance 7. Helps companies comply with regulations 8. Cut costs 9. Maintain data integrity Despite its technical nature, understanding how to perform data classification is a key element of a comprehensive data governance strategy. In a nutshell how important is data classification? Data classification is a critical foundation for effective: • Data protection strategies - security • Handling risks • Cut Costs Our Switch-Case Algorithm and Data Classification: How does our Switch-Case Algorithm help in Data Classification? We need present the most important fact when it comes AI model and AI agent or any algorithm performance is that: Data and data processing are the key ingredients for any success This statement means that having access to accurate and relevant data, and the ability to properly process and analyze it, is crucial for achieving positive outcomes in any field, as it provides the foundation for informed decision-making and strategic planning. Our Machine Learning and Data Analysis-Processing and Data Classification: Our Machine Learning View: Our Machine Learning (ML) View is that ML would perform the jobs of many data and system analysts. In short, our ML is an independent intelligent data and system Powerhouse. Our ML’s jobs or tasks would include all the possible data handling-processes. The Analysis List Tasks-Processes Table presents the needed analysis processes which our ML would perform.
Analysis List Tasks-Processes Table We can state with confidence that no human can perform all the listed processes or steps mentioned above, but our Machine Learning would be able to perform all the tasks (included in the Analysis List Tasks-Processes Table) with astonishing speed and accuracy. Our ML Processes-Analysis and Data Classification Our ML processes-analysis would also perform Data Classification. Our ML engines create data Matrices Pools for other ML engines. These data pools would include Data Classification Matrices also. Our Machine Learning Engines: What is an Engine? Based on Information Technologies background, an engine may have different meanings. Our Engine Definition: • An Engine is a running software (application, class, OS call) which performs one task and only one task • A Process is a running software which uses one or more engine • A Process may perform one or more task • Engines are used for building loose coupled system and transparencies • Updating one engines may not require updating any code in the system • A tree of running engines can be developed to perform multiple of tasks in a required sequence • Engines give options and diversities Our Machine Learning Data (Matrices) Processing Engines: 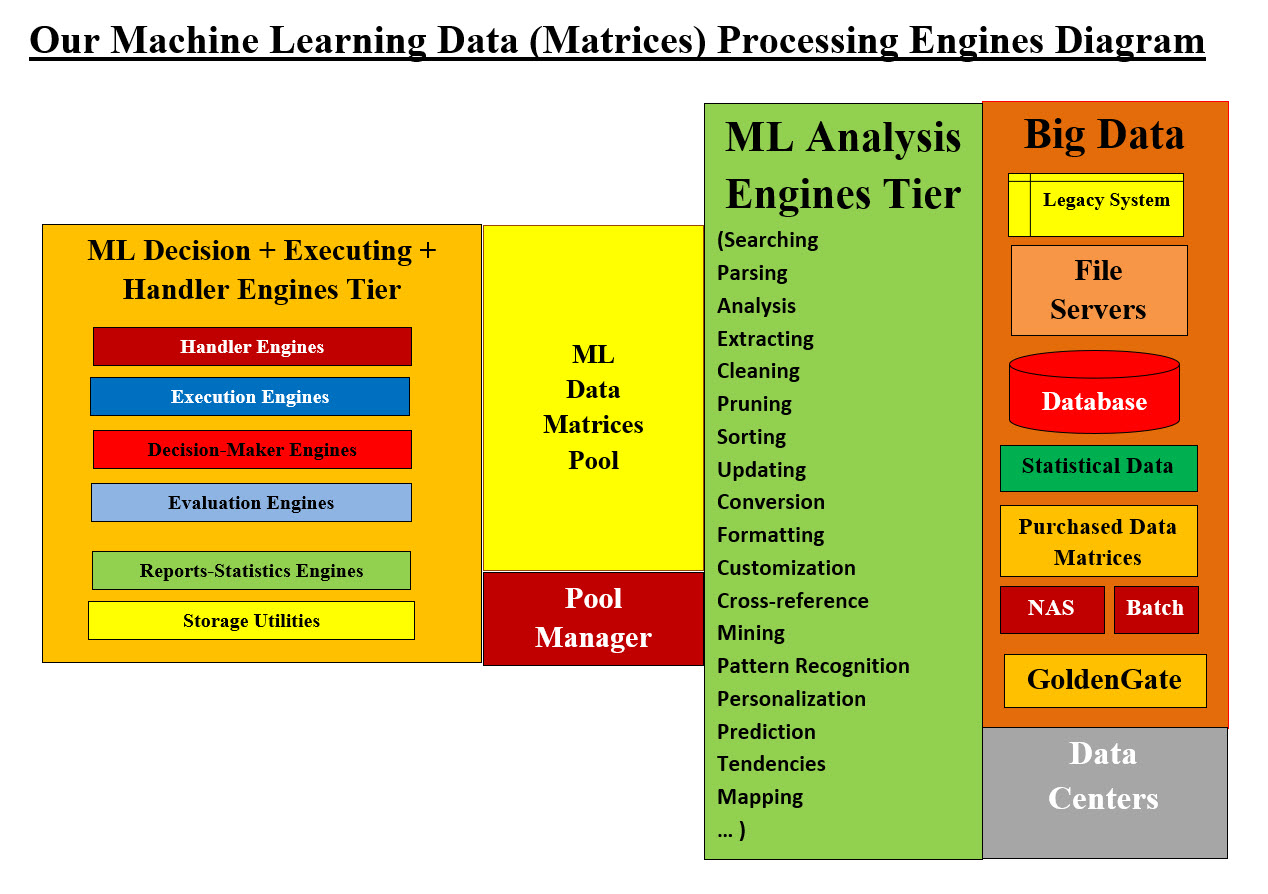
