| Executive Summary | Our Regenerative Medicine Umbrella |
|---|
|
|
Our Regenerative Medicine Umbrella©
|
|---|
|
Our Regenerative Medicine Umbrella
Introduction: What is Regenerative Medicine and what are we trying to accomplish? In a nutshell, Regenerative Medicine is a new field with the focus on developing and applying new treatments to heal tissues and organs and restore function lost due to diseases, damages, defects or aging. We believe the following are the top major Regenerative Medicine associated fields:
As End-2-End architects-managers-visionaries-entrepreneurs, we are interested in leading Regenerative Medicine efforts and help take Regenerative Medicine into a different level. Therefore, our attempt in this page is to present the page topics with the goal of keeping Regenerative Medicine medical professionals and Information Technologies (IT) professionals on the same page. Creativity Without Resources nor Support: Our audience must understand that what we are presenting in this page is: Our Architect-Design (Our System on Paper) and we do not have a Running Product Our Regenerative Medicine Umbrella is what we envision the future of Regenerative Medicine would be. The goal is helping all Regenerative Medicine associated fields team up for the good of all. This page represents how we translated our vision into a documented architect-design without any resources nor support. With the right resources and support, we can make our architect-design a successful and a rewardable reality. United States Government Accountability Office (GAO) Report: United States Government Accountability Office (GAO) Report to Congressional Committees on July 2023 on the: TECHNOLOGY ASSESSMENT Regenerative Medicine Therapeutic Applications, Challenges, and Policy Options What GAO found: Regenerative medicine offers the hope of being able to restore or replace cell, tissue, and organ functions affected by disease, injury, or aging. This may eventually help manage or cure many conditions that are currently considered chronic, untreatable, or terminal. GAO identified many challenges that may affect the development and use of regenerative medicine technologies and therapies including: • Challenges related to standardization • Challenges related to regulation • Challenges related to manufacturing How big is the regenerative medicine market in 2022? The global regenerative medicine market size was estimated at USD 55.04 billion in 2022 and is expected to reach USD 65.08 billion in 2023. Our Answer to GAO: 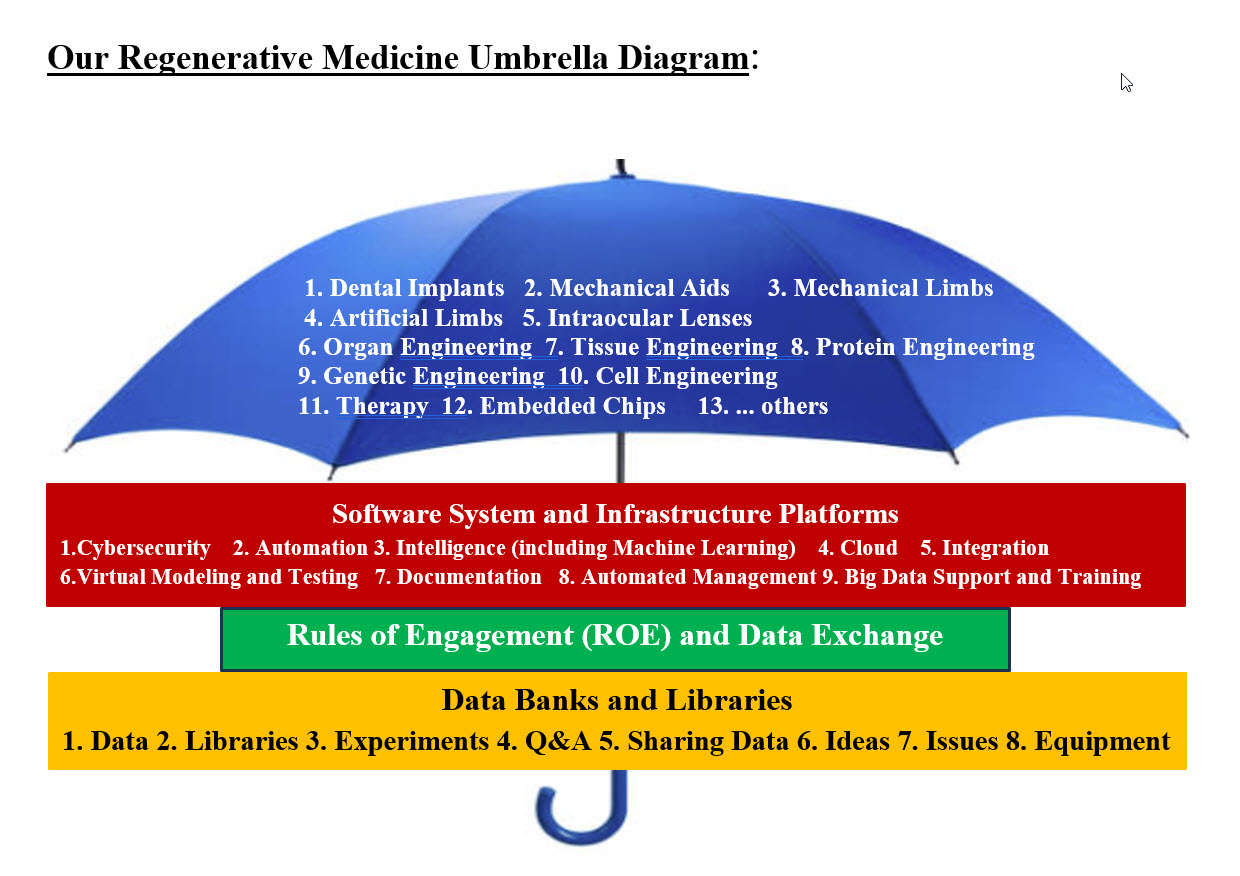
Image - Regenerative Medicine Umbrella Diagram Regenerative Medicine Umbrella Diagram Image represents our vision of Our Regenerative Medicine Umbrella components. Each of the Regenerative Medicine associated field or a group of associated fields can develop their own unique Software System and Infrastructure Platform. These platforms would be serviced by Data Banks and Libraries with the help of Rules of Engagement (ROE) and Data Exchange Services. All their cooperative efforts would: 1. Eliminate working-in-vacuum to save effort and time 2. Help one another in advancing their work and achieving their goals 3. Save the repeated efforts and errors 4. Share documentation, publications, experiment and equipment 6. Use the Rules of Engagement (ROE) and Data Exchange Services to cooperate 7. Protect each pattens, copyrights, data, resources and trade names 9. Save efforts, resources and funds 9. Set the future cooperative roads and exchanges What we just mentioned would answer our findings: Our Regenerative Medicine Umbrella has the goal of helping Regenerative Medicine technologies and therapies cooperate and team up for the good of all. This means that our Regenerative Medicine Umbrella would help Regenerative Medicine meet the current and future challenges. We found and recognized the following:
Our Regenerative Medicine Umbrella is our attempt to answer all the challenges including GAO findings. This page is our documented map for building our Regenerative Medicine Umbrella for all Regenerative Medicine associated fields. This page is designed to answer IT professional, and medical professionals and non-technical audience. Our System on Paper: We are analysts, architects, designers and visionaries who take an idea and we build a "System on Paper". We also help in development and making what is on paper a reality, plus test the system to meet the expectation. The following is the content of this page and readers are free to jump to what interests them: • Regenerative Medicine Quick Definitions • Our Goals • Regenerative Medicine Success • Our "Regenerative Medicine Umbrella" • Machine Learning Integration Services • Structure and Management • Data Exchange • Rules of Engagement • Platforms • Dental Implants • Stem Cells • Data Banks and Libraries Components Support - Find Common Ground Our System on Paper Provides: Regardless the type of user of our System on Paper or Regenerative Medicine Umbrella, our system would help with: • Sellers sell their products, approaches, researches, training, ..etc • Buyers find what would they need • Researchers get their technologies, data, support, training, documentation, ..etc • Governments regulate their targeted system • Funders and investors analyze and make decisions Our Regenerative Medicine Umbrella is an intelligent system with Structure, Management, Platforms, Framework, Software, Cybersecurity, Data Exchange, Rules of Engagement, Machine Learning, DevOps, Integration, Data Banks and Libraries, Training, and Documentation. Regenerative Medicine Quick Definitions: What is Regenerative Medicine? Searching the internet we found the following definitions:
Tissue Engineering: The goal of tissue engineering is to assemble functional constructs that restore, maintain, or improve damaged tissues or whole organs. Artificial skin and cartilage are examples of engineered tissues that have been approved by the FDA; however, currently they have limited use in human patients. The terms "tissue engineering" and "regenerative medicine" have become largely interchangeable, as the field hopes to focus on cures instead of treatments for complex, often chronic, diseases. Organoids: Organoids are tiny, self-organized three-dimensional tissue cultures that are derived from stem cells. Such cultures can be crafted to replicate much of the complexity of an organ, or to express selected aspects of it like producing only certain types of cells. Organoids grow from stem cells that can divide indefinitely and produce different types of cells as part of their progeny. Scientists have learned how to create the right environment for the stem cells so they can follow their own genetic instructions to self-organize, forming tiny structures that resemble miniature organs composed of many cell types. Organoids can range in size from less than the width of a hair to five millimeters. Our Goals: Our Regenerative Medicine Umbrella is built for medical professionals. The main job of our umbrella is to help these professional by bringing supportive tools such as software system, infrastructure, Cybersecurity, automation, intelligence (including Machine Learning), cloud, integration, virtual modeling and testing, documentation and automated management, Big Data support and training. These supporting tools would be running in the background. All these tools would not interfere with these professionals day to day job, but an added aid or helper to make their task more productive, sharing, intelligent and documented. For example, if any team decides to use Stem Cells to reconstruct tissue in diseased or damaged cells, then our Machine Learning tools would perform the footwork by searching and analyzing the Banks-Libraries (intelligent Data Services) and ML Integration Services. These ML tools would build data matrices which would be used to build reports and documentation. These reports and documentation can be understood and use by Regenerative Medicine medical professionals. In short, our ML would cut the research and analysis times into seconds if not milliseconds. Cybersecurity tools would protect the work of these medical professionals for hackers and any sabotage. Regenerative Medicine Success: For Regenerative Medicine to succeed and move into the next level, there must be a team effort of all Regenerative Medicine Associated fields, businesses and manufactures to work on cooperative mythologies, researches and manufacturing. Nothing should be done in a vacuum. It seems that most if not all the researches, testing and treatment are running solo and no serious data sharing. We recommend to do the following:
All of the above must be cyber secured. Our Banks and Libraries Would Be Providing: 1. Data - all the categories' data - Big Data 2. Libraries (Processes and Procedures - all the existing and virtual processes and procedures) 3. Experiment 4. Q&A - categorized listing questions and answers for different discipline to share or post 5. Sharing Data - which data are used by whom, why and how 6. Ideas - for participants to verbalize their crazy ideas and thoughts 7. Issues - list of issues resolved and not resolved 8. Equipment used with their rating Our "Regenerative Medicine Umbrella": We are software engineers and not medical professionals, therefore we are teaming up with these medical professionals to build Regenerative Medicine Umbrella with structure and management systems. We are building integration, communication, engagement processes and protocols. We are harnessing critical technologies such as data banks, cloud, virtualization, integration, intelligence, virtual modeling, virtual testing and Machine Learning. We would build tools including Machine Learning to reduce the tedious detailed tasks and provide decision-making support which would running in the background. Big Data analysis, searches, storage and support would be part of the Data Banks and Libraries support services. 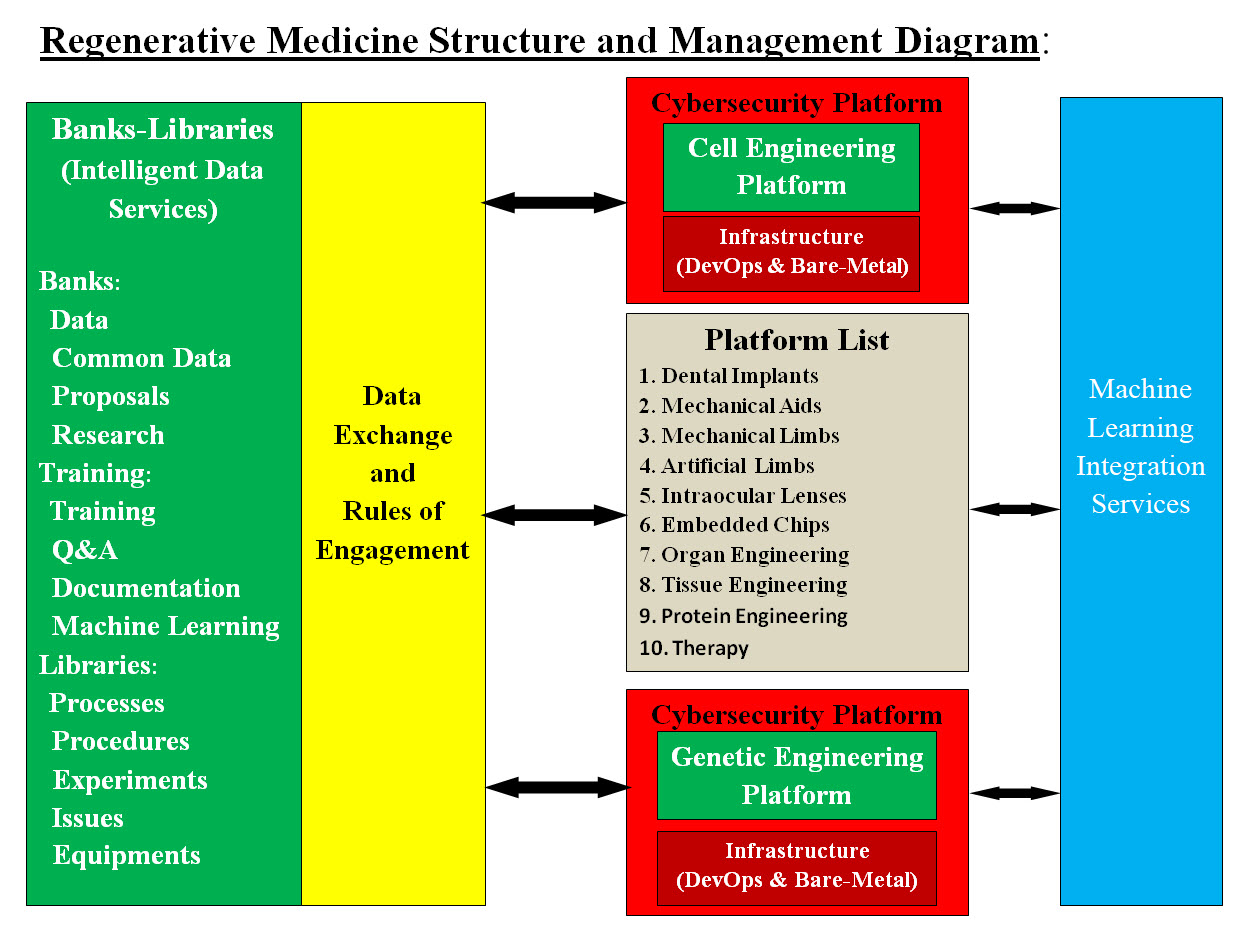
Image #1 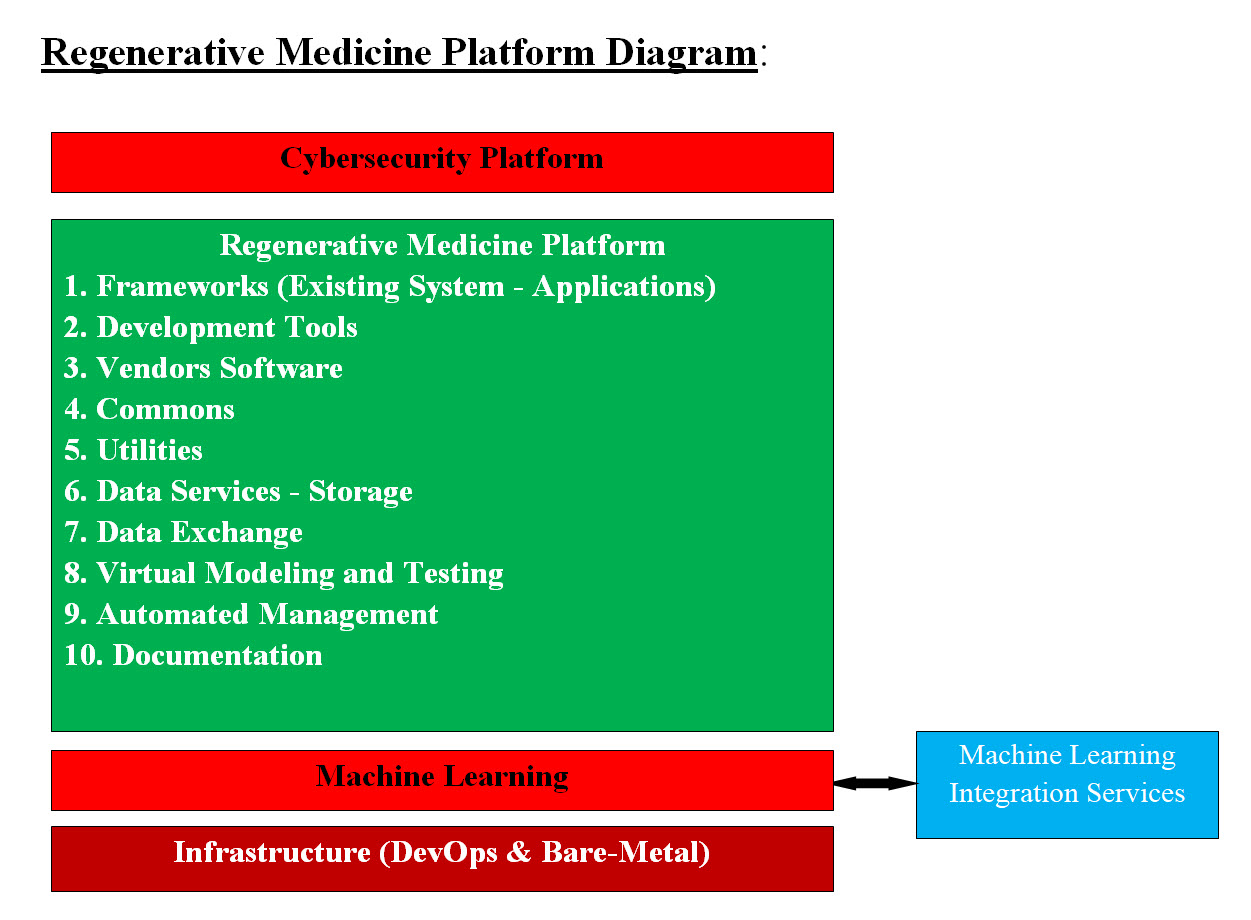
Image #2 Images #1 and #2 represent a rough draft of our proposal for the overall Regenerative Medicine Umbrella Structure, Platforms, Frameworks (Existing System - Applications), Development Tools, Vendors Software, Commons, Utilities, Data Services - Storage, Data Exchange, Virtual Modeling and Testing, Automated Management, and Documentation. Cybersecurity and DevOps would be also added platforms. Platform List: The following list is based on our internet research and we are open to any modifications, suggestions and corrections: 1. Dental Implants 2. Mechanical Aids 3. Mechanical Limbs 4. Artificial Limbs 5. Intraocular Lenses 6. Therapy 7. Embedded Chips 8. Organ Engineering 9. Tissue Engineering 10. Protein Engineering 11. Genetic Engineering 12. Cell Engineering 13. ... others Machine Learning Integration Services: To make life easy, our Machine Learning (ML) would be running in the background of any software or system. ML would be the added intelligence and automation to these systems. ML would perform all the background support plus most of the tedious analysis and/or calculations. ML would build data matrices to structure the details and history of the ML tasks and plus communication tools. These matrices can be used by other ML, therefore our Machine Learning Integration Services would help with all ML Tools in communicating and sharing data, analysis, decisions, errors, duplicates data and effort, ..etc. What Is Our Machine Learning (ML) and What Does ML Do? To take the vagueness and the mystery out what our ML is and what it does? Our ML is composed of Independent Running Engines, Data Matrices and Control. Independent Running Engines: A ML Engine is a software or an application which performs one job. For example, in Cybersecurity, the Alert Engine performs by start alerting clients, vendors, employees, every parties involved in the case there is a security issue. Producers Engines and Consumers Engines: Producers Engines create the data matrices for Consumers Engines or any system components which can use to perform their tasks. Data Matrices: Data Matrices are Spine Cord of our ML, where these matrices are the communication and the signals which coordinate the ML performance. ML Management Engines - Control: Management is the core of any system and our ML is no exception, the management Control is also composed of Engines and a Leading Control Engine. Table of Engines: Possible: more than one engine for the same functionality. A this point in analysis, design and architecting stages, we may need to modify a lot items including engines. Therefore, there could be more than one engine performing the same task based on different use cases or scenarios. For example, Alert may require more than one type of alert.
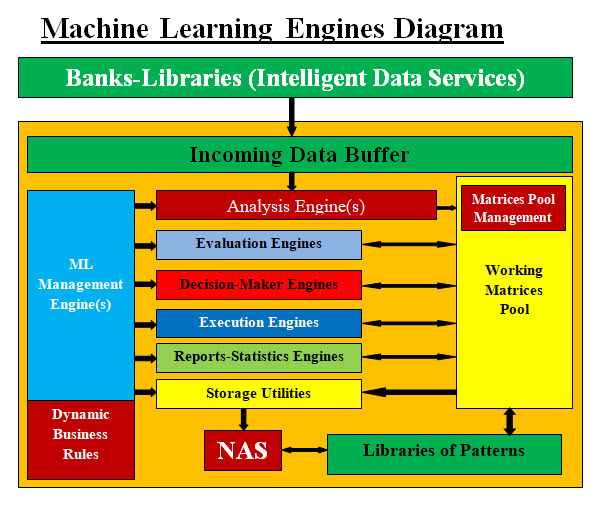
