Executive Summary
Our approach is to convert the Java data objects into XML stream (text) and store the XML
stream into the database XML data type field. The reverse is very much the way from XML
data field to XML stream and XML stream to Java data objects. This is very simple and direct,
but we need to have our database tables are as follows:
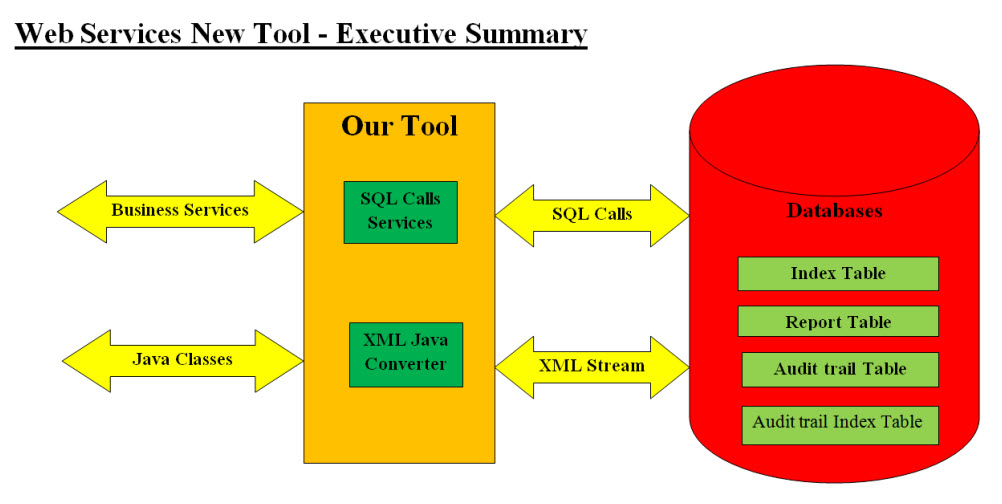
• Index Table
• Report Table
• Audit trail Table
• Audit trail Index Table
Our approach is to move the data into Java data objects in memory for direct processing without any database processing
or conversion (Normalization and Denormalization). We moved the entire processes into Java control and the database
processes and conversion are eliminated to XML retrieval and SQL calls.
Our Simple Approach:
go to top
The Problems
Our approach and tool have an uphill battle and the following are some of the reasons:
|
•
|
Replacing web services, XML files, Hibernates, normalizing, de-normalizing and the overkill of database tables, fields and search with one tool is too good to be true. Actually, it sounds impossible.
|
|
•
|
A big and if not even a bigger handicap is the mentalities and attitudes of IT professionals toward a new approach and especially if they spent their entire careers building database tables and SQL code to handle these tables, web services and existing approaches.
|
|
•
|
The fact is a large number of companies have bought into tools and utilities such as Hibernate and supporting IDE and
changing to a new approach might be costly in term of time and retraining.
|
|
•
|
The new approach and tool must be both an idiot-proof and bullet-proof and worth looking into.
|
|
•
|
How can the new tool and approach compete with Sun-Oracle-Java ever-changing web services and their APIs.
|
|
•
|
How can our tool and approach simplify the XML communication exchange between companies and platforms.
|
 go to top
The Existing Solutions
go to top
The Existing Solutions
There are quite a number of approaches to web services and database access and venders as Oracle,
Hibernate, Microsoft and other software venders lead the way with ever-changing tools and approaches.
The standards are somewhat set, but there is room for changes. It seems that market leaders rename
and reshape the same products and then sell them back to the IT community without real significant benefits or
advances.
go to top
The Goal and Standards
Our approach and tools are our attempt to simplify the existing tools and standards, we are not reinventing
the wheel, but we are using the latest to help make the conversion between Java objects, XML, database access
and communication between venders and platforms a simpler and more of homegrown services that address the ever
changing needs and technologies.