Image #7 - Our Machine Learning Data (Matrices) Processing Engines Image #7 has a number of tiers which we need to explain. First, Big Data, which can be composed of databases, filing system, Legacy System, purchased data, statistical data, Network Attached Storage (NAS) and batch processes which would also contain data. The running system can also be connected to Data Centers through GoldenGate system. Therefore, our ML analysis engines would be connecting and using such data to create a pool of matrices. Theses matrices must also be managed and must be continuously updated. ML Data Matrices Pool would be used by ML Decision, Executing and Handler Engines Tier which would be helping in the decision-making as well updating the data pool and Big Data. The entire system presented in Image #7 would be running in the background as support system. Image #7 presents Our Machine Learning Engines-Tiers. ML would perform the jobs of many data and system analysts. Our ML would be accessing Big Data and performing: 1. Data Analysis 2. Data Classification 3. Create Data Matrices Pool 4. Managing Data Matrices 5. Data Handling 6. Decision-Making Support 7. Updating data In short, our ML would be accessing Big Data (structure and unstructured) and create all the needed data matrices for any systems. Our ML would be running in the background and providing decision-making support plus updating the existing Big Data. Where Does Our Switch-Case Algorithm Fit in the Overall Picture? Quick Implementation of Our Switch-Case Algorithm: We are also working on presenting a Virtual Receptionist Powered by AI which we call Switch-Case AI Model and AI Agent. The goal of our Switch-Case AI Model is to present a Virtual Receptionist Powered by AI. The difference between Our Switch-Case Algorithm and Our Switch-Case AI Model-Agent is Our Switch-Case Algorithm is very short version Our Switch-Case AI Model. Our Switch-Case Algorithm Use Case Presentation: We would be presenting the Our Switch-Case Algorithm Steps for our Switch-Case AI Model and AI Agent. The 2,000 Foot-View Steps for Our Switch-Case Algorithm for General and Integration Processes: Step #1: Identify the Problem: Businesses are looking for an AI phone call service