Image #3 Engines Execution: Image #3 presents a rough draft of our ML would support any Regenerative Medicine team by performing all the footwork of tedious details and help with the decision making. Structure and Management: The main goal of Regenerative Medicine Umbrella is build a solid structure with intelligent components which can be easy integrated into other associated fields. Managing these intelligent components would be done both with automation of management processes and procedures plus using human intelligent management teams to run and manage any platform as well as the interfaces. Our attempt in this page is to present our analysis-architect-design of our "Regenerative Medicine Umbrella" which would service as platforms, frameworks and testing with software tools and Machine Learning support. For example, we would build a data bank(s) with data from all the associated fields (relevant or irrelevant), processes, procedures and experiment libraries, trainings and data banks for any other supporting data. Customized Machine Learning (ML) tools would be built for each associated field. ML tools would be doing the researchers' footwork, the analysis, and build supporting decision matrices for research teams to use in their work and decision making. These matrices can be integrated into other associated fields teams ML to help in sharing and adding different approaches and viewpoints. The platforms, frameworks and testing would be composed of Intelligent customized software tools which are built for each research team to perform their tasks. The platforms, frameworks and testing can be integrated into any existing system which the associated fields teams are using. We also would be proving the automated management system for Regenerative Medicine Umbrella teams to use. Infrastructure (DevOps and Bare-Metal): Regenerative Medicine medical professionals would be working on their own independent network(s) or part of an existing network(s). For these medical teams to perform their tasks independently or with other teams, they would require to have their own platforms, frameworks, virtual modeling server and testing servers. These teams would have to require the infrastructure support. Such support would require working with infrastructure engineers to create for them their platforms and frameworks to work on. Such requirements take months and lot of back-and-forth communication and effort. Our Intelligent Automated Virtual DevOps Editors: What are our Intelligent Automated Virtual DevOps Editors? What is a software editor? In general, an editor refers to any program capable of editing files. Good examples are image editors, such as Adobe Photoshop, and sound editors, such as Audacity or for text editor such as Microsoft Word or WordPerfect. What is Our Intelligent DevOps Editor(s)? How can we build such an Intelligent DevOps Editor? The key feature of our DevOps Editor is Intelligence. Intelligence here is not Artificial Intelligence, but developing intelligence software. We communicate with gurus of development and infrastructure, and try to pick their brains. We build a number of processes and tasks mimicking these gurus handling and approaches. We rearrange these processes and tasks in order to be able to translated them to code and a running software. With the computer processing speed, thousands if not hundreds of thousands of processes and options can be performed on the input data in seconds. These processes add to intelligence of our editor. DevOps Editor GUI Interface To make our Intelligent DevOps Editor concept easier to understand, we may need to present a picture. We are presenting a markup or a running prototype with a GUI interface for our audience to examine. Our Intelligent DevOps Editors We have architected-designed and created prototypes for six DevOps Editors. We recommend that our viewers visit the following links and checkout each editor. We are open for feedbacks and comments ( Sam@SamEldin.com ): Data Center Specification Editor Data Center Specification Network Editor Data Center Specification Migration Editor Data Center Migration Builder Data Center's Testing - Tracking - Validation Editor Intelligent DevOps Editor - "Turn Key" Data Exchange: What is Data Exchange (DEX)?: Data exchange helps data providers and data consumers to connect and exchange data in a seamless and secure manner. These exchanges simplify the acquisition and integration of data. What is Web Service? A web service is any piece of software that makes itself available over the internet and uses a standardized XML messaging system. XML is used to encode all communications to a web service. For example, a client invokes a web service by sending an XML message, then waits for a corresponding XML response. Issues with Data Exchange: Data Exchange can be a bottleneck due to data complexity, data transformation complexity, data format, data security, data set size, communication protocol, frequency of data update and data Streaming. Our Approaches To Data Exchange: We are proposing our two intelligent integrate-able approaches as follows: • Intelligent Upgrade of Web Services • Machine Learning Matrices Intelligent Upgrade of Web Services: Intelligent Upgrade of Web Services (DEX) is a set of software tools which help the communication and the exchange of data. The data exchange is not limited to XML, but it encompasses the following data structures: • Java Data Access Object (DAO) • Java Set • XML • JSON • Text • Message Queues • C-Tables • DataTable • Misc - We are also open to other data format DEX also provides data exchange parsers and convertors to resolve any data exchange issues and communication. DEX should be a virtual service running on a virtual server with parsers and convertors to handle any data exchange parsing and formatting. Our DEX's convertors build XML format with No Schema regardless of its sizes and complexities. What are goals of building and standardizing DEX? Building and standardizing DEX would pave the road for intelligent and faster communication media, the same way web services did for the IT community. Excel Sheet-DAO-XML Data Exchange Seed Framework The following link is our Excel Sheet-DAO-XML Data Exchange Seed Framework. Excel Sheet-DAO-XML Data Exchange Seed Framework Machine Learning Matrices: We recommend that the readers check our Sam's Machine Learning Analysis, Data Structure-Architect - see the following link: Excel Sheet-DAO-XML Data Exchange Seed Framework Our ML consists mainly from Engines: • Preparation-Processes-Engines (Search Pattern Builder or Engine) • Scanning Engines • Work engines (Sort, Tracking, Evaluation, Decision-makers, Execution and Lesson Learned). • Storage and Backup Engines These components produce and consumes data stored in Matrices. Data Exchange and our Machine Learning Matrices: In a nutshell. our ML Matrices approach is to use matrices for the data exchange. This would simplify, standardize, speed data transmission and data processing plus rollback would be even easier. Communication Protocol: As for Communication Protocol, we are open to any suggestion and best practices. Plus we do have our own Compression-Encryption Cyber Security Chip. Compression-Encryption Cyber Security Chip Rules of Engagement(ROE) For Our Regenerative Medicine Umbrella: What are Rules of Engagement (for Our Regenerative Medicine Umbrella)? Rules of engagement help set the expectations and define clear goals on how research institutions, medical institutions, countries, courts, manufacturing, companies and all the parties involved are going to go about getting their work accomplished. Task at Hand (We are Pioneers): We are pioneers in the field of structuring and automating ROE. Our task is too big if not gigantic. In a nutshell, there are Nemours possibilities of conflicts, but our goal of taking ROE into the next level is worth taking all the necessary steps to bring on agreements. What we are presenting is not set in stone, but open for changes. Our Goals: As we mentioned before we are pioneers and our goals are as follows: • Implementing Our Plans and Strategies • Structuring and Automating Rules of Engagement • Handling Risks of Rules of Engagement • Helping Management Deals with Rules of Engagement Note: We need to address the importance and pros and cons of rules of engagement:
ROE Vocabulary: We need to defines some of the basic terms for ROE Vocabulary and the following table is a quick list:
The following is a brief definitions of the terms listed in the ROE Vocabulary Table. Terms Definition (According to the internet definition): Privacy: Privacy has been defined as a state of being free from the observation or disturbance of other people. Secrecy: Secrecy has been defined as the intentional concealment of information from others. Discretionary: Left to individual choice or judgment - exercised at one's own discretion. Permission: In short, it is the right to use but not own. Trademark: A trademark can be any word, phrase, symbol, design, or a combination of these things that identifies the company's goods or services. This is how customers recognize the company's business in the marketplace and distinguish its business from the competitors. The word "trademark" can refer to both trademarks and service marks. Trademark Protection: Trademark protection refers to safeguarding intellectual property rights to protect a trademark from counterfeiting and infringement. A trademark is an established or legally registered mark that identifies a manufacturer's unique goods and services. Copyrights: Copyright refers to the legal right of the owner of intellectual property. In simpler terms, copyright is the right to copy. This means that the original creators of products and anyone they give authorization to are the only ones with the exclusive right to reproduce the work. Patents: A patent is an exclusive right granted for an invention, which is a product or a process that provides, in general, a new way of doing something, or offers a new technical solution to a problem. What is the difference between a patent and a trademark and a copyright? A patent protects new inventions, processes, or scientific creations, a trademark protects brands, logos, and slogans, and a copyright protects original works of authorship. Confidentiality: Confidentiality is a set of rules that limits access or places restrictions on the use of certain types of information. It is usually executed through confidentiality agreements and policies. What is confidentiality in ethics? Confidentiality refers to the duty to protect privileged information and to share entrusted information responsibly. It stems from the notion that a person's wishes, decisions, and personal information should be treated with respect. The duty of confidentiality can apply to individuals, organizations, and institutions. Confidentiality Agreements: A confidentiality agreement is a contract between at least two parties that describes information that the parties must share with each other, but that they also need to prevent other parties from accessing. It is also known as a nondisclosure agreement. Drafting Considerations: Your confidentiality agreement should clearly state what information is being shared, what obligations each party has concerning that information, how long those obligations last, what, if any, future obligations the parties have concerning the information, and what remedies are available if there is a breach of the agreement. Accountability: Accountability is the acceptance of responsibility for one's own actions. It implies a willingness to be transparent, allowing others to observe and evaluate one's performance. Accountability, in terms of ethics and governance, is equated with answerability, blameworthiness, liability, and the expectation of account-giving. As in an aspect of governance, it has been central to discussions related to problems in the public sector, nonprofit, private, and individual contexts. Sensitive Data Handling: Sensitive data is confidential information that must be kept safe and out of reach from all outsiders unless they have permission to access it. Sensitive data, or special category data, according to GDPR is any data that reveals a subject's information. Sensitive data examples: Racial or ethnic origin. Political beliefs. Religious beliefs. Languages and Translations: There are many challenges that need to be considered when translating to any language. We assuming that our Regenerative Medicine Umbrella would be built for national and international clients. We need to be able to work with any existing system regardless of nation, language, race, political and economical background. Again our ML would be a big part of such Languages and Translations tasks. Machine Learning and Translations: We are architecting-designing our ML to perform languages translation. This means that our ML would be able to build all ROE documents in any language. For example, in Image #4, our ML build all ML Docs in English and Japanese. Implementing Our Plans and Strategies: We emphasis that "We are Pioneers" in ROE and what we recommended or mentioned is not set in stone. We as IT professionals have the tasks of building structure, automate and build intelligent virtual system. We do need help and we are open to corrections, suggestions and comments. Our Plans: • Create Think-Tanks • Figure out - Brainstorm Timeline(s) • Define ROE's Abstracts • Research Issues and Conflicts • Lessons Learned and History • Brainstorm Steps, Processes and Procedures • Set Communication Structure • Automation of Templates Building • Build ML Matrices • Develop ROE Platform and Framework • Build Platform • Build Virtual Platform • Build Framework The following are our plans brief explanations. Our Plans are open to change as needed with time. Create Think-Tanks: What is the meaning of think tank? A think-tank is a group of experts who are gathered together by an organization, especially by a government, in order to consider various problems and try and work out ways to solve them. We are asking for help and we are asking to create a Think-Tank(s), but we understand that we are limited by time and resources. Figure out - Brainstorm Timeline(s): We need to brainstorm a timeline(s) with our think-tank(s) and our financial supporters. We need a number of timelines based on the size and scope what we would be building and resources available. The actual timelines would require more researches and support. Define ROE's Abstracts: What is meaning of the abstract? Use the adjective abstract for something that is not a material object or is general and not based on specific examples. Abstract is from a Latin word meaning "pulled away, detached," and the basic idea is of something detached from physical, or concrete, reality. We are IT professionals and we do not have a total picture, therefore, we need to build an ROE abstracts. Abstract Thinking gives us the freedom to put a quick picture of we believe thing should be and not necessarily the true picture. Research Issues and Conflicts: We need to know what we are dealing with and build documented forms plus the history and the lessons learned. Lessons Learned and History: Documentation of Lessons Learned and History. Brainstorm Steps, Processes and Procedures: We need