
|
|
Sam's Investors Presentation Script© |
|---|
|
Sam's Investors Presentation Script
Table of Contents: Introduction Our Tools, Know-How and Algorithms Our Machine Learning Automation, Intelligence, Virtualization - Adam's Blueprint Our Machine Learning Detection Approach Cybersecurity Search Patterns Trapping - Using Estimating the Total Number of Zeros-&-Ones Our Cloud Object Oriented Cybersecurity Detection (OOCD) Architecture Suite Artificial Intelligence (AI) Our Machine Learning Engines What is the difference between Our AI and current AI Bare-Metal Server Features DevOps Virtual Testing and Virtual Modeling Compression and Encryption Building Futuristic Data and AI Development Centers Distributed Network of AI Data Centers and Virtual Edge Computing with Machine Learning Building-Development Model Businesses Objects Our Solutions to Big Businesses, Medium and Small Size Businesses Return on Investment Introduction In the current news:
Total: Over ($100 billion + $11 billion + $3 trillion + $627.40 billion + $826.70 billion + Misc.) We believe that Machine Learning and AI will be the engines running everything in our world. What would happen if ML and AI fall into the Wrong Hands? ML and AI can be used to automate and enhance cyberattacks, making them more sophisticated and evasive. Not to mention, terrorists are targeting government systems. Governments officials would be relying solely on their AI in their decisions including starting wars. Our Machine Learning: We believe the existing ML in the market is a guessing game, no real-science behind it. It is more of Data Minding than what a true ML should be. See the images presented in our ML page. Machine Learning Algorithms and Model Search the internet for Machine Learning Algorithms and Model principles, we found the Images #1 and #2 presenting the components of Learning Algorithms. Sadly, we do not believe these Machine Learning approaches would work with real world diverse and complicated data. Therefore, we will not spend any energy on these approaches and we will be presenting our intelligent, dynamic and flexible Machine learning processes. 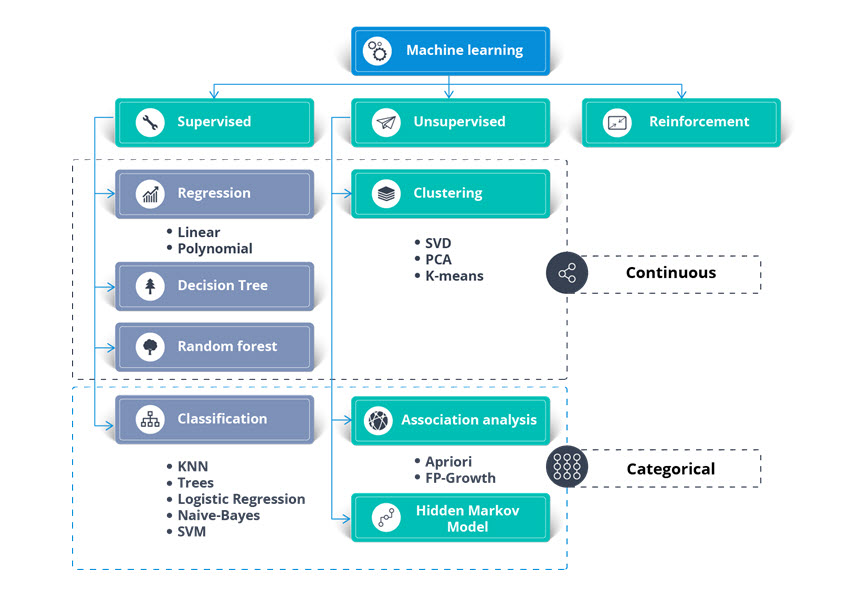
Image #1 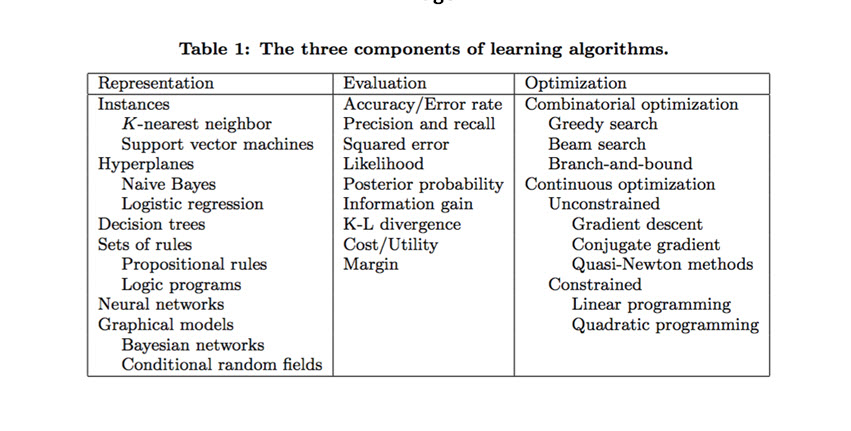
Image #2 Data Bias or Real World Data 
Image #3 Our Zeros and Ones Concept and Components The basic concept of any computer is the binary bit (0,1). Computer Science was able to turn this binary 0s and 1s into a revolution of technologies that we are using today. With the same thinking, we use the concept of 0s and 1s to build search patterns. We would also use Dynamic Business Rules as guidance in building the search patterns. We build from Zeros and Ones a Byte, then use bytes to build a word and use words to build patterns. The best way to make our concept more clear is by present Donald toy as an example. The following images are Bits which would be used to build one Byte For Donald: 
Image #4 The following would be some of possible Bytes which is built from these bits: 
Image #5 The Dynamic Business Rules would help in fine tuning the building of the Bytes, the Words, and finally the Target Pattern(s). The Target Patterns can be scaled, rotated, (side way, upside down, left, mirror image, etc) 
Image #6 The sky is the limit when it comes to build the the Target Pattern(s) and with the speed of the computer processes there is no issues by going "coco" - crazy. Zeros and Ones would be used to build the bytes, then bytes build words and words build patterns - does not make any difference if the data is text, graphic images, sounds waive, etc. Looking at our ML which is based on Zeros-Ones approach and replacing the analysts' job. Machine Learning Analysis Tier: Our Machine Learning View: Our Machine Learning (ML) View is that ML would perform the jobs of many data and system analysts. In short, our ML is an independent intelligent data and system Powerhouse. Our ML’s jobs or tasks would include all the possible data handling-processes. The Analysis List Tasks-Processes Table presents the needed analysis processes which our ML would perform.