systems which use artificial intelligence to automatically answer incoming calls, handle basic inquiries, schedule appointments, and generally manage customer interactions with a Virtual Receptionist Powered by AI. It would be availability 24/7 and streamlined operations. Different Businesses, Different Operations and Our Switch-Case AI Model-Agent Umbrella: Different businesses would have their own unique and specific buzzword, jargons, and business transactions. The very same business may have several different levels of customers service, phone services and so on. For example, an insurance company have a number of different services, such as claims, purchasing plans or payment, but their business specific buzzword, jargons, and business transactions would be similar if not the same. Therefore, our Switch-Case AI Model-Agent would be the basic structure-foundation for all possible levels of customers service and phone services. Plus, within the same level of the business, there are several different services such as switchboard operator, secretary, receptionist, answering services, customer service, ordering service processing, ... etc. Our Switch-Case AI Model-Agent would be the umbrella which all these services would be using. The same thing would be applied for these services when these services may need to use different languages. Let us look at the different level of services which we are addressing with our Switch-Case AI Model-Agent: 1. Switchboard operator 2. Secretary 3. Receptionist 4. Answering services 5. Customer service 6. Ordering Service processing 7. Appointment scheduling 8. Booking appointments 9. Technical support 10. Trainer 11. Questions and answers 12. Call Center 13. Sales generation 14. Customer retention 15. Customer retaining 16. Customer preservation 17. Customer maintenance 18. Gate Call Box 19. Unique Customer call experience The key ingredient in our Model-AI-Agent is our Machine Learning (ML) system and tools. Our approach is not training AI with data, but analyzing, parsing data and preparing all possible scenarios, errors, situations, miscellaneous, ... etc. Plus using the speed of the computer system to handle volume, variation and miscellaneous. Step #2. Define the following cases and the needed processes: 2.1 MISC 2.2 EXCEPTION 2.3 Default Pharmacy and Insurance Companies Use Cases and The Needed Processes: We are presenting more of simplified use case of an incoming call to a pharmacy or an insurance