go to top
Our Approach
In a nutshell, we need to present our approach and show that it is worth looking into. We need
to cover some of the existing approaches in order to present the benefits from using ours. We
will quickly cover the following pointers and we request that the readers should not get caught
into the details by approving or disapproving our material or they may use different techniques:
|
•
|
The Traditional Data Access Approach
|
|
•
|
Hibernate Approach
|
|
•
|
XML Communication - SAX, DOM and The Latest
|
|
•
|
Data, Databases, Data Fields and Java Data Objects
|
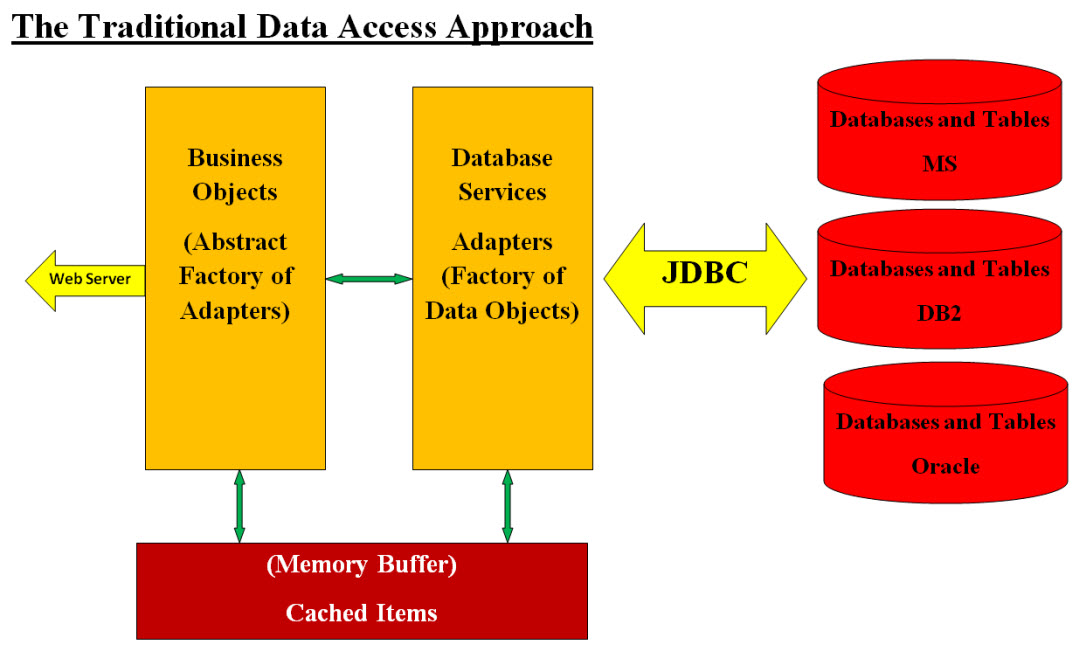
The Traditional Data Access Approach
The following is a quick view of the Traditional Approach:
|
|
Business Object - BO (Abstract Factory of Adapters):
BO Creates the business objects which could contains arrays of numerous Data Objects. BO may call several Adapters to handle their tasks.
|
|
|
Adapters (Factory of Data Objects) - Database Services:
Adapters are the bidirectional communication links between the BO and a number of databases.
|
|
|
Normalization and Denormalization:
These are two strategies for dealing storing and presenting data. The preferred method is
to keep the logical design normalized, but allow the database management system (DBMS) to
store additional redundant information on disk to optimize query response. As a simple example,
dates could be stored as a long integer in the database, where it will be converted to MM/DD/YYYY
or some other format to be used in the User Interface (UI) section of the presentation layer.
|
|
|
JDBC Bridge:
Java Connector and the Bridge to databases.
|
|
|
Databases (tables within each database):
Each database may contain several tables and in turns the tables may contain several
fields. The fields would be of different types and format and so on. The database design
could be an complex system with an overkill of tables and fields. There is also a debate
on which process should be done on the database side or the Java side. Some database may
have stored procedures that must be updated and tested for reusability.
|
|
|
Caching and Persistence:
There are many ways that allow you to specify how long items last in the memory or in the
database before being deleted. How large the cache can get, and price for cleaning and
maintenance must be also addresses. There are pros and cons for Caching and Persistence
and applications architects and developers should address these pros and cons.
|
Hibernate Approach
Hibernate basically eliminated some of the steps and issues that mentioned in the
traditional approach such as building Adapters, JDBC and Cashing. In fact Hibernate
freed the developers from a number of tasks. Nevertheless, Hibernates has performance
and reusability issues. We believe that we can actually build a better tool than Hibernate.
XML Communication - SAX, DOM and The Latest
There is a number of great tools that help XML communication plus Java had provided
enough APIs that makes developers' life easier. The not so positive note on these
tools is the fact that they are constantly changing without an end and sometimes the
new tools are adding more confusions than answers. Again, the IT community is being
herd like sheep without much of a choice.