to build concrete-detailed steps, processes and procedures and our Think-Tank(s) would brainstorm all the details. Set Communication Structure: There would more than one team or one group involved and communication is key. Plus we need to build communication templates and protocols. Automation of Templates Building: Templates building must be intelligent and automated. Build ML Matrices: For our Machine Learning tools to perform and communicate we need build data matrices which are the spine cord of our ML system. Develop ROE Platform and Framework: Building platforms and framework is not an option. Build Platform: A platform is a set of hardware and software components that provide a space for developers to build and run applications. Build Virtual Platform: Virtual means that a virtual system only exists in memory. Therefore, a platform can also be built as a virtual system, which has pros and cons. Build Framework: A framework is a software-only app skeleton that includes preset tools, libraries, software development kits, and other components. A Framework is virtual. What is the difference between framework and platform? The framework can be used as a tool to build an application that will run on selected or multiple platforms. The platform is the application execution environment. Our Strategies: A Plan says "Here is the steps," while a strategy says, "Here are the best steps." Our strategy(s) is to use the following any chance we can: • Build virtual system • Intelligent system • Virtual Modeling • Virtual Testing • Rapid Testing • Reusability • Documentation • Automation • Tracking • Lessons Learned The following are our Strategies brief explanations. Our Strategies are open to change as needed with time. Build Virtual System: A virtual system is nothing more than one or more software-program (including operating system) running in memory. We can automate the creating and the deletion of any virtual system and be able to create as many copies we wish to have running. This gives power and flexibility to build, run and test any system. Intelligent system: We do have the expertise to build intelligent system and our Machine Learning is one what we can build. See SamEldin.com for examples and documentation on how to build Intelligent systems. Virtual Modeling: Virtual Testing: See the following for our documented work on Virtual Modeling and Virtual Testing: https://sameldin.com/VirtualTestingPage.html https://sameldin.com/QuickAnalysisNeomProjectPage.html Rapid Testing (is a must): Rapid Software Testing (RST) is an approach to software testing that focuses on quickly testing a software product to meet short delivery timelines. We would be building intelligent RST templates and virtual RST system. Reusability: This is what we do best. Software reusability is the use of existing assets in some form within the software product development process. Documentation: See SamEldin.com for our documentation templates, processes, automation, intelligence, integration, tracking, audit trial and using ML. Automation: See SamEldin.com for our automation. Tracking: See SamEldin.com Lessons Learned: See SamEldin.com Structuring and Automating Rules of Engagement: In order for us to structure ROE, we need to understand what must be done. Let us assume that an institution working on dental implants in the country of Japan and the institution's researchers or employees (Requesters) need to see if stem cell researches or tools can be implemented in their dental implants. They would like to check a number of stem cells research, medical institutions or companies (Providers) and see how any or all these stem cells institutions can help with their dental implants. We also need to add that the dental implant people (Requesters) may want to use more than one of the stem cells Providers. Note: Since we would be dealing with possible trade secrets, sensitive data, ..etc. Both Requesters and Providers may need to rate or evaluate the institutions they are dealing with. Our ML Analysis would be architected-designed to help each party with their decisions. Our ML Matrices and Analysis: We need to present a simple representation of ML matrices and their analysis. A matrix is two-dimensional array with rows and columns. Let us say that our ML is analyzing a stem cells research institution called STEM_CELL_ABC. We would be purchasing all possible data about such institute since its creation. We also would accept data from STEM_CELL_ABC. We would create a matrix for each data category for all years since STEM_CELL_ABC existence. We would convert STEM_CELL_ABC data into numbers-digits for faster processing. These data matrices would make sense to our ML analysis based on our architecting-design of our ML. Since we are dealing with numbers-digits, our ML would be able to look for patterns, frequencies, ... any category, cross reference plus the speed of analysis would be stunningly fast. 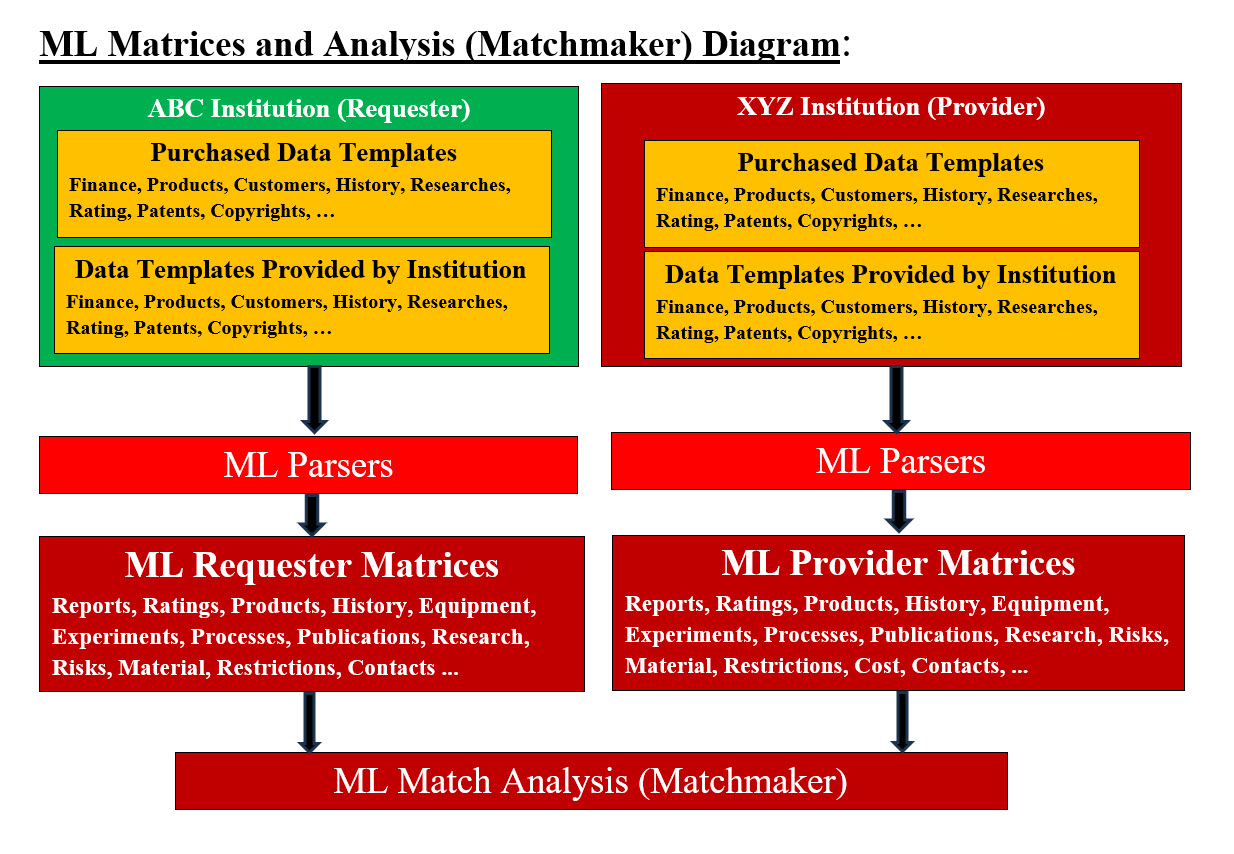
ML Matrices and Analysis (Matchmaker) Diagram Image ML Matrices and Analysis (Matchmaker) Diagram Image presents how our ML would parse and analyze the purchased data about each of the providers and requesters in the form of our ML templates for faster processing. At the same time, we would accept data from both providers and requesters in the form of our ML templates for faster processing. Our ML parsers would create the needed data matrices for further analysis and decision making. Purchased and Provided Data: We cannot accept data provided by institutions without comparing with data from other sources. Note that we would also automate the creation of data matrices. In another words, we would create data parsers which parse the purchased data and institutions provided data and build the data matrices for our ML perform all the analysis. We can use such analysis to structure our ROE. We can divide the structure into: 1. Requesters 2. Requesters ML Tools 3. Providers 4. Providers ML Tools 5. Required Request documents 6. Request Matrices Pool 7. Required Providers documents 8. Providers Matrices Pool 9. ML Integration Services Each structure can be running on its own virtual server. The goal is to automate the dialogs between Requesters and Providers and have our ML tools perform all the footwork such as the analysis, matching, best choice based on requesters criteria, documents preparation, address both Requesters and Providers concerns and answer questions. One can view our ML tools as the brokers for buying and selling services. There are ML tools for each parties involved (Requesters and Providers). The data structure for our ML would be composed of pools of requests and responds, documentation templates, applying rules and criteria and ML Integration Services. The pools are populated with ML matrices which would be the data requested for our ML to perform all ML tasks. Therefore, our ML would be the go between until there is one or more match, then the actual parties dialogs would take over the ML automated processes. The ML Integration Services is a number of applications-programs which link ML with all the data matrices. We have to address the fact that the number of Requesters and Providers can be in the tens of thousands if not more. Virtual Structure (Technical Presentation): Virtual servers would be created to perform as independent components. Each virtual server would have one component to service where each server would be secured, accessed remotely and also can be rolled back. For example, all data matrices would be loaded on a virtual server for our ML tools (on Requesters and Providers) to access. All required documents created by our ML would be stored on a virtual server (virtual IP address) which can be accessed remotely by the permitted parties. Our ML Language translation tools would be loaded on its own virtual server to perform its job independently which would add to system flexibility and performance speed. In a nutshell our ROE would be helping providers and requesters to put a plan for cooperation and get their goals accomplished. What is ROE Plan: A Plan says "Here is the steps," while a strategy says, "Here are the best steps." Our ROE Plan is how to get the on Requesters and Providers Dialogs started. We also need to have final notes and lessons learned. What are the possible topics in Requesters and Providers Dialogs? The following is our list and we are open to others to help with the list: 1. Parties involved 2. The subjects, material, business, location, countries, languages, ..etc 3. Equipment, experiments, processes, or any research added material 4. Responsibilities: level of personal, group, company, government, ..etc 5. Governance Rules 6. Social Media is involved? or not 7. Goals be accomplished 8. Restrictions 9. Risks 10. Standards used 11. Environments 12. What is publics and what is private 13. Transparency 14. Timeline(s) 15. Roadmap 16. Languages 17. Documents, all the legal docs, technical, non-technical documentation 18. Personal Involved 19. Cost 20. Contacts Image #4 represents a rough draft of ROE structure and how ROE can be automated using ML matrices pool. Image #4 is showing Dental Implants Request and Protein Engineering Request and our ML would be able to create all the ROE required documents for requesters to examine. ROE Automation: Looking at Image #4, Providers would create a matrices of their requirement and requesters would receive all the needed documents to make a decision. Our ML would be doing all the work and both requests and responds can be done automatically in seconds if not milliseconds. 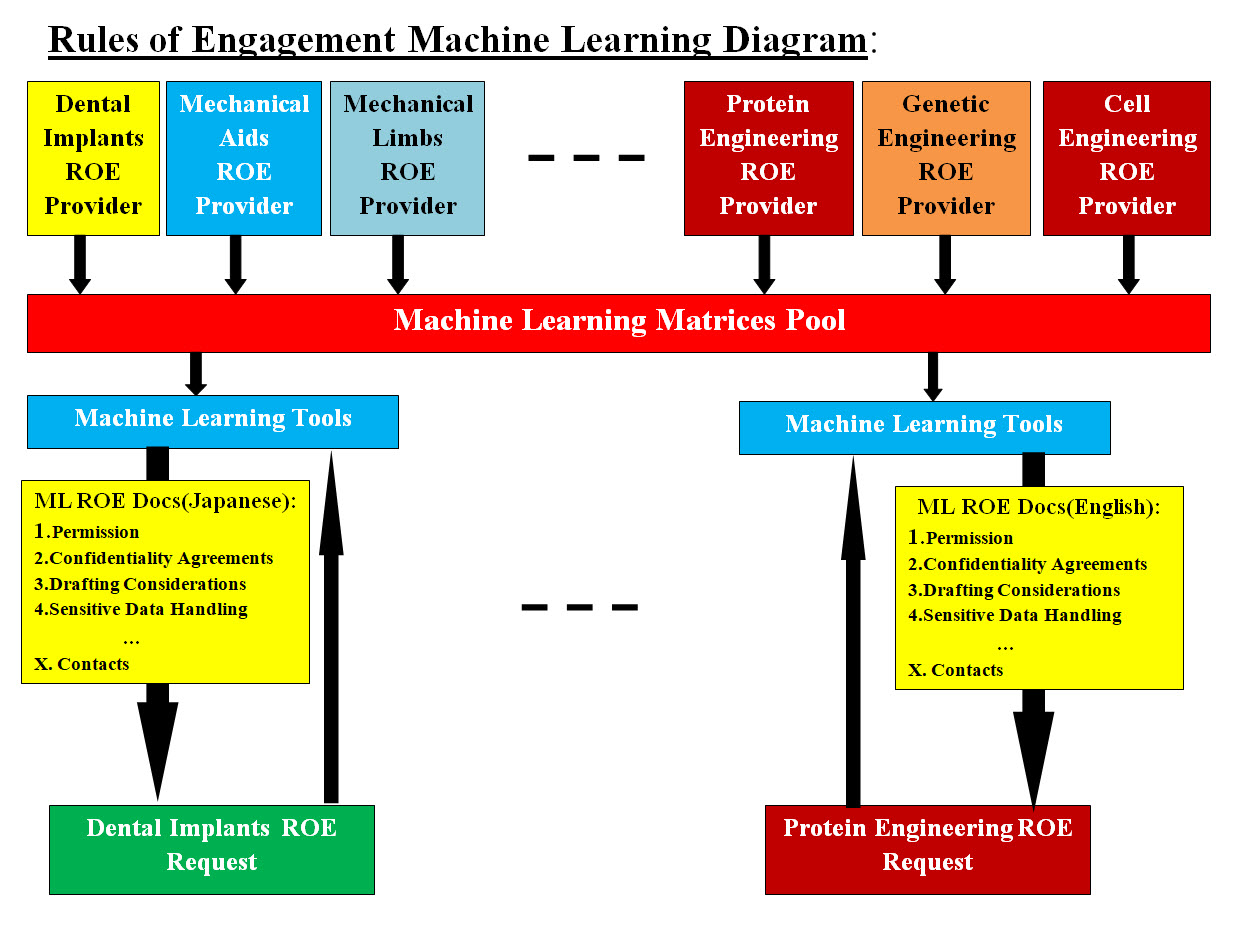
Image #4 Image #4 presents a rough draft of how ROE is performed by ML where a request is made to ML. ML would search ML Matrices Pool looking a match and then build the analysis, all the documentation, reports, .. contact for the requesting party to make a decision. The Requesting part ML would also help by working with all provided docs and reports and assists in the decision-making. Machine Learning and Translations: We are architecting-designing our ML to perform languages translation. This means that our ML would be able to build all ROE documents in any language. For example, in Image #4, our ML build all ML Docs in English and Japanese. Handling Risks of Rules of Engagement ROE risks are serious legal issues that can have negative effects on our Regenerative Medicine Umbrella goals. One of our goals is helping institutions, researchers and companies communicate and cooperate. We are not ROE experts, but we would set the structure and automation. We are presenting the ROE points of discussion between Providers and Requesters. Our Think-Tank(s) would be leading such discussion. This our attempts to help reduce ROE risks. Points of Risks Reduction discussion Topics: Scape: • License • POC • Information usage • Set a security strategy • Deliverables • Requirements Ground rules: • Communication • List of responsibilities • Sensitive information reporting • Security • Restrictions • Authorities • Misuse • Providing broader protection • Confidentiality agreements • Misappropriation • Infringement • Develop a trade secret protection policy for your company and put it in writing Legal Issues: • Litigation cost • Deal cautiously with third parties • Use confidentiality agreements • Trade secrets misappropriation Education and Training: • Educate employees • Training • Educate employees about your Trade Secret • Protection Policy • Monitor employees compliance. Helping Management Deals with Rules of Engagement: Management is critical to the success of institutions, projects or even a trip or a vacation. Management performs planning, organizing, staffing, leading, directing, controlling, monitoring, budgeting, testing, documentation and motivation. in short, management is the difference between making it or breaking it. We are not here to teach management but to list pointers and ideas which would be the checklist for management to work with. We are also reducing the management load by adding automation and ML tools. As for Budget, we would be discussing Budget(s) later once we have enough details. We view management as follows: Managers: Human managers and their experiences and knowledge. Automated Management: Automate the repeated and tedious processes and processers. ML: Intelligence and automation of management processes and procedures. Team Involvement: Managers have to work with a number of teams and teams feedback and brainstorming are critical. How our ML can help? ML composes of Engines (software programs) and Data Matrices. Management engines would be performing the following: • Templates Building • Checklist • Cross-reference • FAQ • Tracking and Audit Trial • Timelines • Graphs Building • Workflow Checklist of Pointers and Ideas: • Scope • Plans • Deliverables • Workflow • Using the Latest technologies • Transparency • Bottlenecks • Risk Assessment • Tracking • Agreements and disagreements • Focus on clarity, accuracy and thoroughness in communication • Possible conflicts • Workload • Time management • Timelines • Legal issues • Brainstorm • Questions sessions • Documentation • Reports • Lessons Learned • Misc Platforms: Introduction: In this page, our attempt is to present our Regenerative Medicine Umbrella for both IT and Regenerative Medicine medical professionals and anyone who is interested in the subject of Our Regenerative Medicine. At the same time, we need to give a true picture of the magnitude and the effort needed to build our Regenerative Medicine Umbrella. Therefore, in this section we are presenting a quick analysis and a rough architect-design to our Regenerative Medicine Umbrella. A platform is a set of hardware and software components that provide a space for developers to build and run applications. Users: Essentially, platforms provide all system software for users to perform their daily tasks. Machine Learning and Infrastructure (DevOps and Bare-Metal): Both Machine Learning and Infrastructure (DevOps and Bare-Metal) are the basic structure which every platform must have.