company. The income call would have to pass through the company phone caller ID and security check. Caller ID: Caller ID is a phone feature that displays the name and/or phone number of an incoming call. It is available on mobile phones, landlines, and VoIP. The Call: The caller can be one of the following: 1. Current customer or client personal phone - mobile 2. A person who is calling on the behave of current customer or client 3. New customer-client 4. A con artist or scammer - Fraude 5. Unknown number 6. Known-Telemarketing 7. Individuals with disabilities 8. Misc 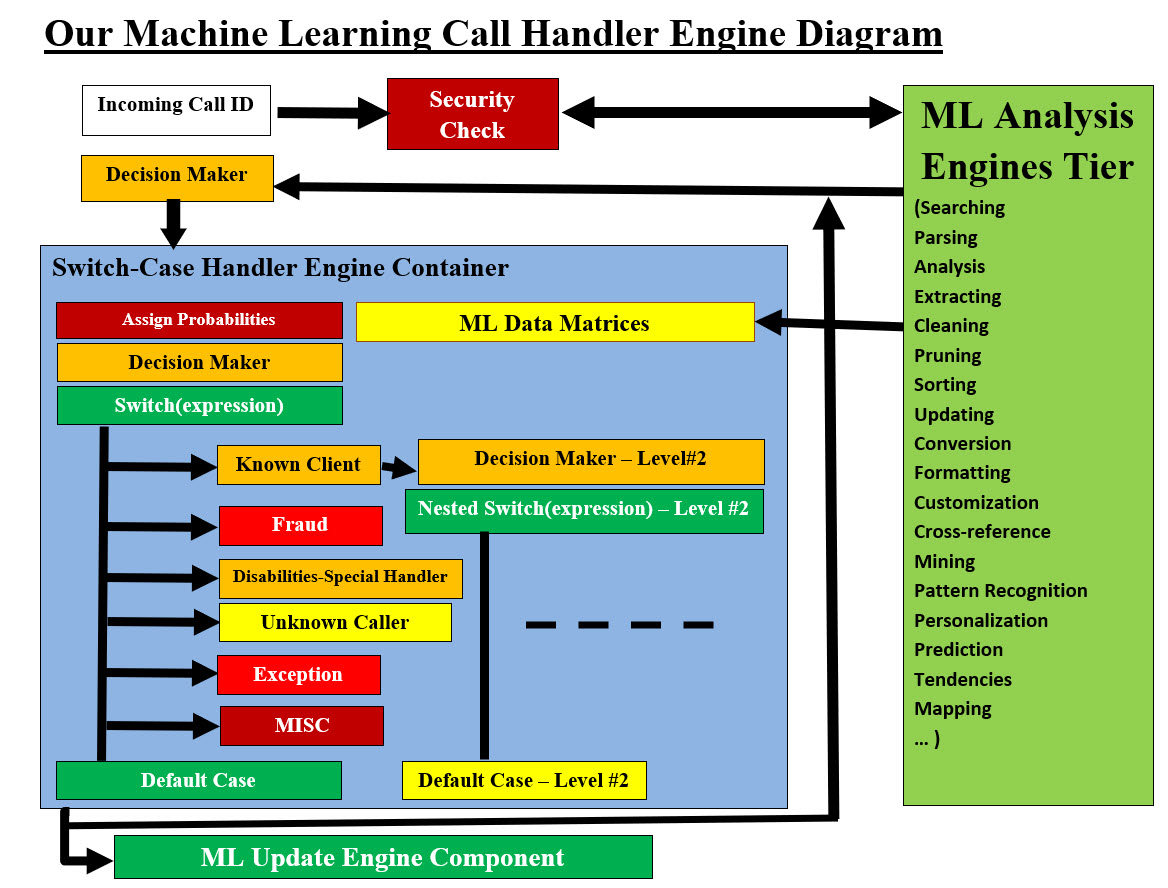
Image #8 - Our Machine Learning Call Handler Engine Diagram Image #8 presents the 2,000 Foot-View Steps for Our Switch-Case Algorithm for General and Integration Processes. Once Step # and #3 are completed, then rest of steps very much run with the Switch-Case Handler Container. The nesting is also shown for Known Client. Security Check Process: Our ML would receive the call ID request for more information and how to handle the call. Our ML would do its analysis processes and return a number of data matrices for ML Call Handler Engine to handle the call. Step #3: Prepare Decision-Maker to Expression Calculation Value: Decision-Maker-Method (...) Our ML Call Handler Engine: The ML Call Handler Engine will execute its code and call the Decision-maker to run and return Expression integer for our Switch-Case Algorithm Handler to run its course. Possible Cases of Expression Integer: 1. Company System in out of service - system is down - out of service handler 2. Caller with disabilities - Special handler 3. Unknown Customer-Client 4. Fraud Handler 5. MISC 6. EXCEPTION 7. Default Prepare Decision-Maker to Expression Calculation Value: Step #4: Assign Probabilities Step #5: Build its code segment - call the methods for handling the needed processes Image #8 presents the 2,000 Foot-View Steps for Our Switch-Case Algorithm for General and Integration Processes. Once Step #2 and #3 are completed, then rest of the steps are very much a run with the Switch-Case Handler Container. The nesting is also shown for Known Client. The following are the rest of the 2,000 Foot-View Steps for Our Switch-Case Algorithm for General and Integration Processes: Step #6: Analysis and prepare the Nested Cases Step #7: Begin to structure the algorithm of each level structure Step #8: Estimate the number of: Step #8.1: Levels Step #8.2: Nesting Step #8.3: Total