Analysis List Tasks-Processes Table We can state with confidence that no human can perform all the listed processes or steps mentioned above, but our Machine Learning would be able to perform all the tasks (included in the Analysis List Tasks-Processes Table) with astonishing speed and accuracy. Automation, Intelligence, Virtualization - Adam's Blueprint: This page is called "Adam's Blueprint for Security" so we would answer as well as give credit to a friend of us named "Adam." As we were discussing with Adam our approaches, architects and design, his reply was: "Do not sell me fish in the Ocean, give me a blueprint" His first question was: What would you do when your network is attacked? Introduction: It is critical that we present in Image #7 a rough image of cloud, software, hardware, internal hackers, security layers and external attacks. Images #8 is what we call analysis of hackers attacks and the relationship of attacks and networks tiers. Sadly, hackers have the upper hand since system are sitting docks for target practice. Not to mention there plenty of items to attack at anytime or at attackers convenience. Coordination of attacks with the support of Artificial Intelligence are growing, getting more sophisticated and have devastating damages and lose of revenues. 
Image #7 
Image #8 Looking at Image #8, anyone can see that hackers did not leave any room without lunching multiple level and types of attacks. Zero-Day Attack, Reverse-Engineer of Patch Code and Internal Hackers are the toughest challenges which Cybersecurity must deal with. Hackers also atta the internet system itself, the sessions, the protocols, the packets, ... etc. Now, hackers have added ML and AI to their arsenals. Our Machine Learning Detection Approach: Our approach is: Every inbound byte is guilty until it is proven innocent We are performing Cybersecurity detection at the Operating System (OS) Level: We literally helping the Operating System trap any macro system (function) call at the execution level. The trapping or the red flag would be performed at very high speed and will not slow or affect system performance. 
Image #9 Looking at Image #9, all the OSI seven layers or TCP/IP five layers can be hacked. Our main concern in this page is the packet's data. All the internet inbound traffic (digital) is composed of streams of bytes and any stream could be a possible carrier of hackers' code. Our Machine Learning Detection Strategies Looking at Image #9, scanning the inbound byte streams is an overwhelming task to any scanning tool: • The malicious code can be embedded in any stream and at any position in the stream • Possible Variation of code • Tactics used • The attacks can be relentless Hacking Scenarios: • ".exe" hackers' code in middle of files (images, PDF, HTML, text, emails, ... etc) • Self-extracting zipped code in the middle of files (images, PDF, HTML, text, emails, ... etc) • Hidden code in DLLs • Cross-site scripting (XSS) attack • Hashing functions Our Machine Learning Detection Components are: Our architect-design has robust components for continuous scanning. In the case of our scanning encounters a difficult, time consuming or a new case, the scanning would be moved a Dedicated Virtual Testing Server to handle the issues separately. Our Crashes rollback is nothing more than moving the production IP address to the Virtual Rollback Server. 
Image #10 Looking at the Image #10, we have three virtual servers or subsystems. The 2,000 foot view of our ML has the following major subsystems:
Cybersecurity Search Patterns Trapping - Using Estimating the Total Number of Zeros-&-Ones: At this point in the Analysis-Design-Architect, we can give a good estimate of all the possible Zeros-&-Ones Search Patterns. Let us examine the following facts. Statements and Functions: The number of Zeros-&-Ones would be close to any OS, programming languages or scripts built-in functions, macros and commands. For example, our Zeros-&-Ones for C language would what the C complier would be using: abort, abs, acos, asctime, asin, assert ... tan, tanh, time, tmpfile, tmpnam, tolower, toupper, ungetc, va_arg, vprintf, vfprintf, and vsprintf We estimated to be little over 140 function-call and our prediction for the rest of the programming languages would be close. Our task is doable with far less search items than what we believe the security vendors searching tools are using. What is the total number of the build-in functions and commands which all the listed OS and Compiler-Interpreters? Let us look at the following: • Linux Kernel uses over 100 commands • Unix Kernel uses over 100 commands • C Language has about 140 built-in function Assumptions: Our estimate of all the OS and Compiler-Interpreters would be: 20 OS and Compiler-Interpreters * 200 build-in function and command = 4,000 Let us assume that each of the build-in function and command has 10 possible variations (on an average) Our estimate of the number of Zeros-&-Ones Search Patterns would be 4,000 build-in function and command * 10 possible variations = 40,000 Search Patterns The good news is Zeros-&-Ones Search Patterns is not in the millions plus each type OS and Compiler-Interpreters would work with only small portion of the 40,000 Search Patterns total. Our Cloud Object Oriented Cybersecurity Detection (OOCD) Architecture Suite:: What is Our Cloud Object Oriented Cybersecurity Detection (OOCD) Suite? OOCD Suite is: A multitier cloud system with intelligent and virtual components which we had architected-designed to secure End-2-End any cloud system from internal and external hacking attacks. Security is implemented independently by each tier. OOCD Suite is scalable, integrate-able to any cloud system. Image #11 represents our 2,000 foot view. 