System Analysis: System analysis is basically a requirement analysis that aims to determine the tasks that are needed to get fully functional system. This analysis undergoes various requirements of stakeholders, documenting, and validating software and system requirements. Architecting Components: System architecture is a conceptual model that describes the structure and behavior of multiple components and subsystems like multiple software applications, network devices, hardware, and even other machinery of a system. Our Regenerative Medicine platforms would be covering: 1. Dental Implants 2. Stem Cells Dental Implants Platform What are dental implants? Dental implants are medical devices surgically implanted into the jaw to restore person normal function, comfort, esthetics and speech to the person dental damages, diseases or injuries. They provide support for artificial (fake) teeth, such as crowns, bridges, or dentures. Dental implants procedures start with patient selection, diagnosis, treatment planning, implant selection, surgical placement, and prosthetic management. Careful attention to the finest details is required to achieve the level of success to the patients’ dental restorations. Dental implants can significantly improve the quality of life and the health of a person who needs them. However, complications may sometimes occur. The Dental Implant process is three phase process, which can be different for each person. The entire process takes from 5 to 8 months. What are the 3 phase of dental implants? In general, there are three phase involved in dental implant procedures. First, the implant itself is placed into the jawbone. Next, the abutment is added to the implant, which is where the artificial tooth will be connected. Finally, the prosthetic tooth, or crown, is placed onto the abutment The global dental implants market size: The growing global dental implants market size was valued at USD 4.15 billion in 2022. The market is projected to grow from USD 4.42 billion in 2023 to USD 6.95 billion by 2030, exhibiting a CAGR of 6.7% during the forecast period. What are the stages of dental implants? 1. Damaged tooth removal 2. Jawbone preparation grafting 3. Dental implant placement 4. Bone growth and healing 5. Abutment placement 6. Artificial tooth placement 7. Implant Scheduled Preventive Maintenance In Preventive maintenance therapy, the goal is to prevent peri-implant mucositis, the early stage of peri-implant disease. Preventive maintenance appointments can vary from 1-month to 6-month intervals, depending on the patient and cleanability of the implant restoration. The following are the Dental Implants Types: • Endosteal • Subperiosteal Implants • Zygomatic • Stem Cell What Are Endosteal Dental Implants? Endosteal The endosteum (plural endostea) is a thin vascular membrane of connective tissue that lines the inner surface of the bony tissue that forms the medullary cavity of long bones. Endosteum covers the inside of bones, and surrounds the medullary cavity. Endosteal dental implants are a type of tooth restoration placed directly in the jawbone. Typically made of titanium, they're the most common type of implant used for replacing teeth. What Are Zygomatic Implants? A zygoma implant is considerably longer than a conventional (root form) dental implant; it is still inserted through the mouth, but it anchors into the cheekbone (zygomatic bone) as opposed to the dental arches (alveolar bone) in the mouth. What Are Subperiosteal Implants: Subperiosteal implants are surgically implanted outside of the jawbone. They sit atop the bone but beneath the gums. What are Stem Cell Dental Implants? Stem cell dental implants take a different approach compared to traditional dental implants or dentures. Stem cell dental implants work towards regrowing the missing teeth in the affected person's mouth. The problem with human teeth is that throughout a person's lifetime, they only get two sets of teeth (baby teeth are lost at the age of 12 or 13 while adult teeth need to last till lifetime). Will stem cells replace dental implants? Stem cells can regrow teeth which is less painful procedures, fewer costs, and more efficiency. Stem cell dental implants will be a great alternative to dental implants and dentures when available and compatible with a patient's needs. Dental Implants Platform Components Analysis Our System Components Analysis is performed to determine how to build the target system. The target system is composed both the software and hardware. We basically split the required components into: • Have to have • Nice to have As for hardware system our intelligent DevOps system would perform all the needed tasks. Note: At this point in our analysis, we are working without any dental implants professional or support. We are at what we call the abstract analysis stage. These analysis would be updated as we get more involved with dental implants professional or support. Software Platform Components: System Target Users: As a first glance of the Dental Implants Platform, we do have two main clients or what we call System Target Users: • Patients - The most important is the patient in the system • Dental Professionals: are quite a few - researchers, practitioners, supporting technicians, ..etc. Our Abstract System Analysis: We are performing our analysis based on our experience and best practices. Our approach is to list of what we believe a platform should "Have to Have" or "Nice to Have". At this point in the game, we would not be able to label any "Have to Have" or "Nice to Have" since it is too early for fair judgement. Note – Readers may skip technical details: The following analysis section goes through a lot of system analysis details and readers can skip this section and go to Dental Implants Platform Components Architect-Design section and check the Dental Implants Platform Architect-Design Component - Image #7 and see what our components architect looks like. 1. System Software
2. Cloud
3. Mobile
4. Existing System
5. Integration
6. Data and Big Data
6A. Data - Customer Relationship Management (CRM) Services
7. Software and Tools
8. Services
9. Third Party Software
10. Equipment
11. Tracking
12. Virtual Modeling
13. Virtual Testing
14. Communication - Interfaces
15. Education
16. Libraries
17. Security
18. Documentation
19. Management
Dental Implants Platform Components Architect-Design In the Platform Components Architect-Design Table, we listed our research of what would be the running platform of any dental implant company or manufacturing. Their platform would include researches, development, education, training, manufacturing dental implants, instruments, third party software, security system, science, solutions, services, ..etc. As for data storage, they may have their Data Center or they could be hosting their data. The same thing goes for their infrastructure, they may own their infrastructure or hosting with a vendor.
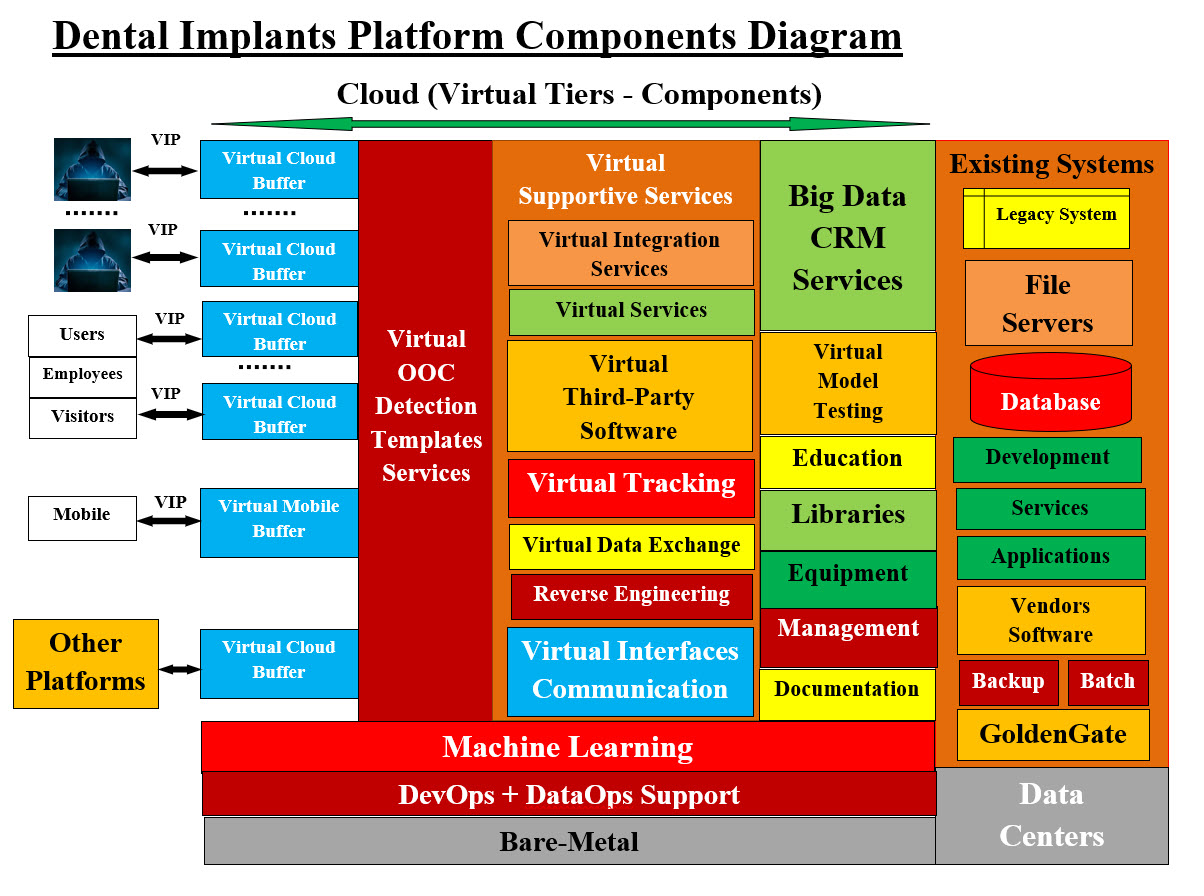
Dental Implants Platform Architect-Design Component - Image #7 Image #7, presents how our dental implant platform would support any existing system. Our Machine Learning Tools and Our DevOps services would be the foundation for both the dental implant company or manufacturing and our supportive platform. Quick Overview of both: • Existing-Running Dental Implant Platform • Our Secured Platform Architect-Design Components Existing-Running Dental Implant Platform We would briefly define each of the existing system components (according to the Internet definition): Infrastructure: Infrastructure is the foundation or framework that supports a system or organization. In computing, information technology infrastructure is composed of physical and virtual resources that support the flow, storage, processing and analysis of data. IT infrastructure can be deployed within a cloud computing system, or within an organization's own facilities. These components include hardware, software, networking components, an operating system (OS), and data storage, all of which are used to deliver IT services and solutions. Legacy System: A legacy system is an old or outdated system, technology or software application that continues to be used by an organization because it still performs the functions it was initially intended to do. Generally, legacy systems no longer have support and maintenance and they are limited in terms of growth. Examples of Legacy system are Mainframe computers running ancient applications. Programming languages, such as COBOL. Operating systems, such as MS-DOS, Windows 3.1 or XP. File Servers: The File Server is a computer that functions through a network to manage and store data files. In an organization, multiple users can access a number of File Servers. A file server is a computer responsible for the storage and management of data files so that other computers on the same network can access the files. It enables users to share information over a network without having to physically transfer files. Databases: A database is an organized collection of structured information, or data, typically stored electronically in a computer system. A database is usually controlled by a database management system (DBMS). Development: Systems development is the process of defining, designing, testing, and implementing a new software application or program. It could include the internal development of customized systems, the creation of database systems, or the acquisition of third party developed software. Services: System software includes the operating system and a variety of utility programs that help manage a computer's resources and provide standard services for computer programs, which is the common feature of system software. Software Services means services that make available, display, run, access, or otherwise interact with the functionality of the Software Products, which you provide to Users from one or more data centers through the Internet or a private network. Applications: Application software is an end-user program typically divided into two classes: application software and systems software. Systems software provides an operating system and utilities that enable applications software such as database programs, spreadsheets, web browsers, and more to run. An application program (software application, or application, or app for short) is a computer program designed to carry out a specific task other than one relating to the operation of the computer itself, typically to be used by end-users. Word processors, media players, and accounting software are examples. Mobile App means a software application developed for use on mobile devices and tablets that use a particular mobile operating system, which application delivers, inter alia, audio-visual content to particular mobile devices that use that mobile operating system. Vendors Software: A software vendor is a company that develops and sells software. Most commonly, the term software vendors refer specifically to independent software vendors (ISVs), organizations that create solutions for use by the larger market. Backup System: Backup software is a computer program that makes a copy of your files and folders or your complete system, including the operating system, applications and data. Batch Processing: Batch processing is the method computers use to periodically complete high-volume, repetitive data jobs. Certain data processing tasks, such as backups, filtering, and sorting, can be compute intensive and inefficient to run on individual data transactions. Computerized batch processing is a method of running software programs called jobs in batches automatically. While users are required to submit the jobs, no other interaction by the user is required to process the batch. Batches may automatically be run at scheduled times as well as being run contingent on the availability of computer resources. GoldenGate: GoldenGate or Oracle GoldenGate is an extension of Oracle's data offering that enables you to replicate data from one database to another. Its modular architecture gives you the flexibility to extract and replicate selected data records, transactional changes, and changes to data definition language (DDL) across a variety of topologies. Data Centers A data center is a physical facility that organizations use to house their critical applications and data. A data center's design is based on a network of computing and storage resources that enable the delivery of shared applications and data. Our Secured Platform Architect-Design Components Our Architect-Design is composed of a number of virtual tiers and virtual components. Creating or deleting any number of tiers and their components can be automated. Creating any number of a specific tier and their components can also be created on the fly to handle any traffic loads. For example, looking at Image #7, Big Data and CRM Services may not be required by clients with limited number of customers or services. Our Virtual Cloud Buffer creations and deletions would be automated to handle malware attacks. Machine Learning support and Virtual OOC Detection would be combined to deter DDoS Attacks. Virtual Components: Any hardware, software, firewalls or connections can be emulated, created or mimicked by software. Therefore, Virtualization is a very powerful concept and a great tool. Servers, system, connections, networks, clusters of networks or any software can be created-released virtually in any number and on any Bare-Metal servers or even virtual servers. A Network is composed of all the running hardware, software, interfaces, wiring, IP addresses, licenses and anything any network requires. A cluster is a number of networks working together for common computing purpose. With virtuality, a virtual network with virtual routers and emulated hardware can be created. A group of virtual networks would be grouped into a virtual cluster. Note: In the previous sections in this webpage, we have covered the following terms and readers may use the page search to learn and check our definitions: Machine Learning, DevOps, Bare-Metal, Virtual Supportive Services, Virtual Integration Services, Virtual Third-Party Software, Virtual tracking and Audit Trail, Virtual Data Exchanges, Virtual Interfaces, Virtual Communication, Big Data, CRM, Virtual Model, Virtual Testing, Education, Libraries, Equipment, Management and Documentation The following definitions are our system view and our handling of such objects or terms: Hackers: A hacker is an individual who uses computer, networking or other skills to overcome a technical problem. The term also may refer to anyone who uses their abilities to gain unauthorized access to systems or networks in order to commit crimes. Hacking can be performed by an individual, groups, state sponsored group or anything in between. State-sponsored attacks are carried out by cyber criminals directly linked to a nation-state. Their goals are threefold: Identify and exploit national infrastructure vulnerabilities and gather intelligence. Hacking and Cybersecurity are serious issues and there are state-sponsored hacker groups. It has been observed that countries with the most advanced technology and digitally connected infrastructure produce the best hackers. China and USA are clear examples of digitally advanced nations which both deploy tools and specialists for intelligence gathering, and for the protection of their national interests. Our Strategies: We do need strategies to handle hackers and their attacks. Therefore, we need to think in a number of terms. First, how hackers and specially internal hackers think and operate. What tools they use and how do they find vulnerabilities in their target system. We also would not be able to close all the system holes and gaps, but we can use the strategy of keep hackers guessing what to do next by keep moving their target (by dynamically created and deleted virtual servers) so any hacker attempt would have to start all over again. The question is how economically and easily can we implement these strategies plus do the training and maintaining of these implementations. The following are a list of our strategies: 1. Virtual Proxies, Virtual Servers, Virtual IP Addresses