number of decision-making Step #8.4: Total number of code blocks Step #9: Looping Options in the Switch-Case Control flow Step #10: Decision-making can be programmed, controlled and loop back for reuse Step #11: Prepare Exist and End of Job processes and their code blocks Step #12: Identify decision alternatives Step #13: Estimate payoffs or costs Step #14: Determine the potential outcomes Step #15: Analyze-optimize and select the best decision Step #16: Loop back if needed Data Flow: Data flow is an important concept in computing that defines the movement of information within a system's architecture from its source and journey through processing nodes, containers, components, business modules, programming modules, functions and data structures. Data may change format and more data would be generated. It would help envision security and system bottlenecks. Data Flow main Key Mechanisms are: • Data Format-Type (files, text, PDF, images, emails, sound, ...) • Data Sources • Data Transformation-Conversion • Data Destinations • Security Our Switch-Case Algorithm Data Source and Switch-Case AI Model-Agent: In our AI Model-Agent, there is a number of data sources: 1. ML analyzing Big Data to create data matrices for ML engines 2. Users' transaction 3. Tracking of events such date, time and place where our system is performing in real-time 4. Updating of system Big Data and data storage 5. Audit Trail - who, what and when transactions took place The above steps shown a number possible data generation (new sources) and the data flow from Big Data and back to Big Data including the tracking of all transactions and possible errors or security issues. Quick Introduction to Our Switch-Case AI Model: Introduction: Our Switch-Case AI Model's objective is to provide the needed AI Agent which would be able to perform multiple phone call services. For example, the customer's service calls to a pharmacy, an insurance company or a bank would be handled by our Switch-Case AI Model-Agent. Our model can be used by companies as their own systems base structure and foundation. They would be using our Switch-Case AI Model to develop their own unique customized phone services systems. Our Switch-Case AI Model is a Discriminative Model with ML, data structure, frameworks, processes, algorithms, management, training, testing, optimization, mapping, strategies, performance Evaluation and deployment. 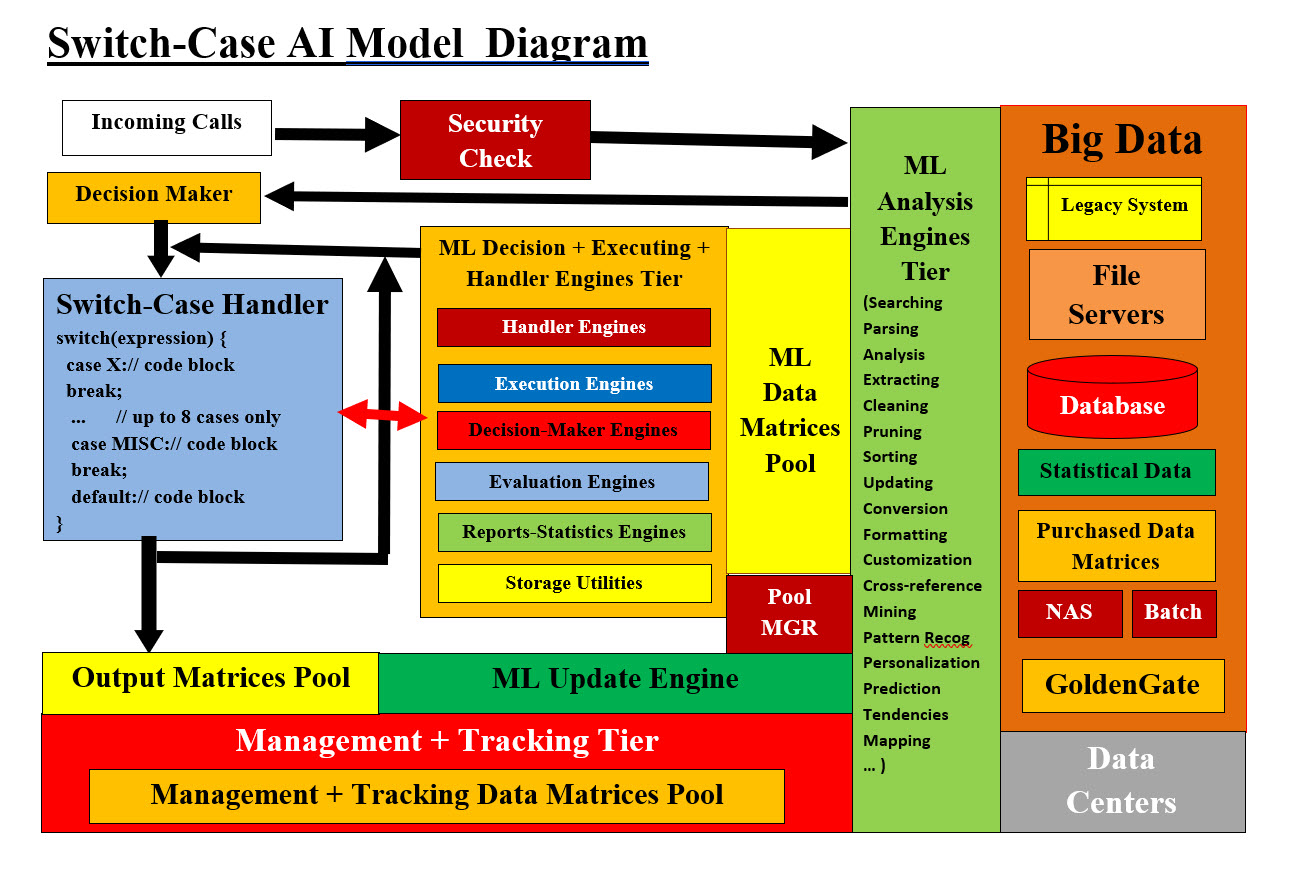