Image #11 Image #11 represents three views: • The outside would including millions of hackers • Our OOCD - tiers and components • Any existing cloud system which our OCCD Suite would be protecting Performance Performance would measure by the performance speed of the detection protection and the creation of detection-protection itself. Only the needed virtual services or detection objects would be created. All the services and detection objects are virtual and scalable. The newly discovered hackers' IP addresses or malicious code be used immediately by OOCD inheritance features and no need to depend firewalls or any vendors support. Vertical and Horizontal Scalabilities: Our OOCD Suite is composed of a number of virtual tiers and virtual components. Creating or deleting any number of tiers and their components can be automated. Creating any number of a specific tier and their components can also be created on the fly to handle traffic loads. For example, Big Data and CRM Services may not be required by clients with limited number of customers or services. Our OCCD suite Virtual Cloud Buffer creations and deletions would be automated to handle malware attacks. Machine Learning support would be combined to deter DDoS Attacks. Artificial Intelligence (AI): Human Intelligence and Artificial Intelligence: What is human Intelligence? What is Machine Intelligence? We human take our intelligence and abilities for granted and we may not agree on: What Intelligence is all about? Therefore, our attempt here is to build an AI system or in short, a software program with intelligence. In other words, how to add or build a computer system or a software that we consider intelligent or has intelligence. As a team of IT professionals, we would need to list the concepts or the abilities which would be able to add intelligence to any software or a computer system. Note: The readers need not to agree with our list as follows: 1. Planning 2. Understanding 2A. Parse 2B. Compare 2C. Search 3. Performs abstract thinking 3A. Closed-box thinking 4. Solves problems 5. Critical Thinking 5A. The ability to assess new possibilities 5B. Decide whether they match a plan 6. Gives Choices 7. Communicates 8. Self-Awareness 9. Reasoning in Learning 10. Metacognition - Thinking about Thinking 11. Training 12. Retraining 13. Self-Correcting 14. Hallucinations 15. Creativity 16. Adaptability 17. Perception 18. Emotional Intelligence and Moral Reasoning Switch-Case AI Model-Agent (Our AI Virtual Receptionist Systems) Example: Our Switch AI Model-Agent 2,000 Foot View Tiered Structure: A 2,000 Foot-View Tiered Structure is a common business phrase that refers to a high-level, strategic perspective, allowing for a broader understanding of a situation or problem, rather than getting bogged down in the details. 
Image #12 - Our Switch-Case AI Model-Agent 2.000 Foot View Tiered Structure Diagram Image Image #12 presents a rough picture of Our Switch-Case AI Model-Agent 2.000 Foot View Tiered Structure Diagram. Our AI Model is composed of the following tiers: 1. Big Data Tier 2. Machine Learning Analysis Tier 3. Data Matrices Pool Tier 4. Added Intelligence Engines Tier 5. Management and Tracking Tier 6. Updates Tier 7. User Interface Tier What is the difference between Our AI and current AI: The Current AI Building Processes: The current AI Models and Machine Learning (ML) is built on supervised learning, unsupervised learning, reinforcement learning and Regression as shown in Image #1. AI Model is further evolved into Deep Learning, Forward Propagation and Backpropagation and using the structure of neural networks. AI models are categorized as Generative, Discriminative AI models and Large Language Models (LLMs). The difference is regarding training data requirements and explicitly. • Generative Models employ unsupervised learning techniques and are trained on unlabeled data • Discriminative Models excel in supervised learning and are trained on labelled datasets • Large Language Models (LLMs) Large Language Models (LLMs) are a type of artificial intelligence that uses machine learning to understand and generate human language. They are trained on massive amounts of text data, allowing them to predict and generate coherent and contextually relevant text. LLMs are used in various applications like chatbots, virtual assistants, content generation, and machine translation. 