and Virtual Objects 2. The use of Machine Learning to provide guidelines of protecting the cloud services 3. Closed Box Virtual Database Services 4. Chip to Chip Communication 5. Dynamic Virtual redundancies of Virtual cloud services 6. Use of NAS as backup and rollback storage 7. Using logging, tracking and audit trial - internal hackers 8. Training employees and cloud services users on protecting against hackers 9. Brainstorm the development cost and performance of our architected solutions Virtual IP Address (VIP): A virtual IP address (VIP or VIPA) is an IP address that doesn't correspond to an actual physical network interface. A virtual address space or address space is the set of ranges of virtual addresses that an operating system makes available to a process. VIPs includes network address translation (especially, one-to-many NAT), fault-tolerance, and mobility. Virtual Cloud (Security) Buffers: A computer buffer is a temporary memory space. A buffer helps in matching speed between two devices and between two data transmission. Our Virtual Cloud Buffer is a virtual server created as a Container. The main objective is to separate between the outside world and internal structure and services. The size of our Virtual Cloud Buffer is dynamic and flexible to handle any load. Each buffer has its own virtual IP address. Container and components would be running inside our Virtual Cloud Buffer and wiping our Virtual Cloud Buffer clean is one of its main features. Hackers and their code would not get further than our Virtual Cloud Buffer. See the following link (Object Oriented Cybersecurity Detection Architecture (OOCDA) Suite): Virtual Cloud Buffer Virtual Mobile (Security) Buffers: Virtual Mobile Buffer uses the same concept as the Virtual Cloud Buffer. It is mainly designed for Mobile accesses. Virtual OOCD Templates Services: See the following links: Object Oriented Cybersecurity Detection Architecture (OOCDA) Suite© Virtual OOC Detection Templates Services© Users: Our view of a user is: anything (individuals, companies, hardware, software, databases, clients-server request, B2B, B2C or other platforms) which has a request for our local or remote services. Based on the type of user, there is a number of parameters such as security, privileges, permissions, accesses, ..etc. Employers: Employees are a company's greatest asset, but also a major risk. Employees can be a network user, an administrator, security engineer, managers, CEO, ..etc. For example, spare-phishing is a specific and targeted attack on one or a select number of victims, while regular phishing attempts to scam masses of people. In spear phishing, scammers often use social engineering and spoofed emails to target specific individuals in an organization. Mobile: A server is a machine that stores data and allows others to access this data. A client is any device that you use to access a server. Therefore, this could be a laptop, a smartphone, or an internet-connected device, like a printer, or even a car. Mobile services needs a special handling than the internet, even though they both are accessing internet servers. Other Platforms: The main goal of Our Regenerative Medicine Umbrella is communication between platforms. DataOps: Our DataOps Definition: DataOps is any data operations or processes which include Big Data, CRM, Analytics, Data Visualizer, Data Minding, Data Storage, Business Intelligence (BI) and Data Security. In a nutshell, DataOps is any data operation which advances and secures your business. Based on our definition, the scope of DataOps would be too vague and too broad to handle. See the following link: DataDops Reverse Engineering: Reverse Engineering is a service which would be used to aid with Cybersecurity detection. See the following link: Reverse Engineering Sam's Machine Learning Analysis, Data Structure-Architect Building Our Dental Implant Platform We are IT analysts, architects, and managers who turn any idea in a "System on Paper." The question at this point in this webpage after our analysis and architect documentation are presented: How can we turn "System on Paper" into a reality or real running system? In short and simple terms for both technical and non-technical audience, we would need to brainstorm with clients, vendors, teams, management, existing structures, resources, funding, timeline, ..etc. Our recommendation for the first steps would be: 1. Virtual Thinking and Virtual Implementation 2. Build Project Plans (again on paper means soft copy) 3. Get a cost estimate (on paper) 4. First and the most important step is to build our Intelligent Automated DevOps-Infrastructure tools 5. Build on Machine Learning (ML) support tools for DevOps 6. Use ML as the basis for the rest of the project business units and components 7. Start training teams 8. Build Virtual Modeling and Virtual Testing 9. Automate the build of any modeling and testing 10. Develop reusable components 11. Test early and Test often These points are our short quick first steps and we would not want to overwhelm readers with a lot of details. Stem Cells Platform Introduction: The main job of our Regenerative Medicine Umbrella is to help Regenerative Medicine medical professionals, institutions and companies communicate, cooperate and share information and tools for the good of all. We also do not want to be repetitive in our presentation nor sidetrack our Regenerative Medicine Umbrella objectives. The focus of Stem Cells Platform is to present both the Stem Cells Platform Analysis and Architect in order to show how can Regenerative Medicine associated fields be able to use both Data Exchange and Rules of Engagement. The following sections are our quick analysis of Stem Cells as an associated field. We are IT professionals and not medical professionals. Therefore, we are presenting Stem Cells as a quick summary of our research. Note: Stem Cells can be a part of any Regenerative Medicine associated fields or it can run as an independent platform. The Stem Cells Platform section is composed of: 1. Quick Analysis 2. Stem Cells Platform Components Quick Analysis Dictionary: From our experience, we found that we need to present the basic elements and buzzwords which what we call this section "Dictionary". Such quick definitions of terms make life a lot easier. What are Stem Cells? Quick Definitions: Stem Cells are: • The body's raw materials • Cells from which all other cells with specialized functions are generated • Under the right conditions in the body or a laboratory, stem cells divide to form more cells called daughter cells Stem Cells are: • The foundation cells for every organ, tissue and cell in the body • They are like a blank microchip that can ultimately be programmed to perform particular tasks • Stem cells are undifferentiated or "blank" cells that have not yet fully specialized • Under proper conditions, stem cells begin to develop into specialized tissues and organs • Additionally, stem cells can self-renew, that is they can divide and give rise to more stem cells Basic Terms: The following terms are the basic terms the readers should be familiar with or can search for it. Our job is not to teach but to bring the needed basic knowledge so we all can be on the same page and terms. Human Cell, Red Blood Cells, White Blood Cells, Nerve Cells, Ovum, Sperm, Bones (Osteoblasts, Osteoclasts, Osteocytes), Ciliated Cells, Epithelium, Villi Cells, Tissue (Connective , Epithelial , Muscle , Nervous) Embryonic stem cells, Adult stem cells, Hematopoietic Stem Cells (Blood Stem Cells), Mesenchymal Stem Cells, Neural Stem Cells, Epithelial Stem Cells, Skin Stem Cells, Perinatal Stem Cells Induced Pluripotent Stem Cells (iPS), Somatic Cell Nuclear Transfer (SCNT), stem cell line Specialized Cells, Cell Divisions (Mitosis, Meiosis, Binary Fission), Types of Cell Division, Blastocyst, Embryo Growth, Stem Cells Are Undifferentiated - Blank Cells, Daughter Cells Organs - 78 organs, Vital Organs (Brain, Heart, Lungs, Kidneys, Liver) Totipotent (or Omnipotent) Stem Cells Pluripotent Stem Cells Multipotent Stem Cells Oligopotent Stem Cells Unipotent Stem Cells Endoderm Mesoderm Ectoderm Stem Cells Revisited 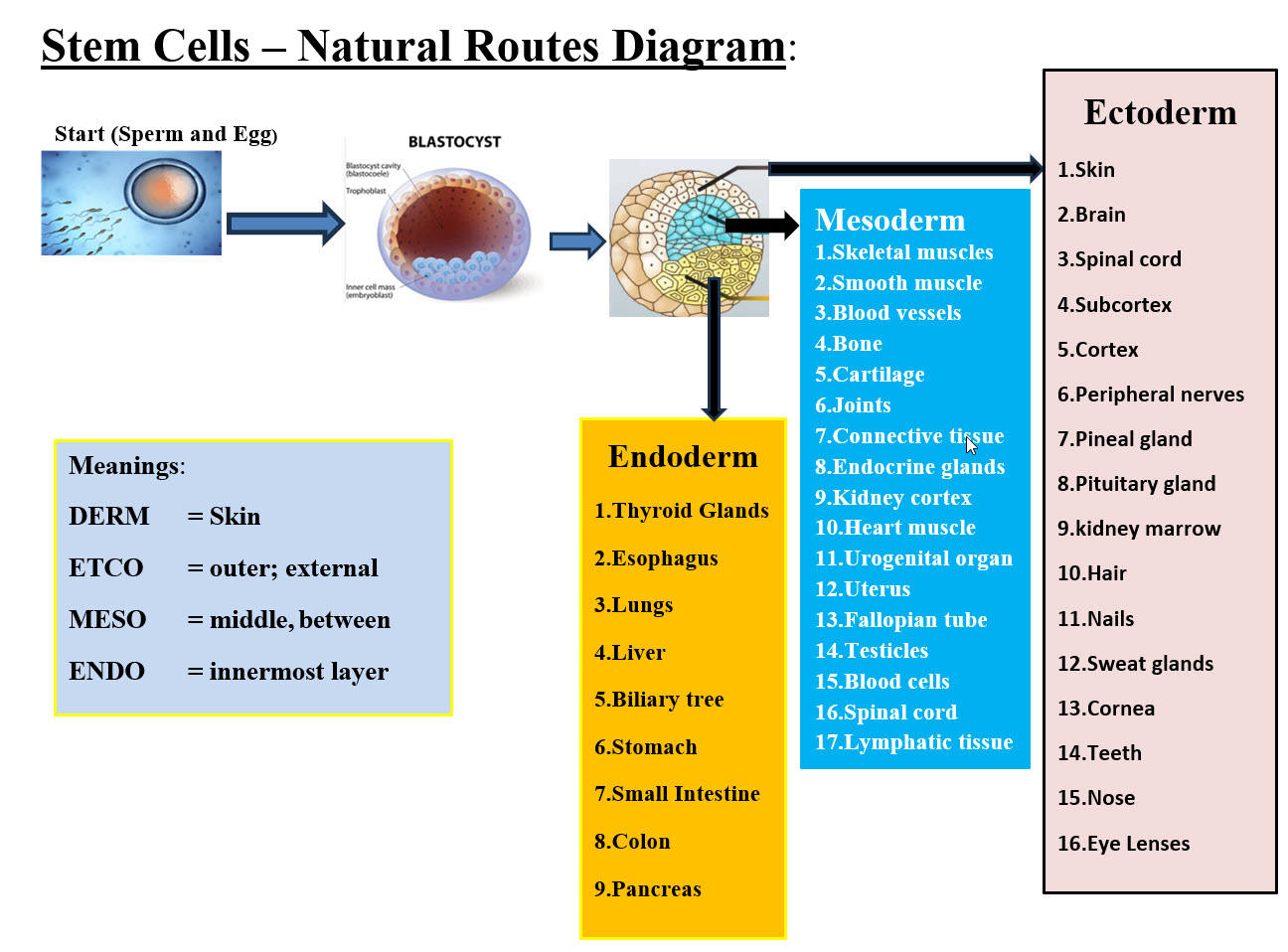
Stem Cells - Natural Routes Diagram - Image #8 Image #8 represents the natural routes from sperm and egg to full developed human organs. We are showing the source where stems cells started in the Blastocyst and the branching of Endoderm, Mesoderm and Ectoderm to develop all human organs. Types of Stem Cells in Teeth: There are five different types of dental stem cells have been isolated from mature and immature teeth: 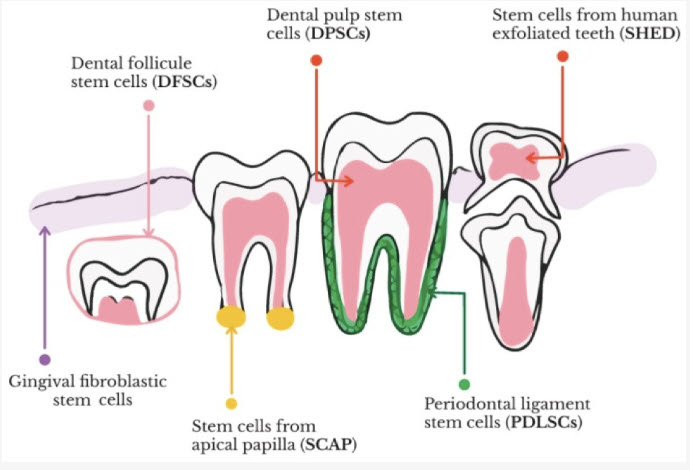
Five Dental Stem Cells 1. Dental Pulp Stem Cells (DPSCs): Dental pulp stem cells (DPSCs) are stem cells present in the dental pulp, which is the soft living tissue within teeth. DPSCs can be collected from dental pulp by means of a non-invasive practice. 2. Stem Cells from Human Exfoliated Deciduous Teeth (SHED): Stem cells from human exfoliated deciduous teeth (SHED) are highly proliferative pluripotent cells that can be retrieved from primary teeth. Although SHED are isolated from the dental pulp, their differentiation potential is not limited to odontoblasts only. In fact, SHED can differentiate into several cell types including neurons, osteoblasts, adipocytes, and endothelial cells. 3. Periodontal Ligament Stem Cells: Periodontal ligament stem cells are stem cells found near the periodontal ligament of the teeth. They are involved in adult regeneration of the periodontal ligament, alveolar bone, and cementum. 4. Stem Cells from Apical Papilla: Stem cells from the apical papilla (SCAPs) residing in the apical papilla of immature permanent teeth represent a novel population of dental MSCs that possesses the properties of high proliferative potential, the self-renewal ability, and low immunogenicity. SCAP are neural crest-derived mesenchymal stem cells (MSCs) that are homologous to cells in craniofacial tissue and represent a promising source for craniofacial tissue regeneration. 5. Dental Follicle Progenitor Cells: Dental follicle progenitor/stem cells (DFPCs) are a group of dental mesenchyme stem cells that lie in the dental follicle and play a critical role in tooth development and maintaining function. Originating from neural crest, DFPCs harbor a multipotential differentiation capacity. Dental pulp progenitor cells are the most attractive cells for periodontal tissue engineering based on their good growth and differentiation capacity. Turning Stem Cells into Java Design Factory Pattern and Machine Learning Tools We as IT analysts, architects and developers need to think in Object Oriented Programming (OOD) in order to develop objects. From object, we would build the target software. OOD is designed for reusability. Our attempt here, is to get Stem Cells professionals to use our thinking and approaches to build organs or tissues. Our IT thinking calls these organs and tissues "Objects." The goal is to develop objects. What is a factory design pattern in Java? 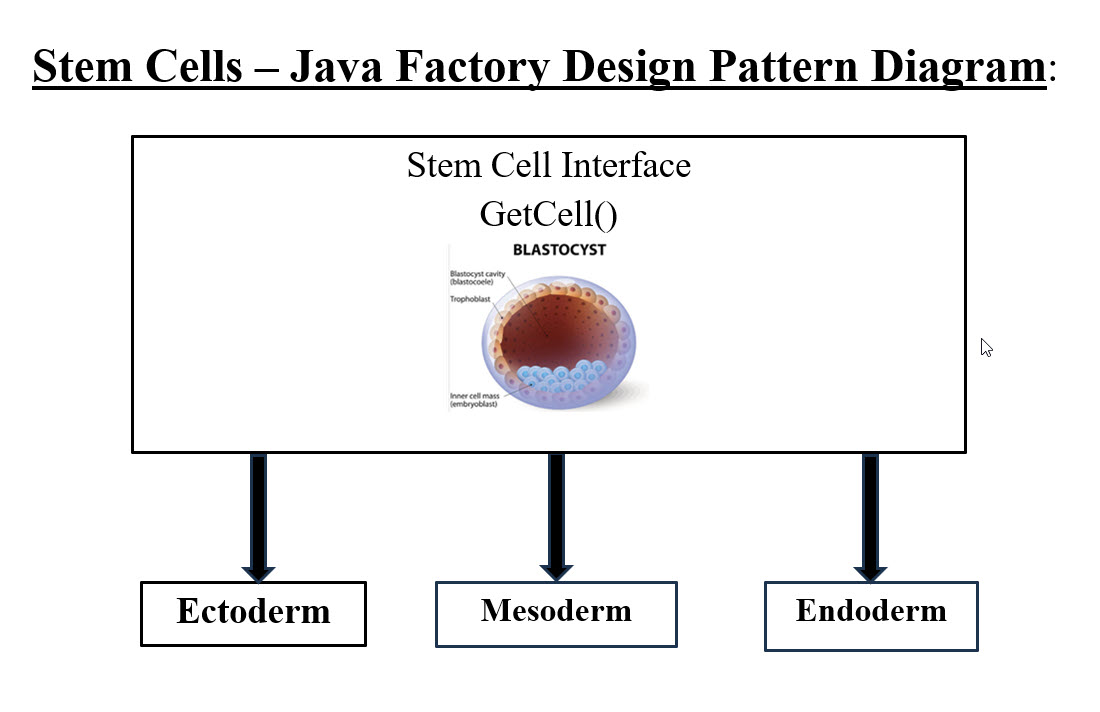
Stem Cells - Java Factory Desing Pattern Diagram #9 To make it simple for non-programming audience, a stem cell is a blank chip or what we call in Java an interface. Each interface must have a factory method which is used to start the building of the object (organ). The Interface is nothing but a blank chip which we add to it the programming to get it to be the final target object (organ). Image #9 has the structure of Stem Cell Interface with a method or procedure called GetCell(). Anyone who is using Stem Cell Interface, must build this method in order to be an object for reuse or be inherited. This helps in building a structure for teams or researchers who would build the basic procedures of developing the target organ. What is the Ectoderm object, the Mesoderm object or the Endoderm object? Each object is composed of all the documented procedures, processes, methods, experiment, notes, reports, or any material needed for reperforming the development of the object. Such documentation can also be in the form of software programs which can be used to develop the object. The software is far better choice than documentation since we would be building intelligent software to perform analysis, researches, build reports or any data driven system. Stem Cell Interface with GetCell() method can be implemented or developed into Ectoderm object, Mesoderm object or Endoderm object. Each object has its own implementation which can be used by others without starting from scratch. For example, any researcher who wants to develop or repair a human liver for his patient, he would be using Endoderm Object and would not need to start from scratch. The Endoderm Object would have all the procedures, steps, the do-and-do not, and all material and documentation for his work to be completed. Plus, he can add to the Endoderm Object his own work, experiment, ..etc. He basically inherited Endoderm Object and build a new Endoderm Object for others use his additional work and documentation. Object (Organ) and Reverse Engineering: Once we know how to start the building of an object (organ), then we can used reverse engineering to get from the organ to the stem cell. Therefore, we get stem cells for organs (factory), then we use stem cells to build organs. 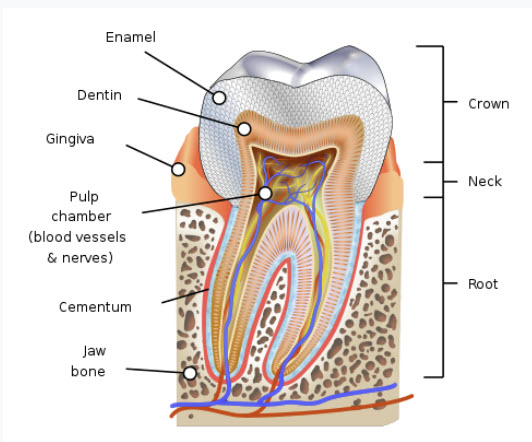
Tooth Internal Structure - Image #10 For example, looking at Image #10 Tooth Internal Structure, stem cells professionals and researchers would need to figure out which component (Ectoderm Object) would be used as the initial start for developing a new tooth and which (methods) procedures are needed to develop the target object (organ). Once we have the know how of getting from Endoderm object to a human tooth, then we can use such knowledge to know how (reverse engineering) to get from human tooth to Endoderm object and possibly stem cells. Researchers also would be looking which of the tooth cells (Dentin, Enamel, Cementum, or Jaw Bones) that may have the needed stem cells for starting the Endoderm object. Machine Learning (ML): Machine Leaning is software tools which perform the detail analysis and help with the decision-making. Automation: Using ML would help automate Stem Cell analysis and processes. ML would be performing all footwork for stem cells researchers and professionals. Note: We are attempting to present how we can structure stem cells processes without details. We believe the details are far more complex which takes a lot of efforts and time. Therefore, we need to work with stem researchers and professionals to build the needed structure with the details. Stem Cells Reverse Engineering What is Reverse Engineering? Reverse Engineering is the analysis of a device or program to determine its function or structure, often with the intent of re-creating or modifying it. Pros and Cons of Reverse Engineering: Pros: In software, reverse engineering would help convert executable code to source code and be able to see how the programming modules are doing. Reverse engineering can help improve the design of existing products by identifying areas for improvement and optimization. It can also help engineers to understand how products work, which can lead to better designs and more efficient manufacturing processes. Cons: In software, reverse engineering or decompiling is using a software tool to covert executable code to language code or source code. Sadly it can be very complicated with countless number of statements and mixed logic. Reverse engineering can also pose some technical challenges that require skills, tools, and patience. Reverse engineering can be time-consuming, complex, and frustrating depending on the level of complexity, protection, encryption, or complication of the products. What is human immune system? The immune system is a complex network of organs, cells and proteins that defends the body against infection, whilst protecting the body's own cells. The immune system keeps a record of every germ (microbe) it has ever defeated so it can recognize and destroy the microbe quickly if it enters the body again. The immune system is a complex system that creates the