Image #9 - Our Switch-Case AI Model Diagram We are currently working on Our Switch-Case AI Model and our audience and readers are welcome to check our https://sameldin.com/ for the entire AI training course "Sam Eldin Artificial Intelligence Analysis, Architect-Design and Training Course ©." Image #9 presents Our Switch-Case AI Model Diagram where it shows how our ML Analysis Engines Tier would be accessing Big Data and preparing ML Data Matrices Pool. Such a Data Pool would be managed, updated and maintained for use and reuse by ML Decision + Executing and Handlers Engines Tier. These Decision + Executing + Handler Engines would be supporting Switch-Case Handler Container. The actual system execution would be running inside this container to run AI Virtual Answering Services. The Management and Tracking tier with their Data Matrices Pool would be used for managing, tracking and updating other data matrices pools. Decision + Executing + Handler Engines Tier has a number of specialized ML engines, Reports-statistic engines as well as storage utilities support engines and software. Data basically flow from the Big Data storages and ML Analysis Engines would access these storages and create ML Data Matrices Pool. The data from this data pool would be used by Decision + Executing + Handler Engines and they would provide the system with Virtual Receptionist Powered by AI. Our Switch-Case Algorithm would be used to run Our Switch-Case AI Model. Rationale Behind Choosing the Algorithm: Looking at the Table of Content of our presentation, we are trying to answer and address improvement to Decision Tree algorithm and other algorithms such as ID3 (Iterative Dichotomiser 3). New algorithms are central for improving both AI models and agents. New algorithms would empower them to learn, adapt, and perform more effectively. The following are features for our Switch-Case Algorithm: 1. Clarity - Easy steps to follow 2. Small number of processes 3. Logical Sequence 4. Easy to envision 5. Correctness 6. Improve efficiency 7. Can handle a wide range of inputs and scenarios 8. Scalable 9. Provides more options 10. Handles default, exceptions and miscellanies 11. Replace and Answer Decision Tree limitations 12. ML can use it to perform most of the data analysis The readers or our audience can check this document to see for themselves how Our Switch-Case Algorithm addressed the following: • Big Data • ML • Other Algorithms • Tools • Desired outcomes • Efficiency • Accuracy |
|---|