Image #13 - Current AI Model Vs Our Switch AI Model-Agent Diagram Image Our AI Building Processes: Our Switch-Case AI Model is a Generative model employing unsupervised learning techniques. Our AI Model building approach follows the existing AI approaches. Our AI Model is based on our ML Data Matrices Pool and Added Intelligence Engines Tier. There is no model training nor labeling, but ML Analysis Engines Tier which uses Big Data to build our Data Matrices Pool. This Data Matrices Pool is used by our Added Intelligence Engines Tier. Our Intelligence Engines Tier is the replacement of the Deep Learning and the neural networks components of the current existing AI model building processes. Deep Learning and neural networks are not used by our Model, but we are adding our Added Intelligence Engines Tier instead of the Deep Learning and the neural networks. Image #13 presents a rough picture the Current AI Model Structure verse Our Switch-Case AI Model-Agent. AI projects and training: Their approach is using photographic memory which is one form of intelligence. Give them credit for a lot of images and texts AI performance, but their approach will fail if they are moved out of their domain. Current AI using Labeling and LLMs: What is labelling in AI? In machine learning, data labeling is the process of identifying raw data (images, text files, videos, etc.) and adding one or more meaningful and informative labels to provide context so that a machine learning model can learn from it. In essence, labeling definitions are the roadmap for AI to learn and understand the world through data. They ensure that AI models are trained on accurate, consistent, and relevant information, leading to reliable and trustworthy AI applications. Our Issues with Current AI: We believe that labeling is like a person with photographic memory, where he would be able to remember questions and answers, and a number of things and may sound intelligent. But if he moves out of his domain of his memory, he will be lost and cannot function. Therefore, we do not train our AI Model, but our AI Model has intelligent as we described in top section. Labeling also is limited to data the AI Model trained on, but as time passes and things change, these training label data would be dated and of no value. Let us look at the following label training on dogs: picture of dog - Google Search picture of robot dog - Google Search using lego toys to create a dog - Google Search transformer dogs images - Google Search As you can see, AI Model will not succeed in keeping up with all types of dogs and their characteristics. Sam's Bare-Metal Server Features Introduction: The required speed of computer-server CPU (for supporting ML, AI, Cybersecurity, Graphic, language analysis, data analysis. …) is critical to any AI Model-Agent. CPU speed is directly related to the speed of system buses for transfer data, addresses, and control signals. Therefore, this page presents the issue of Bare-Metal Server Features. Bare-Metal Server Features Our ML main goal is scanning for possible malicious code and remove it from the network. Scanning is two parts, first inbound bytes and second is the content of the network. Scanning speed in very critical for our ML to be of any value. The focus of this section is our recommendation of what should be the bare-metal server(s) structure. The goal is to exclusively execute our ML software on the bare-metal without sharing the bare-metal with other processes or programs except the Operation System. 
Image #14 
Image #15 Images #14,#15 are rough pictures of what we believe should Bare-Metal Structure would have as its internal components. Our goal is speed and we are open for recommendations, corrections or suggestions. Bare-Metal Server, Scanning Network's Inbound Traffic, Image #4 presents how the network's would scan all the firewalls traffic. Performance Speed: We choose bare-metal server with 8 or more processors, all the core memory the server would have. Each processor would have its own Cache, registers and its own virtual server. Each processor would run independently. We hope that we our recommendation is not dated and there could be more advance bare-metal servers than what we are presenting. What factors would be considered in bare-metal structure and its performance? CPU, core, clock speed, registers, cache memory, core memory, bus, chip manufacture support, software support, VM, labor, time, testing and cost. Note: Physical or bare-metal server's hardware is quite different than that of other types of computers. Physical server would have Multi-Core processors, IO Controller with multiple hard drive, Error Correction Code (ECC) memory, multiple power supply, threading, parallel computing, redundancies, ..etc. The reason for all these additions is the fact that servers run 24X7 and data loss, damages or slow performance would translate to losing business, customers, ..etc. The goal of ML bare-metal is to handle the throughput of all the firewalls. Let us Do the Math: Max number packets one firewall would handle = 64,584 packets per second With high-performance software, a single modern server processes over 1 million HTTP requests per second. The fact that the average packet size is about 1,500 byte A 32-bit CPU can process 34,359,738,368 bits per second = 4,294,967,296 byte per second. Max number bytes one, 10, 100 or 1,000 firewall would handle: One firewall = 64,584 X 1,500 = 96,876,000 about 100 Millions byte per second 10 firewalls = 1 billion byte per second 100 firewalls = 10 billion byte per second 1,000 firewalls = 1 trillion byte per second One CPU = 4 trillion byte How many bytes would 8 core processor would process per? In term of hardware, what we are asking is the following: 1. 8 or more processors 2. High or fast Clock speed 3. 64 bit registers 4. Number of registers - Max 5. The biggest Cache the machine can have 6. The biggest size of RAM the machine can have 7. 128 bit or more Bus size Computer Buses: How important Computer Bus? Computer buses are crucial hardware components that act as communication pathways, enabling different parts of a computer to exchange data and instructions. They are essential for the efficient operation of a computer system, allowing components like the CPU, memory, and peripherals to interact. Importance of Computer Buses: Data Transfer Address and Control System Performance Communication Between Components Types of Computer Buses: There are two types of computer buses: 1. System Buses 2. I/O Buses What is the difference between system Bus and I/O bus? The system bus connects the CPU to the computer's main memory, while the I/O bus connects the CPU to peripheral devices like keyboards, mice, and printers. In essence, the system bus handles internal communication within the computer, while the I/O bus handles communication with external devices. DevOps: What is DevOps? DevOps is the combination of cultural philosophies, practices, and tools that increases an organization's ability to deliver applications and services at high velocity: evolving and improving products at a faster pace than organizations using traditional software development and infrastructure management processes. In a nutshell, DevOps is the teaming of infrastructure and development teams to speed the process of delivering applications and services for an institution. Our View of DevOps: We need to cover a number of concepts and show some images to keep our audience in the same page: What is a cloud network? A cloud network is a Wide Area Network (WAN) that hosts users and resources and allows the two to communicate via cloud-based technologies. It consists of virtual routers, firewalls, and network management software. 