body's defense against infection. It is made up of white blood cells, the spleen, the thymus gland, and lymph nodes. It is able to recognize self and identify substances that belong in the body and substances that are foreign to the body. It is genetically programmed to attack any foreign or "non-self" substance. What is stem cell transformation? Under the right conditions in the body or a laboratory, stem cells divide to form more cells called daughter cells. These daughter cells become either new stem cells or specialized cells (differentiation) with a more specific function, such as blood cells, brain cells, heart muscle cells, tooth cells or bone cells. Our Stem Cells Reverse Engineering Recommendations: Some of the goals of reverse engineering are reusability and tracing building and disassembling of the target object (organ). We have to consider the fact that the stem cells researchers and medical professionals are dealing with Nemours unknown factors. The probabilities of success or failure are also unknown. We recommend two processes: • Documented Building Object • Virtual Simulation and Virtual Testing Software Tools (with ML) We are very much doing trial and errors steps with low coast processes. Such trial and errors processes would help researchers and medical professionals see or vision the target goals and how to achieve them. They would be testing almost all their wild guesses and hopefully would learn of what to do and not do without big cost. Let us take a simple example as follows: Process #1: X Type Stem Cell Process #2: Cultured in laboratory to build starting tissues Process #3: Planting the target tissues in the patient mouth Process #4: Regrowing of organ (tooth) Process #5: Fully functional Organ (Permanent Tooth) is done The following is how each of our recommended processes would be used. Documented Building Object: This Documented Building Objects is how to build Java Design Factory Pattern and Machine Learning Tools. The staff who would be building such object would be creating all the needed documentation and build the structure of such documentation starting with Process #1 to Process #5. The staff can use ML to perform the analysis for building the required documents plus use ML to check the accuracy of their documents or work. Virtual Simulation and Virtual Testing Software Tools (with ML) This approach would require building simulation software with ML to to perform analysis, presentation and testing. ML would perform analysis and testing the accuracy of results. The building of such simulator and testing software would not be a small task, but it can be done with small budget and cashing in on reusability. Independent Stem Cells Platform Components: Note Stem Cells can be a part of any Regenerative Medicine associated fields or runs as an independent platform. Readers need understand that our Stem Cells Platform Components are very much the same as that of Dental Implants Platform Components. The only difference is the business or the field which we are build such platform for. In the case where Stem Cells is part of other platform, then Stem Cell would be sharing the platform components with main associated field. For example, Dental Implant Platform can be the main platform and Stem Cells would be a subsystem running within the Dental Implant Platform. We do recommend that readers review the Dental Implant analysis and architect section for details of building out target system. 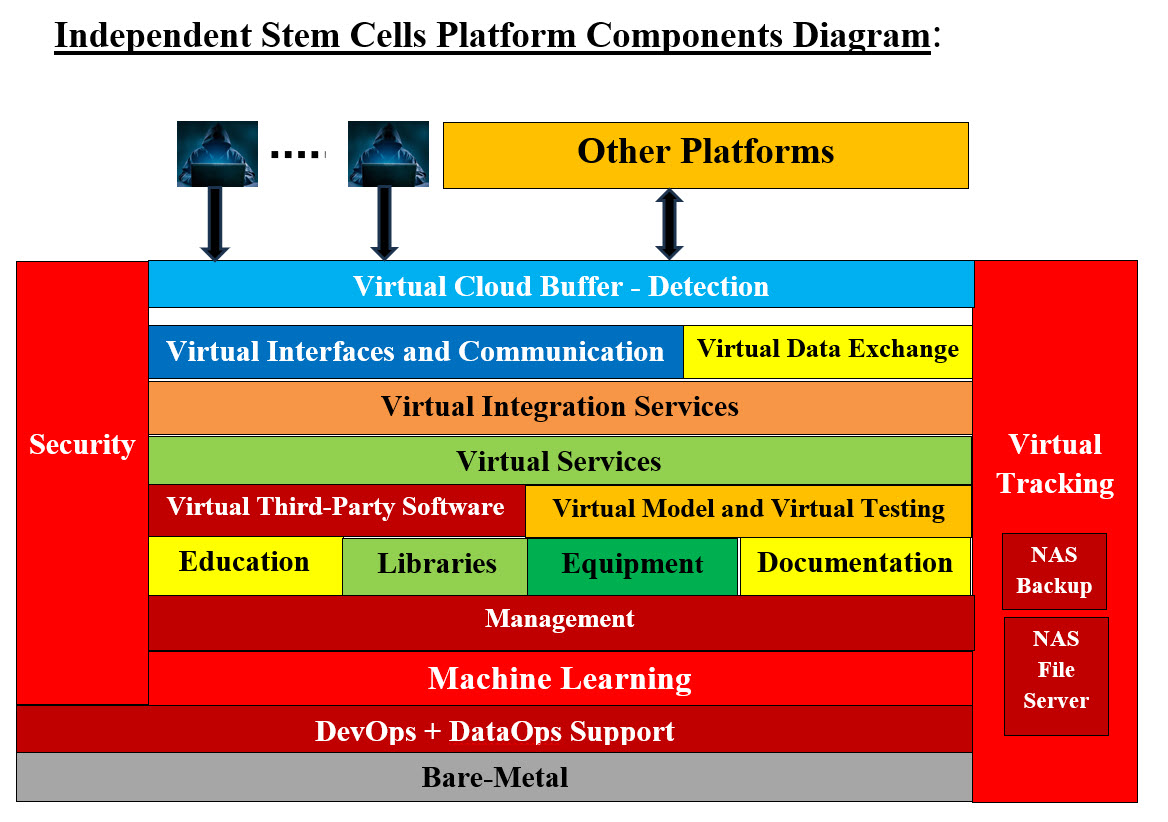
Independent Stem Cells Platform Components Diagram - Image Independent Stem Cells Platform Components Diagram - Image represents the Stem Cells Platform Components as an independent system and not a subsystem. We also add NAS servers as backup server(s) and file servers. Security runs independently and interfaces with other security systems plus other remote systems. Virtual Cloud Buffer and Detection are used as a front to Stem Cells Platform plus a proxy front server(s) to handle any security threats. The following is the list of components: 1. Virtual Cloud Buffer 2. Detection 3. Security 4. Virtual Interfaces and Communication 5. Virtual Data Exchange 6. Virtual Integration Services 7. Virtual Services 8. Virtual Third-Party Software 9. Virtual Model and Virtual Testing 10. Education 11. Libraries 12. Equipment 13. Documentation 14. Virtual Tracking 15. Management 16. Machine Learning 17. DevOps + DataOps Support 18. Bare-Metal 19. Other Platforms 20. Hackers 21. NAS Backup 22. NAS File Server Other Platforms: Our Independent Stem Cells Platform architect is a cloud-based system and it would be communicating with other platforms. Virtual Cloud Buffer and Detection are used as a front tier to Stem Cells Platform plus a proxy front server(s) to handle any security threats. Virtual Interfaces and Communication and Virtual Data Exchange would perform all the interfaces, communication, data exchanges. See the Dental Implant Platform for more details on how communication and data exchanges are performed. Hackers: Our architect security main objective is keeping hackers guessing how to access our system. Having proxy buffer virtual server with dynamic IP address which is constantly changing on a scheduled basis. We also dynamically and periodically restarting new virtual server which replace the running ones. We literally wipe the old virtual server clean once the new virtual server replacement with new IP address. Both our cloud and other communicating platforms have a scheduled connection protocols with IP addresses and exchanging messages and passwords. As for internal system, our detection and tracking are making sure that no outsiders can access anything plus all transaction and users are tracked and unauthorized access are trapped. Network Attached Storage (NAS) Backup: Network-attached storage (NAS) is dedicated file storage that enables multiple users and heterogeneous client devices to retrieve data from centralized disk capacity. A NAS allows for quick sharing of data, it comes in a small package that can fit in limited office space. NAS File Server: NAS is a file server that delivers files to users across a shared network. Each user connects to the server and as they request files the server. It's important to remember NAS devices and servers are mostly used for the same thing - to store and share files across a network. Importantly though, A NAS allows for quick sharing of data, and it comes in a small package that can fit in limited office space. Stem Cells and Dental Implants Data Exchange and Rules of Engagement In our Data Exchange and Rules of Engagement sections in this page, we presented how Regenerative Medicine associated field would be able to communicate and cooperate for advancement of Regenerative Medicine. Regenerative Dentistry as a Product: Stem cell tooth regeneration is not a mainstream dental treatment at present time. Data Banks and Libraries Components Support - Find Common Ground: Commercial Banks: Commercial banks are an important part of the economy. They not only provide consumers with an essential service but also help create capital and liquidity in the market. Data Brokers: A data broker is an individual or company that specializes in collecting personal data or data about companies, mostly from public records but sometimes sourced privately, and selling or licensing such information to third parties for a variety of uses. A Data Broker is a business that aggregates information from a variety of sources; processes it to enrich, cleanse or analyze it; and licenses it to other organizations. Data brokers can also license another company's data directly, or process another organization's data to provide them with enhanced results. Data is typically accessed via an application programming interface (API), and frequently involves subscription type contracts. Data typically is not "sold" (i.e., its ownership transferred), but rather it is licensed for particular or limited uses. (A data broker is also sometimes known as an information broker, syndicated data broker, or information product company.) Blood Bank: A blood bank is a center where blood gathered as a result of blood donation is stored and preserved for later use in blood transfusion. Blood banking is the process that takes place in the lab to make sure that donated blood, or blood products, are safe before they are used in blood transfusions and other medical procedures. Blood banking includes typing the blood for transfusion and testing for infectious diseases. Library: We presented in one of the previous sections Our Vision of Our Intelligent Dynamic library and how it can contribute to any teams. Our Concept of Data Banks and Libraries Components Support - Find Common Ground: Commercial banks, data brokers, blood Banks and libraries are resources which support the ongoing businesses, projects, development, researches, treatments or even governments. We do want to cash on such concept to support our Regenerative Medicine Umbrella. Such a concept is easy said than done. Again, we need to structure and implement intelligence, automation, integration, virtualization and Machine Learning. We would also add an important note which Regenerative Medicine associated fields are very diverse and researchers and medical professionals may not speak the same language, work on the same projects, target the same results, use the same tools nor work with the same data. Finding a common ground is our goal. Structure Our Vision: We need present a number of scenarios to help our readers see our vision for our data bank and libraries. Loans: A financial bank would have personals who would service customers load applications. The customers would fill out forms and present their credentials. Bank staff would present these applications to the bank loan officers who would try to match the loan requests with the bank loans programs. They may also be looking for outside lenders to see if they can sell the loan applications. The bank main business is finance. In the case of a data bank, we envision that there would be similar services. The data bank main product is data which would be sold or licensed. In this case scenario, the bank owns the data and/or represents the data owners. We would be adding also data support. We also envision that all the services would be cloud, automated, virtual, intelligent, integrated and use Machine Leaning support. Funds - Sharing: People deposit their money in the bank and the bank uses the customer money to service other business transaction such loans or other financial services. The bank customers expect to be paid for keep their money in the back with the expectation of get paid interest or dividends. The same thing with data bank, researchers, companies, institutions or medical professionals can deposit their researches, findings, documentations, publishing or experiment in our data bank for other to use and in return they may get paid, share or team up with others or whatever they would be requiring from others who would be using their work. Investors - Teaming: In this scenario, investors with money and resources, would be teaming up to hopefully make more money or other goals. Our data bank would be the coordinator or the hub for researchers, companies, institutions, medical professionals or governments to join forces and build a coalition or alliance for common goals. Public Data and Services: Since our Data Bank is not dealing with personal or private data, then our bank can help anyone or any institution for free by providing data as a free public service. Other institutions and governments can also use our data bank to support our public services. Summary of Our Data Band and Library Vision: Our Data Bank and Library would be: 1. Licensing Data 2. Selling Data - Deposit Data for Income 3. Hub for Data Sharing 4. Data Center for Teaming and Cooperation 5. Data for Public Services 6. Software engines for data handling, formatting and usage 7. Security Services 8. Compression-Decompression-Encrypting-Decrypting Services 9. Machine Learning Tools What is the difference between Our Data Bank and Our Library? • Our Data Bank is a business and its services come with cost • Library may or may not has a cost associated with its services • Software tools also may have a cost or they come with services Data Bank and Library Input-Output Structure Analysis We as IT professionals who have been trusted with current task of building a Data Back and Library for Our Regenerative Medicine Umbrella, we have to be the data jack of all trades. This actually forces us to use automation, intelligence, ML, integration and virtualization. Our Goals: We need to understand: • What we are dealing with • How to achieve our goal of building our data bank and library Our tasks are not simple, but our knowledge, experiences and talent are the key ingredients of simplifying the overwhelming topics, tasks, obstacles, issues, conflicts, technologies, big data and all data issues and hardware and software building which we need to address. Data Buzzwords: Data scientists, data analysts, data security, data collections, purchasing, licensing, data analysis, data structure, data visualization and communication, ML experts, AI (we are not AI experts), business intelligence, storage, backup, rollback, specialization, report generations, visualization and communication, create data from data, create data matrices, format data for usage, make predictions, generate reports and dashboards, analyze trends, help with decision-making, build estimate, create analytic engines, perform cross-validation, metadata, databases, data dictionaries, business data, financial data, generating accurate picture of what is going, data modeling, ..etc. Topics at Hand: 1. ID Our Data Bank and Library Vulnerability 2. No use of databases only file format 3. Security threats in any form or shape 4. Security Updates 5. External hackers 6. Internal - insiders - employees 7. Data leakage 8. Data corruption due to hardware failures 9. Data corruption due to software bugs 10. Unauthorized Access 11. Damage Data 12. Loss the data 13. Data Purged 14. Data Restriction 15. Cloud Storage 16. Remote Access 17. Using Network Attached Storage (NAS) 18. Load and Traffic Handling 19. Massive Data - knowledge Base. 20. Data Growth Issues 21. Data Availability 22. Data Accessibility 23. Data Access Privileges 24. Sites Access 25. Data Maintenance 26. Data Updates 27. Data Sites Capability 28. Tracking and Audit Trail 29. Data Buffers 30. Synchronization 31. Data Analysis 32. Parsing 33. Converting 34. Data Searches 35. Data Quality and Quality Control - Accuracy-Validity-Relevancy-Consistency-Timeliness-Integrity-Conformity 36. Access reliability 37. Analysis 38. Formatting 39. Cross Refence - Data Quality Scaling 40. Usability of the data 41. Data Catalogs 42. Quantity of Knowledge 43. Data Compression-Decompression 44. Data Encryption-Decryption 45. Intelligent Data Services 46. Realtime Handling 47. APIs 48. Integration 49. Interfaces and Communication 50. Vendors Interfaces 51. Third Party Software 52. Operation Cost 53. Governance and Control 54. Data Management 55. Documentation Communication and Common Ground Using Our Business Dictionaries: Generative Medicine associated fields are diverse and we need to stablish communication business vocabulary. We are proposing the building of a number of business dictionaries as basis for communication, interfaces and exchanges. Once we have a common business vocabulary(s) then communication and data processing and storage would be used without any extra effort of parsing and conversion. Data would be uniformly handled. Business Tokens: Business Tokens are alphabets of all our dictionaries. Every token has its own unique ID. No Databases nor Hadoop: We are not using databases nor Hadoop as our data storage. We would accept any input data from databases or Hadoop. For example, we may be able to access remote databases to collect input data which would be parsed and converted into our data processing format. Our Data File Structure and Network Attached Storage (NAS) - Data Storage: Our data would be stored mainly as text except images and specialty files. We are proposing on using faster, highly scalable and secure network attached storage (NAS) solutions that can integrate easily with multi-cloud infrastructure to deliver cost-efficient file storage. Quick overview of our input data processes are as follows: • Build Dictionaries with business tokens • Use Dictionary with business Tokens as vocabulary and communication tools • Business tokens are used in parsing input data • Input data are parsed and divided int segments • Each segment has its structure, logic, token, fields and value tokens • Values of segment fields are split into value categories as follows: 1. Segments fields which would be converted into bit values 2. segments fields which would be converted into int values 3. Segment fields Strings values = string value 4. Segment field which are images = converted into frames 5. Segment fields which are reports = stored as is 6. Common segments = shared segments fields Examples (A Medical Record): A personal medical record with a number of surgeries, doctors and surgent statements, x-rays images, blood work, ..etc. Our Goal: Our goal is to convert such a complicated long record with detailed doctors and surgent case descriptions, blood and lab works, .. etc, where we would be converting the fields values of such a record into integers numbers, bits records, indices, hash number for faster processing, compressions, cross-references, and other search criteria. A medical record example conversion:
These segment values can be stored into: 1. All in one file as separate text records 2. Each in its own text file(s) 3. Each file name is a searchable string or integer value Images are segmented into frames - see my oil and gas frame search: Oil and Gas Refinery Commons: Common data is the creation of a shared understanding of data. They are critical where data is to be shared between different systems and or groups of people, for example, patient personal information. We use Dictionaries Tokens as indices for common data sharing. Handling Data Analysis, Storage, Size, Updates, Performance, Machine Learning and Security: We are architecting our data storage and handling to address all the Big Data issues. As for Hadoop and databases issues, see section Dental Implants Platform Components Analysis (6. Data and Big Data) in this page. We proposed that we would be converting most of data into text and store the data in text files using Network Attached Storage (NAS). For sound and other data type format, we do need to brainstorm with experts for optimization. As for images, we our frame approach would perform well in search and analysis. We need to address the following points or possible issues: 1. Data Type Analysis - Manual and Automated 2. The Continuous Updates 3. Tracking Data Changes and Shifting 4. Ability to Change Data Type on the Run 5. Machine Learning Tools 6. Security Data Type Analysis - Manual and Automated: The number of fields in the Regenerative Medicine and data types are quite a handful. We also need to work with medical professionals and researchers who would be using these data fields and see what is best choices and options for optimum results or performance. We do need to brainstorm data conversion types into bits, integers, indices, hash numbers plus manually run a number of tests for best performance. Once, we have the optimum types, then we would automate and use ML to perform the conversions. The Continuous Updates: Updating Big Data is timing consuming and error-prone plus which updates must be done in Realtime and which would be batched. We would be building update tools and use ML to perform the updates for both Realtime and batches. We also run virtual testing to check our updates tools performance and accuracy. Tracking Data Changes and Shifting: Updates, changing data types on the run, and testing for performance and accuracy must be tracked and analyzed to figure out any trends and tendencies for data update and changing data types. For example, let say that we converted blood types into bit values and as time goes the blood categories started to outgrow the bits sizes similar to Year 2000 (Y2K) issues with Lagacy system. If we decided to change to an integer value, then we need to check what issues could we be running into again. Therefore, any change must be addressed and forecasted for future changes. Updating Text Files Fields Values for New Types Changes: We believe that changing text values in text files is fast and accurate and possibility with no issues. For example, if we would be using Comma Separated Value (CSV) files, the changes and updates would be fast also. Ability to Change Data Type on the Run: What we just addressed must be automated and tested. ML would be used for updating, changing and testing. Machine Learning Tools: ML tools are must and would be performing most if not all the detailed tedious work. Security: See our security sections. Data Bank and Library Input-Output Structure Tiers 
Data Bank and Library Input-Output Structure Analysis- Image #11 Image #11 represents our data bank and library structure with the goal of providing any data service for any client needs. Each tiers-levels are structured to take data in any format and process them into any form our clients would request. We also build Java or Python engines as reusable components which can be integrated in any running system. These Java and Python components can interface and run independently within any running system. Security is also part of these reusable components. API Pos and Cons: What is Data API (Application Programming Interface)? API is the acronym for application programming interface. It is nothing more than a data communication hub for software applications as well as devices to receive data or services. Pros: APIs make data available for use plus it is a big saving in term of coding and programming. Cons: 1. Customization 2. Bugs 3. Performance issues 4. Possible security risks 5. Additional Complexity 6. Single Point of Failure 7. Latency 8. Vendor Lock-in 9. Cost 10. Maintenance Overhead 11. Configuration Complexity There are issues with common data or languages blockades for different institutions, fields, businesses or even between teams. Data Business Dictionaries: Regenerative Medicine fields are very diverse and players may not speak English. This requires that we create Dictionaries which have parsers and converts services to help with both communication in any human or programming languages and data structures and data types. Our Data Matrices: A matrix is a two-dimensional data structure and all of its elements are of the same type. Use business data values and parameters and convert them into integer or log integers values. We would populate the matrices with such values which can be easily compared and cross-refenced with speed. In short, we try to convert everything into an integer value. Index: Indexes are used to quickly locate data without having to search every row in our matrices every time matrices rows are accessed. Indexes can be created using one row of our matrices, providing the basis for both rapid random lookups and efficient access of ordered records. Hash Function and Hash Number (within our matrices): A Hash Function is a function that converts a given numeric or alphanumeric key to a small practical integer value. The mapped integer value is used as an index in the hash table. In simple terms, a hash function maps a significant number or string to a small integer that can be used as the index in the hash table. Our Index Verse Our Hash Number: Index is used to locate a row in our matrices. Hash Number is a field value for retrieving the actual data if needed. For example, an address value with a zip code and person ID can be hashed into a hash number and that number would be located in the matrix address field or pocket. Input Data in Any Format Our Data Bank and library are data hubs for our clients. There would be continuous flocks of data to be deposited. Our system would be a data depot for any data format and size. Therefore, the input of the data depot would be controlled, accessible, available 24X7, secured, reliable, maintained, with flexibility in term of receiving all possible data input. It is vey much one-way traffic of depositing data. Our Data Depot IP addresses Matrices Scheduled: For security reason, tracking and monitoring possible hacking, we would be proving our clients with more of private group dynamic IP addresses to send data. Such dynamic IP addresses would be changed on a period basis and our clients would have such scheduled switching of IP addresses. For example, let us say that companies A, B and C would have communication or interface matrices with dynamic IP addresses scheduled to follow. Therefore, at scheduled time X, the data depot gateway would be IP address ZZN and clients would be switching to the new dynamic IP address ZZN. Such scheme of changing IP addresses and data depot gateways would help track any hackers’ attacks which would be automated to shut-down and switch IP addresses and control depot access. Plus, clients would be informed using automated system with the request of switching to different IP addresses. Input Buffer Virtual Cloud Buffer: What is a buffer and its advantages? Our Virtual Cloud Buffer: A computer buffer is a temporary memory space. A buffer helps in matching speed between two devices and between two data transmission. Our Virtual Cloud Buffer is a virtual server created as a Container. The main objective is to separate between the outside world and internal structure and services. The size of our Virtual Cloud Buffer is dynamic and flexible to handle any load. Each buffer has its own virtual IP address. Container and components would be running inside our Virtual Cloud Buffer and wiping our Virtual Cloud Buffer clean is one of its main features. Hackers and their code would not get further than our Virtual Cloud Buffer. The number and size of these buffers can be automated and controlled. Scanning Buffer(s) The main objective of buffers is to speed and balance processes and help input streams from being blocked or slowed down. All the input data would be buffere and buffers can also be dumped to backup system. Byte Scanning for Hackers and Malicious Code For more details see our pages: Object Oriented Cybersecurity Detection Architecture Suite Sam's Machine Learning Analysis, Data Structure-Architect Copy and Zipp for Storage, Tracking, History and Batch Analysis Once we cleaned the input data, we would zip the data and store it for backup and further analysis which would be adding more data analysis to our Machine Learning tools. Business Dictionary What is a Data Dictionary? A Data Dictionary is a collection of names, definitions, and attributes about data elements that are being used as the project knowledge base. It can be a part of any project including a research project. It gives any project: • Consistency in project communication • Helps standardize the business vocabulary • Helps standardize the business jargons • Builds a data standard • Helps in analysis • Provides metadata about data elements Building Dictionary Tokens with Integer ID: We would be converting dictionary data or terms into Tokens and give each Token an integer ID number. Data matrices would have fields with token ID as references and pointers to other matrices. Token ID: The same way we would be architecting security cookies, we would be architecting Token ID. Token ID is an integer value which would be broken into segments and each segment value has a meaning in the business handling. For example, Token ID = 123456987 123 456 987 Where each set of number is a reference and has a value and a meaning. Data Types IDing-Recognition - Data Segmentation Resume (CV) Applicant Tracking Systems (ATS): How does ATS parse a resume (CV)? An applicant tracking system (ATS) reads a resume and parses by electronically analyzing the text. It extracts key data like names, job titles, and education, making the recruitment process more efficient. With the same ATS principles, we would be parsing all income data including images and sounds. Our parsing would ID and divide the data into segments based on the business we are servicing. ML would be part of such effort. Parsing and Matrices Conversion Parsing: We do have experience developing programming languages compilers and our paring are performed in a number of levels. Each level would service a specific task. At this tier level of processing the input data where we have Dictionaries, Tokens and Tokens ID, several level of parsing, conversion to integers and hashing ID, then next level of processing would be building our processing matrices. These matrices would be nothing but data which are already processed and ready to be used in the next level of quality control, intelligence and automation. Cross Reference - Data Quality Scaling Our Definition of Cross-References: At this point in our system analysis is where we have converted the data into: • Integers • Bits • Indices • Hash values • Token IDs • Image frames • Sound segments • Misc We also load these values into matrices which would be running in memory for fast processes. Our Definition of Cross-References is: We would be running a number processes to check for: 1. Comparing two matrices 2. Finding matching values between matrices 3. Extract information from one list based on information from another 4. Check for unnecessary repetition of values 5. Find errors 6. Out of range values 7. Out of Date – wrong date 8. Outdated values 9. Same item but called by different names or number 10. Provision 11. Limits 12. Exceptions 13. Changes 14. Trends 15. Tracking 16. Variance 17. Standard deviation Data Quality Scaling: Our goal at this point is to build a scaling value for each data item we have. Based on our analysis, we would be scaling the accuracy of the data from 0 to 100 scale where zero is no value or wrong information, 100 is that: the data is 100% accurate. Our scaling would be based on the business we are processing and clients feedback and help in building such scaling system. Quality Control Data Quality Control (QC) is the processes that determine whether data meet overall quality goals and defined quality criteria for individual values. We are not the experts when it comes to Quality Control and Data Quality Control, but the following are our basic criteria and guidelines for Data Quality Control. We are open to any suggestions, help or guidelines. Machine Learning and Quality Control: The power of ML is that ML would be performing data analysis similar to human analysts. An analyst tasks are: 1) Data Collection, 2) Data Cleaning and Preprocessing, 3) Data Analysis, 4) Data Visualization, 5) Report Generation, 6) Data Modeling, 7) Data Quality Assurance, 8) Collaborative Decision-Making. Our ML tools have dynamic tasks or check points matrices which are used to analyze the data matrices. With speed of computers, our ML tasks are performed with speed, accuracy, precisions plus ML tools would create reports and help with decision making. As far as data storage and rollbacks, our ML would have storage or backup engines plus decision-makers and rollback engines which are intelligent and automated. Templates and Our ML: Collected data are used to populate Data templates or matrices which can also be performed by our ML. Data Accuracy: Data accuracy refers to the correctness and precision with which information is captured, stored, and used. Example: If a sport medicine was tested using teenagers whom have high energy and fast recovery. Then assuming that the same medicine would work for senior citizens without testing the medicine, may not be accurate. Such assumption is not accurate. The data collected for testing teenagers would not be accurate for treating senior citizens. Data Validity What is data validity? Data validity refers to the business rules or definitions which are used to define how accurate the data is. Therefore, the data must be relevant and represents the business value metrics it describes. Why is validity important? Validity describes: 1. How good are the tests used to test particular scenarios 2. Reliability 3. Trustworthy 4. There are valid