Cloud Network - Image #16 "Satellite Communications in a nutshell" 
European Communication Ecosystem - Image #17 A cloud network is a type of IT infrastructure where the organization's networking resources are hosted in a cloud platform (public, private, or hybrid). It allows organizations to access and manage networking capabilities and resources, such as virtual routers, firewalls, and bandwidth management tools, through a cloud provider. Image #16-17 present our view of the performance of IT infrastructures. In Image #17, Satellite Communications is connected to each item or structure which are receiving Satellite signals. They all must be have infrastructure support including mobile. The infrastructure support is basically the software and hardware which communicate with Satellite. What is HTTP Network? In networking, HTTP (Hypertext Transfer Protocol) is the foundation of data communication on the World Wide Web. It defines how web browsers and servers communicate to transfer data, allowing users to access and interact with online content. HTTP uses a request-response model, where a client (usually a web browser) initiates a request to a server, which then responds with the requested resource. What is the difference between cloud network and HTTP network? Cloud networks and HTTP networks, while related, serve distinct purposes. Cloud networks are broader, referring to the overall infrastructure and services provided by cloud providers, while HTTP is a specific protocol for web communication. Cloud networks encompass various services and technologies, including networking components and resources, accessible over the internet. HTTP, on the other hand, is a protocol used for transferring data over the internet, particularly for web pages. Note: To us, they both the same thing, HTTP is the internet protocol which cloud networks use to communicate. The difference is cloud networks have evolve into other protocols than the traditional HTTP. What protocol cloud networks use? Cloud networks utilize a variety of protocols for connecting, including IP, TCP, UDP, MQTT, HTTP, and IPsec. HTTP/HTTPS are standard web protocols used for data transmission between clients and servers. We need to present Our DevOps roles in cloud network: What is the definition of a computer network? A computer network is a system that connects two or more computing devices for transmitting and sharing information. Computing devices include everything from a mobile phone to a server. These devices are connected using physical wires such as fiber optics, but they can also be wireless. What is the definition of a computer network in term of infrastructure? 
Network Infrastructure Containers and Components- Image #18 Network infrastructure refers to the hardware and software that enable network connectivity and communication between users, devices, apps, the internet, and more. Image #18 shows internal details of a running network. Internal structure may include application servers, database servers, batch servers, bridge servers and testing servers It will also have a running Operating System, management system(s), support software and the actual bare-metal servers. What is clustering in networking? Cluster computing is a kind of distributed computing, a type of computing that links computers together on a network to perform a computational task, increase computational power and function as a single computer. 
Networks and Networks Management System- Image #19 Image #19 presents Network Clusters and their management system. Again, bare-metal servers, Operating system and supporting software and services. Infrastructure network clustering involves grouping multiple network devices (like servers, routers, or switches) to function as a single, unified system. This allows for redundancy, load balancing, and increased capacity. Essentially, a cluster is a collection of interconnected devices working together to handle tasks and provide services as if they were a single entity. Redefining DevOps: In a nutshell, DevOps is the teaming of infrastructure and development teams to speed the process of delivering applications and services for an institution. What about teams or departments other than development? The DevOps goal is to improve the communication and cooperation between the development and the infrastructure teams. Sadly, nothing is mention about the infrastructure needs for other departments' teams such as Sales, Marketing, Credit, Treasury, etc. These teams have web presence and run third party and customized software tools. Automating DevOps: What we presented so far is the needed infrastructure (software and hardware) required by any company, departments, groups, individual and mobile to run with their required services. They all need both hardware and software including Operating Systems to run their clusters of networks, networks, personal computers and mobile. For all of them to communicate and exchanges services and data, both infrastructure department-teams and the rest need to communicate and work together to have the needed services running. This is main reason we created our Intelligent DevOps Editors. Each Editor is architected-designed to service each group and free the infrastructure teams from dealing with these groups. The concept of our Intelligent DevOps Editors is the same as using installation software to install the needed software. In the case of the editors, these editors create networks, cluster of networks, cloud system and all the above. What is a software editor? In general, an editor refers to any program capable of editing files. Good examples are image editors, such as Adobe Photoshop, and sound editors, such as Audacity or for text editor such as Microsoft Word or WordPerfect. What is Our Intelligent DevOps Editor(s)? How can we build such an Intelligent DevOps Editor? The key feature of our DevOps Editor is Intelligence. Intelligence here is not Artificial Intelligence, but developing intelligence software. We communicate with gurus of development and infrastructure, and try to pick their brains. We build a number of processes and tasks mimicking these gurus handling and approaches. We rearrange these processes and tasks in order to be able to translated them to code and a running software. With the computer processing speed, thousands if not hundreds of thousands of processes and options can be performed on the input data in seconds. These processes add to intelligence of our editor. Our Intelligent DevOps Editors We have architected-designed and created prototypes for six DevOps Editors. We recommend that our viewers visit the following links and checkout each editor. We are open for feedbacks and comments ( Sam@SamEldin.com ): Data Center Specification Editor Data Center Specification Network Editor Data Center Specification Migration Editor Data Center Migration Builder Data Center's Testing - Tracking - Validation Editor Intelligent DevOps Editor - "Turn Key" Virtual Testing and Virtual Modeling: What is the software testing? Software testing is the process of evaluating and verifying that a software product or application does what it's supposed to do. The benefits of good testing include preventing bugs and improving performance. What is virtual testing? Virtual testing refers to the process of evaluating products, systems, or software in a simulated digital environment before physical prototypes are made. This method enhances efficiency by reducing costs and development time while allowing for rapid iterations and error identification. What is AI Testing? AI testing differs from traditional software testing in that it leverages AI-powered testing tools to improve testing efficiency and effectiveness. Traditional software testing primarily relies on manual efforts, while AI testing incorporates automated test case generation, execution, and analysis using AI algorithms. Rollback: A rollback is the process of returning the running system to its previous state. Rollbacks should not be confused with backups. A software rollback is the process of reverting an application to a previous stable version when a new update causes issues. It is crucial for maintaining system stability, minimizing downtime, and ensuring that any disruptive changes can be quickly undone to preserve user experience. Virtual Modeling: Virtual modeling encompasses the creation of digital models or simulations of real-world objects, processes, or systems. These models can be used for a variety of purposes, including visualization, analysis, simulation and testing. Using Virtual Modeling in Testing: Virtual materials testing enables us to simulate these tests within a few hours, if not minutes, using computer models. And better yet, researchers can repeat the same test or change test conditions with a click of the mouse, and sometimes the process can even be automated. Using Computer Models and Virtual Testing: Computer Models and Virtual Testing are nothing more than tools which are used to build things more efficiently, economically, eliminate errors and costly mistakes. It also speeds up the execution of building things. Actually, such tools can be the decisive factor between a project that is doable or out of reach. Hollywood and moviemakers use "Computer Models and Virtual Testing" to make-believe of things such as the futuristic existence of galaxies, plants, buildings, war equipment and spaceships as shown in the "Star Wars" movies. So our job as analysts is to simplify "Computer Models and Virtual Testing" so the common man would understand and see the benefits of such tools. 
Image #20 Image #20 presents a structured way of handling the following hackers' attacks: Outsource Testing: Outsource testing, also known as software testing outsourcing, is the practice of hiring a third-party company or individual to perform software testing tasks. This means that a company contracts out its testing activities to external specialists instead of relying on its own internal team. Outsourcing testing can be done for various reasons, such as accessing specialized skills, reducing costs, and freeing up internal resources. Image #20 presents virtual testing, Rollback and outsource testing. In Image #20, we are using virtual production servers, rollback servers, and virtual IP addresses to build a virtual buffer which would protect the internal system for any hackers' attack. Attackers would be able to access these virtual servers and would be able to access the internal system. The same thing would be used when using outsource virtual testing. Compression and Encryption: Compression: What is software compression? Software compression refers to the process of using software to reduce the size of digital files or data, often to save storage space or improve transmission speeds. It involves various algorithms that identify and remove redundancies or unnecessary information from the data, making it more compact without necessarily losing quality. Types: Lossy and Lossless compression Lossy compression: Reduces file size by discarding some information that is considered less important or not essential for the final product. This can lead to some quality loss, but the size reduction is often significant. Lossy compression is a type of data compression that reduces file size by permanently discarding some information. This discarded information can be redundant or less important details that don't significantly affect the perceived quality of the content, according to Adobe. As a result, the compressed data is smaller, but the original data cannot be perfectly restored, and some quality may be lost, according to TechTarget. Compression Ratio: Lossy compression can achieve much higher ratios, potentially 50:1 or more, but at the cost of some data (and quality) loss, according to Wikipedia. Lossless compression: Reduces file size without losing any data. The original file can be fully reconstructed. Lossless compression is a method of compressing data that allows the original data to be perfectly reconstructed from the compressed version, without any loss of information. This is achieved by identifying and removing redundancies in the data, like repeating patterns or metadata, and then encoding the data using algorithms that can reverse the process. File Size and Encoding Time: Higher compression levels lead to smaller file sizes, but they also require more processing power and time to encode and decode. Best Lossless Compression Ratio: The "best" lossless compression ratio depends on the type of data and the specific compression algorithm used. Generally, lossless compression can achieve compression ratios of 2:1 to 10:1, but it's unlikely to drastically reduce file sizes like lossy compression methods. Text-based files can often achieve higher ratios, while already compressed files like JPEGs or MP3s will see less reduction. Cons of Lossless Compression: • Larger File Sizes • Slower Loading/Transfer • Limited Compression • Not Web-Friendly Lossy vs. Lossless: Lossy compression (like JPEG or MP3) can achieve much higher compression ratios (e.g., 50:1 or higher) at the cost of some quality. Lossless compression prioritizes data preservation, limiting the compression achieved. Encryption: According to Google: At its most basic level, encryption is the process of protecting information or data by using mathematical models to scramble it in such a way that only the parties who have the key to unscramble it can access it. That process can range from very simple to very complex, and mathematicians and computer scientists have invented specific forms of encryption that are used to protect information and data that consumers and businesses rely on every day. Encryption and compression are distinct processes, both aimed at handling data differently. Encryption secures data by converting it into an unreadable format, protecting it from unauthorized access, while compression reduces data size for efficient storage and transmission. Compression and Encryption as a Cybersecurity Tool: Compression and encryption are powerful cybersecurity tools when used in combination. Compression reduces file size for efficient storage and transmission, while encryption protects data from unauthorized access by encoding it. While compression can offer performance benefits and reduced storage costs, encryption is crucial for protecting sensitive information from breaches and attacks. Issues with Compression and Encryption: Looking at the Google definitions and the performance of the compression and encryption, we can summarize them as follows: 1. Loss of data 2. Performance speed 3. Size of out the output 4. The undo (decompression and decryption) 5. Executable code For executable code, what we mean is when you have parallel processing where one or more computer CPUs can share executable code or fetched data in Cache, memory or shared memory. It can be used when cloning a running program with all its memory contents including the running Operating Systems. We will present this concept later in this compression-encryption section. Our Compression: We do need to protect our trade secrets therefore; we will state that our compression ratio is 10:1. Compression ratio is typically expressed as a ratio or percentage of compressed size to original size. For example, a 10:1 ratio means the compressed data is one-tenth the size of the original data. The higher the ratio, the more effective the compression. Compression ratio = original size / compressed size The speed of our Compression: Compression used currently in the market has a number of issues including the higher the lossless, the larger the compressed data and higher the processing time or slow processing speed (it may not be practical to use): Time + Size Our compression is as fast as the running CPU without any data loss and not even one bit of data. It is 100% accurate. To achieve such speed, it has to have its own chip (CPU, Cache, memory, and big data bus). Ideally, it should be one of the motherboard components where it accesses core memory, Cache and CPUs (Multicore system). Our Encryption: In a nutshell, we would be using any reversal mathematical formula and there is an infinite number of formulas and algorithms that we can use. Practical Applications of Our Compression and Encryption: For our non-technical audience, we need to present a number of technical computer concepts. The following concepts are our approach of using compression-encryption to help create system which would support AI computing and other system such fighter jets or Oil and Gas Security: Running System: 