conclusions which we can draw out of the data What is data validity in research? The validity of any research study describes how well the results of the study are true findings plus they are similar to other outside studies. Reliability: Reliable data refers to data that can be a trusted basis for analysis and decision-making. The processes for ensuring reliable data matrices are: 1. Segment data for analysis 2. Improve data collection 3. Improve data organization 4. Check for errors 5. Normalize the data 6. Cross-reference data with other fields Relevancy: Data Relevance (Significance, Importance, Applicable, Bearing, Weight) is the degree to which data provides insight into the real-world problem. Consistency: Data consistency is the accuracy, the completeness, and the correctness of data stored. What are the different types of data consistency? There are three main types of data consistency: 1. Point-in-time consistency 2. Transaction consistency 3. Application consistency Timeliness: Timeliness: Timeliness, as the name implies, refers to how up to date information is. Example of Timeliness is stock market prices or weather tracking. Integrity: Data integrity is a concept and process that ensures the accuracy, completeness, consistency, and validity of the stored data. Conformity: Data Conformity measures how well the data aligns to internal, external or industry-wide standards. Example: Conformity means the data is following the set of standard data definitions like data type, size, and format. Data Cataloging Data Cataloging: What is a catalog? In short, a catalog is list or a collection of organized items with flexible searching and filtering options to allow users to quickly find relevant sets of data. There are different types of catalogs such as fashion, service, product, business, data, sport, research or even stem cells catalogs. Each catalog is design for a specific audience. What is a data catalog? Data catalog is a tool which helps users locate data. Who are the Users of Our Data Catalogs: Researchers, medical professionals, companies, governments, ML, universities, students, investors, social media, ..etc. What is a good data catalog? A good data catalog provides: Search and discovery. A data catalog should be flexible for searching and filtering options which allow users to quickly find their target goals. Users can also examine the target data based on a technical data structure. Our Data Catalog is: An intelligent automated virtual cloud tool for researchers, medical professionals, companies, governments, ML, universities, students, investors, social media, any person or institution to communicate with plus receive reports, proposals, documents, publications, emails, links to webpages and FAQ. In a nutshell, our data catalog is a cluster of cloud-based interfaces which provide the following: 1. Brochures - webpages (including videos) 2. Information Pages 3. Q&A 4. Reports 5. Sample Data 6. Proposals 7. Processes 8. Procedures 9. Experiment 10. Issues 11. Equipment 12. Request-Provider Services 13. Automated ML Template Matrices 14. Software Tools (API, ML, DAO, Parsers, Converters, Analytics) 15. Training 16. Free Data 17. List of data vendors, researchers and brokers 18. Latest on researches 19. Data 20. Common Data 21. Researches 22. Documentation These cloud interfaces would be automated and intelligent. For example, a ML would be able to search our data bank ML matrices and it can also submit a request for proposals on a particular research or experiment. Internet and mobile browsers can browse our webpages, brochures or QA pages. As far as the mechanics of how payment and credits would be handled, we need to brainstorm such processes. Formatting Analysis and Engines Matrices Building This tier or level is the preparation and the development of our data services. We start building tools and output data format as services. The core of our ML operations are the matrices. Theses dynamic matrices are spine-cord of our ML system. Operation Matrices - The Spine-Cord of Our Machine Learning System Our ML consists mainly from preparation processes-engines (Search Pattern Builder or Engine), scanning and work engines (Sort, Tracking, Evaluation, Decision-makers, Execution, Store-backup, and Lesson Learned). These components produce and consumes data stored in Matrices. Our Matrices are lookup boards of information. We would be creating Matrices from other Matrices. In the case of delay of populating a given Matrix with latest information, then there would be using the default values based on previous experiences, statistics, and weight value. For example, if the blood type is not available during one the medical data matrices processing, then default type would be O-positive (O+) which is the most common blood type by average percentage. We also may need the approval of such defaults by the medical professionals. Revisit - How can we build an intelligent system? In a nutshell, the following steps or processes are what defines "Human Intelligence" which is the ability to: 1. Learn from experience 2. Adapt to new situations 3. Understand and handle abstract concepts 4. Use knowledge to manipulate one's environment Let us look at our architects components for each of "Human Intelligence" step or process. #1 - Learn from Experience: 1. Preparation Processes 2. Search Pattern Builder or Engines 3. Sort Engines 4. Tracking Engine 5. Evaluation Engines #2 - Adapt to New Situations: 1. Decision-makers Engines #3 - Understand and Handle Abstract Concepts: 2. Decision-Makers Engines 3. Execution Engines #4 - Use knowledge to Manipulate One's Environment: 1. Execution Engines 2. Store-Backup Utilities 3. Lesson Learned Engines 4. Reports Engines We would be developing Matrices for each of the Human Intelligence steps. Matrices Fields and Values: Our Matrices will be used by human and machine; therefore we need to find a common fields names and values. Tracing and debugging would be done mainly by human. The key is not to slow the processing speed and not confuse the administrators, analysts, staff, ..etc. The following are pointers in field name and values choices: 1. Processing speed 2. Human comprehension 3. Ranges should 0-9 not in the 1,000th 4. Less use of percentage and use of meaningful words 5. Numeration which human can relate to - good, bad, damager, ..etc 6. Default values 7. Statistical Values human can comprehend 8. Tedious calculations are done by machine 9. Accuracies and percentage of accuracy Field Possible Values: Based on the actions requires different Matrices would have different fields, names and values: The following list is start where it would grow as we run and learn more: 1. Range 0 -9 2. Numeration of Range - Good, Bad, ... Normal, Al 3. Messages 4. IDs 5. Weight 6. Index 7. Flags 8. Matrices ID 9. IP addresses 10. Hash index 11. Contact information 12. Processes Indexes 13. Alarm indexes 14. Frequencies Building Matrices Templates: Templates are great tools in analysis, development, automation, testing and training, we would be brainstorming template's structure and development. Matrix List for "Human Intelligence" step or processes: #1 - Learn from Experience: 1. Zeros-&-Ones 2. Patterns 3. History hackers and attacks, tendencies, source of attack and hackers code 4. Search Patterns 5. Emulator output of possible scanned values 6. Evaluating Emulator Output and Zeros-&-Ones #2 - Adapt to New Situations: 1. Tracking Source 2. Tracking Routing 3. Audit Trail 4. Cross References #3 - Understand and handle abstract concepts: 1. Decision-makers 2. Execution Steps #4 - Use knowledge to manipulate one's environment: 1. Setting Alarms 2. Vendor contact information 3. Client Contact Information 4. Lesson Learned 5. Reports indices Matrices Pool Management: Analysis, Evaluation and Storage: If we do an analogy of how important our Matrices is, we would state our Matrices Pool is the spine-cord of our intelligent system. They are the connections between all the processing, learning, tracking, analysis, updating, storage, audit trail and misc. Matrices Pool Management is critical to their performance. Matrices Pool Management would be performing and evaluating the following fields: 1. Assigning ID 2. Performance 3. Storage 4. Analysis 5. Updating 6. Validation 7. Bottlenecks 8. Redundancies 9. Overkill number of matrices Matrices Management and Matrices Synchronization: Programming Synchronization Issues: Programming Synchronization and concurrency issues are problems that arise when multiple threads access or modify the same data or resources without proper coordination. For example, if two threads try to write to the same variable at the same time, they might overwrite each other's changes and cause data corruption. Our Approach to such Programming Synchronization issues is that our ML engines run in levels or processes, which each level would be able create the needed matrices even with defaults data value in case the needed matrix field values were not calculated. Such processes and level must be approved and tested by clients and analysts for the ML engines performance and accuracy. Output Formatting Engines (Data Bank and Library Products) At this tier or level, we are presenting our Data Bank and Library products for the world to license, purchase, or even browse. We would like to add that we are not alone nor we are working in a vacuum. At this point: What we have is: our architect-design plus we do not have running products yet. Our goal is to present our concept (Data Bank and Library), the know-how plus show how doable our system would be. Our audience must envision our system and be able to see the Return On the Investment (ROI). We as a team of IT professionals who have put together such an effort and the thinking without any resources nor support. With adequate resources and support, we know and we are sure that we can make our system a reality with a fraction of cost of any data vendors and within a short time. What makes any product better than others? A product competitive advantage could be based on the product quality, functionality, design, innovation, price, service, brand, or reputation. Also, any competitive advantage should be relevant, sustainable, and defendable. Searching the internet looking for the top data brokers, data banks or data services, which would be offering their clients and post them against our Data Bank and Library products and services. We also add the fact that we are not dealing with personal data nor would be violating any privacy.
The Difference:
Our quick review of what is an engine: What is an Engine? What is a Process? Based on Information Technologies background, an engine may have different meanings. Engine Definition: • An Engine is a running software (application, class, OS call) which performs one task and only one task • A Process is a running software which uses one or more engine. A Process may perform one or more task • Engines are used for building loose coupled system and transparencies • Updating one engine may not require updating any code in the system • A tree of running engines can be developed to perform multiple of tasks in a required sequence • Engines give options and diversities Data Formats: Our data format presentation: 1. ML Matrices: See ML documentation in this page. 2. Java Data Access Object (DAO): DAO Design Pattern: DAO Design Pattern is used to separate the data persistence logic in a separate layer. This way, the service remains completely in dark about how the low-level operations to access the data is done. Java Reflection: Reflection is a feature in the Java programming language. It allows an executing Java program to examine or "introspect" upon itself, and manipulate internal properties of the program. For example, it's possible for a Java class to obtain the names of all its members and display them. Our approach is very simple and simply put: Use Data Access Objects (DAO) as storage and save these objects into a file. These DAO files can be loaded in memory and run within any application as array of DAOs. This helps speed the loading of data into any running Java application. Java Reflection can be used to develop API to access DAO on the run. 3. Java Set: In Java, a set is a collection that does not allow duplicate elements and has no guaranteed order for its elements. The same concepts used in DAO can also apply to Java sets. Java Reflection can be used to develop API to access Java Set on the run. 4. XML: See the following page: Database Replacement Using XML 5. JSON: JSON is an open standard file format and data interchange format that uses human-readable text to store and transmit data objects consisting of attribute-value pairs and arrays. It is a common data format with diverse uses in electronic data interchange, including that of web applications with servers. 6. Text: Data as text files. 7. CSV files: Comma-separated values is a text file format that uses commas to separate values. A CSV file stores tabular data in plain text, where each line of the file typically represents one data record. Each record consists of the same number of fields, and these are separated by commas in the CSV file. 8. Message Queues: Message Queuing allows applications to communicate by sending messages to each other. The Message Queue provides temporary message storage when the destination program is busy or not connected. 9. C-Tables (same as database tables - text rows and columns): An array or a table in C is a fixed-size collection of similar data items stored in contiguous memory locations. It can be used to store the collection of primitive data types such as int, char, float, etc., and also derived and user-defined data types such as pointers, structures, etc. APIs can be developed to access the table data. 10. Data Table - Metadata: Tables describe the kinds of data stored in the database. Table metadata is what controls the kinds of records you can create and what kind of actions can be performed on them. APIs can be developed to access the table data. 11. Customized Format: We are open to develop or build any format. 12. Misc - We are also open to other data format: We are open to develop or build any format. 13. Image Analysis-converting images to text: We need the software which would perform such tasks. 14. RDF, YAML, REBOL, Gellish: Resource Description Framework (RDF): RDF is a standard model for data interchange on the Web. RDF has features that facilitate data merging even if the underlying schemas differ, and it specifically supports the evolution of schemas over time without requiring all the data consumers to be changed. Yet Another Markup Language (YAML): Depending on whom you ask, YAML stands for yet another markup language or YAML it is not a markup language (a recursive acronym), which emphasizes that YAML is for data, not documents. YAML is a popular programming language because it is designed to be easy to read and understand. Designed for human interaction, YAML is a strict superset of JSON, another data serialization language. But because it’s a strict superset, it can do everything that JSON can and more. One major difference is that newlines and indentation actually mean something in YAML, as opposed to JSON, which uses brackets and braces. Relative Expression-Based Object Language (REBOL): A programming language that runs on a variety of platforms. Created by Carl Sassenrath, REBOL is a very concise language both in syntax and in implementation: the entire development system fits in only 200KB. Gellish: Gellish is an ontology language for data storage and communication, designed and developed by Andries van Renssen since mid-990s. It started out as an engineering modeling language (Generic Engineering Language, giving it the name, Gellish) but evolved into a universal and extendable conceptual data modeling language with general applications. Because it includes domain-specific terminology and definitions, it is also a semantic data modelling language and the Gellish modeling methodology is a member of the family of semantic modeling methodologies. This enables software to translate expressions from one formal natural language to any other formal natural languages. |
|---|