Image #21 Looking at Image #21, it has the following specs for two separate computer system:
In Image #21, we are presenting two personal computers. We are showing the core memory content of each computer. In a nutshell, all programs including the operation system are running memory. CPU executes each process (commands-programs). These programs communicating with peripheral (IO devices). Turning off any of these computers would results in the total loss of every virtual object loaded in memory. Heap: Heap is a region in the computer main memory used for dynamic memory allocation. Memory Heap is a location in memory where memory may be allocated at random access. Most programs including the operating system use Heap to dynamically get extra memory. Image #21 presents the actual or physical system of a running computer system. The system is composed of: CPU Resources Core Memory: Operating System Heap One of more running programs or processes Cloning: In computing, system cloning (also known as disk cloning or cloning software) refers to the process of creating an exact replica of a computer's entire storage drive (like a hard drive or SSD). This replica includes the operating system, applications, settings, data, and even the hidden files that are part of the system. The cloned image can then be used to restore the system to a previous state, replace a faulty drive, or quickly set up multiple computers with the same configuration. System Placement and System Cloning: When setting up multiple computers with the same software and settings, cloning would streamline the process by creating an identical image that can be copied to each machine. Creates An Exact Copy: Unlike simple file copying, cloning duplicates everything on the drive, including the file system, partitions, and even the boot sector. Shared Memory Contents: In computer science, shared memory is memory that may be simultaneously accessed by multiple programs with an intent to provide communication among them or avoid redundant copies. Shared Executable Code: A shared library is a library that contains executable code designed to be used by multiple computer programs or other libraries at runtime, with only one copy of that code in memory, shared by all programs using the code. Software Remote Support: Software remote support is the ability to access, control, and manage a computer or device from a remote location. This allows technicians to troubleshoot, resolve issues, and provide support without physically being present. Remote support is typically facilitated by dedicated software that enables secure and often encrypted connections. Using Compression and Encryption for Remote Support: Both Compression and Encryption to used to reduce the size of the transferred byte or software and encrypt it for security. Multiple Ground Supporting Executable Processes: Remote computing refers to using a computer's processing power and resources from a location different from where the computer is physically located. This is often achieved through network connections, allowing users to access and interact with a remote computer as if they were sitting at the keyboard. Remote processing can involve a variety of activities, including accessing files, running applications, and managing systems. What is remote processing in computer? Remote processing decreases the amount of data that must be transferred between the client and the server. If files reside on the same server on which processing occurs, network traffic is reduced. Only the final result of the processing is returned to the client machine. 
Remote Processing - Image #22 Image #21, it presents simple remote processing, where there is more than one computer processing system communicating with the fighter jet. Added Remote Power: Remote processing can be used by fighter jets, where the fighter jet computer can use a number of ground computers system and send wireless code to be executed in jet's computer. By zipping the executable code to one tenth (1/10) of the actual size. The zipped code would be unzipped in fraction of millisecond and then run, that will boost the fighter jets computing power with all the ground computing support it can get. The fighter jet computer would be designed to run a number ground computers executable code within the fighter jet computing systems. Note: Real-time processing for fighter jet is very critical, since the jet may have a window of less 30 seconds before real enemy deadly engagement. The jet computer must perform a number computing processes (navigation, other rival forces, enemy position and movements, wind speed and direction, ... etc.) and maneuvering before real enemy deadly engagement. The ground and Seattleite support would make a big difference in the jet session success. Building Futuristic Data and AI Development Centers: Introduction: Data and Development Centers are critical to any company, country-governments, culture, social media, ... etc. These centers come with a hefty price and their running and maintenance are even heftier. Issues with Data Centers: Data centers face numerous challenges, including energy consumption, environmental impact, cybersecurity threats, and physical infrastructure issues like power outages and cooling failures. Other significant concerns include scalability, sustainability, and rising operational costs. Issues with Development Center: Development centers face a variety of challenges, including issues with communication, cultural differences, time zones, and geopolitical instability. These challenges can affect the effectiveness of offshore development teams and the overall success of projects. Issues with AI Development Center: AI data centers face a number of significant challenges and issues. These are categorized as: • High Energy Consumption • Water Usage • High Capital Expenditure • Operational Costs • Workforce and Skills Gap • Demand for Specialized Talent • Labor Shortages How Governments view Data Centers: Governments view data centers as critical infrastructure for a variety of reasons, including their role in storing and processing essential government data, supporting public services, and ensuring national security. Data centers are also seen as important for economic development, attracting investment, and fostering innovation. Furthermore, governments are increasingly concerned about the environmental impact and sustainability of these facilities. Issues with Data Centers: Searching the internet for Data Centers issues, we literally ran into over 50 issues if not more. We summarize all the issues into the following: 1. Cooling and Energy Efficiency 2. Dwindling power availability 3. Need To Optimize Software and Hardware 4. Increased Complexity of Hybrid and Multi-Cloud Environments 5. Skilled Workforce Shortage 6. Security and Cyber Threats 7. Intelligent Hardware Security 8. Staffing shortages 9. Expensive outages 10. Facility constraints We as IT professionals, we can categorize the listed issues into: • Vertical • Horizontal Both Vertical and Horizontal Scaling is not fully understood by the IT community: • Vertical means each Unit is modified to have more power, functionality, production, flexibility, ... etc. • Horizontal means add more units. Vertical - Internal Structure: 1. Cooling and Energy Efficiency 2. Skilled Workforce Shortage 3. Security and Cyber Threats 4. Intelligent Hardware Security 5. Staffing shortages 6. Need To Optimize Software and Hardware 7. Increased Complexity of Hybrid and Multi-Cloud Environments Horizontal - External Structure: 1. Expensive outages 2. Facility constraints 3. Dwindling power availability Our Strategy: Management + Energy + Security + Performance + DevOps + AI + Storge + Maintenance + Services + Communication + Automated Updates + Optimum Size Our strategy is building a solid automated AI support foundation. As for the cost, our focus would be reducing the energy and environment impact. As for the future, we need to revisit our cost, performance, maintenance and updates. The following are Points of Interests: Energy: 1. Processing Servers - produce Heat 2. Energy consumption - to run data centers 3. Use solar panels for energy 4. Use windmill for energy 5. Self-sufficient Energy production 6. Backup Diesel Generators 7. Cooling 8. Using water cooling system 9. Locations 10. Distributed system 11. New Building structure for better ventilation 12. Power consumption and environment impact 13. Water purification plants How to Generate Electricity Using Sees or Ocean: Electricity can be generated from the sea by harnessing various forms of ocean energy, including tides, waves, currents, and thermal differences between warm surface water and cold deep water. This can be done through devices like tidal turbines, wave energy converters, and ocean thermal energy conversion (OTEC) systems. Performance - DevOps Support: 1. High-performance environmental systems 2. Better design of servers 3. Compression-encryption reduce data size and security 4. Data compression and encryption 5. Using text files instead of database 6. New software approaches 7. Bare-Metal server restructure 8. Server structure - CPU and Core processes 9. Internal Structure and raking servers and equipment AI: 1. AI processes 2. AI for building security 3. Robots for physical work replacing human 4. AI and Automation of management - running the place 5. Controlling and maintaining AI 6. Physical and Cyber Security using AI 7. Bare-metal structure to meet AI processing demands 8. Keeping and maintaining the dynamic AI processing 9. Using and implementing market AI products 10. AI Management System - Managing AI Management and Tracking: 1. System and Products management processes and tracking with AI support 2. Updates and storing management Maintenance: 1. Software and hardware automated AI processes 2. Building (cooling, power, ... etc.) maintenance with AI support 3. Using Robots 4. Retraining of staff Security: 1. Monitoring 2. Using Robots 3. Cybersecurity Communication: 1. Satellite 2. Ground wiring 3. Connectivity and Network Latency Issues 4. Virtual Edge Computing with Machine Learning Services: 1. Specialty servers based on the business and demands 2. Data Storage 3. Continuous updating of all the services 4. Virtual Edge Computing with Machine Learning Optimum Size: What is the size of a typical data center? Average onsite data center: is between 2,000 and 5,000 servers. It's square footage: could vary from between 20,000 square feet and 100,000 square feet. Energy draw: Around 100 MW. In a nutshell, the optimum size is a balance of: 1. Power supply 2. Performance 3. Cost 4. Scalability 5. Sustainability We believe the optimum size should be based on: 1. Cooling System 2. Self-sufficient power generation 3. Water purification plant using AI data and development center head production Distributed Network of AI Data Centers and Virtual Edge Computing with Machine Learning: A distributed network of AI data centers refers to a system where AI workloads are processed and data is stored across multiple geographically dispersed data centers, rather than relying on a single centralized facility. Benefits of a distributed AI data center network: 1. Reduced Latency 2. Increased Resilience 3. Improved Scalability 4. Enhanced Data Sovereignty 5. Optimized Cost As for Virtual Edge Computing with Machine Learning, which would help in remote support of businesses with their own onsite facilities. For example, a bank branch would have its own Virtual Edge Computing with Machine Learning as an added processing and updating processing power and update support. Note: We are not sure if our proposed Distributed Network of AI Data Centers and Virtual Edge Computing with Machine Learning would be able to replace GoldenGate services??? Government Involvement: According to Google search: Government involvement with AI data centers encompasses a range of activities, including policy setting, funding, regulation, and even direct development, all aimed at fostering AI innovation, ensuring national security, and promoting economic growth. In summary: Government involvement in AI data centers is multifaceted, ranging from establishing broad policy frameworks and providing financial support, to regulating AI applications and even engaging in direct development and deployment. This involvement aims to foster responsible innovation, address potential risks, and ensure that the benefits of AI are widely shared. Building-Development-Testing Models: Building-Development-Testing Models have very much the same processes, but specific project must have all requirement goals and scope are done for such project. Our Building-Development-Testing Model processes are the following:
Businesses Objects: xxxxxxxxxxxxxxxxxxx Our Solutions to Big Businesses, Medium and Small Size Businesses: ccccccccccccccccccccccc Return on Investment: vvvvvvvvvvvvvvvvvvvvvvvvv |
|---|