Data, Databases, Data Fields and Java Data Objects
Looking at the traditional approach and current tools, regardless of the task, any application
has to deal the databases, data and its fields and format and in the case of Java technology
Java data objects are the entity vehicle. XML is the current communication media. We may need
to ask ourselves the following questions to help us with our approach:
|
•
|
How can a tool give us the ability to edit the data with different data fields from any database using Java data objects?
|
|
•
|
How can a tool give us the ability to share the data with different data fields from different databases between different companies and on different platforms?
|
|
•
|
What is XML Data Type?
|
|
•
|
What is Character Large Objects (CLOBs) field?
|
|
•
|
Can our tool use the XML field or the CLOB (basically text)?
|
|
•
|
Can we store and/or retrieve a stream (file of text) of XML file into the database XML field ?
|
|
•
|
Can we perform SQL call on the XML field or the CLOB?
|
|
•
|
Can we use database management system (DBMS) to optimize query response on the XML fields?
|
|
•
|
What kind of performance and trade of such approach would yield?
|
|
•
|
Can we standardize these fields and their functionality and help data communication between companies and platforms?
|
|
•
|
What do we have as standards when it comes to data and data objects?
|
|
•
|
How can we use these standards to build our tool?
|
|
•
|
What are the design criteria using the XML fields and Java data objects?
|
|
•
|
Should we build Data Communication Standards for the world to use?
|
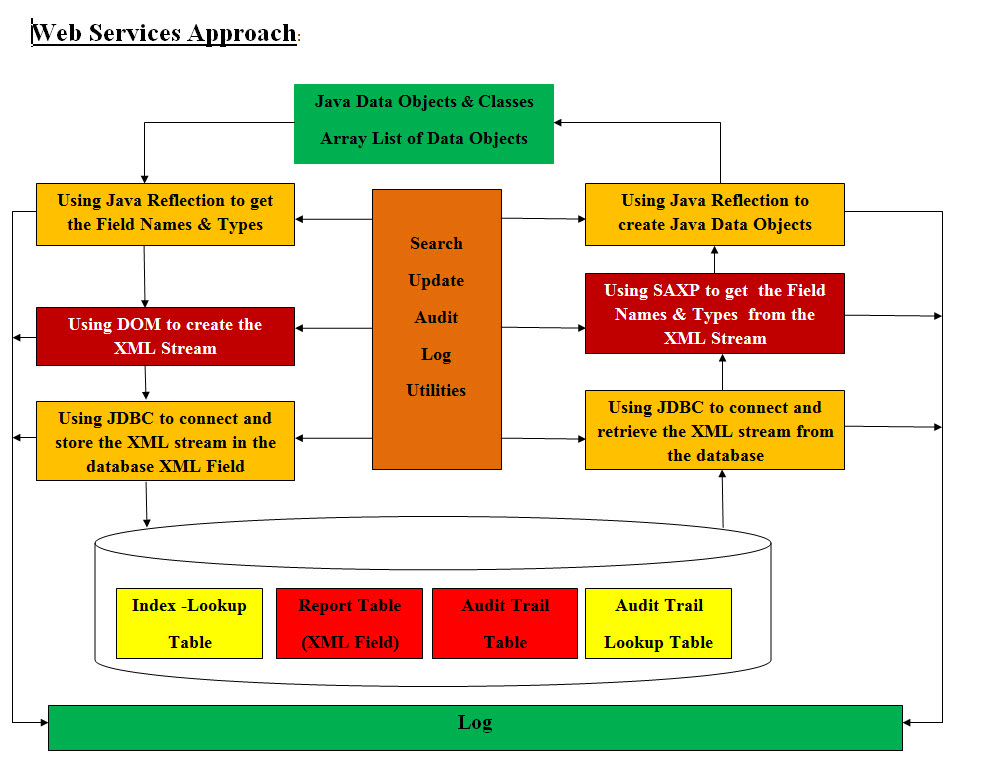
Our Answers and Approach
The answer to these questions based on the fact that if a tool can move Java data objects in and
out databases then our job is done. Such tool can also be used to provide the data fields from Java
data objects so any company or platforms can use the data as they pleased.
Currently, XML is used to perform such tasks, but our tool will use Java data objects in XML files
with XML format. We will be using SAXP, DOM and Java Reflection to perform the conversion from Java
data objects (or even arrays of data objects) to XML files and back with one easy step.
We need to build some sort of standards of what each Java data object should be and how they should
be handled. Java provides their data object with get-set methods and Java Reflection provides the way
to use these get-set methods to be edit data objects. We also need database that has data fields that
can store one or more Java data objects. See our Web Services Approach diagram.
|
|
XML Data Type - Database Fields:
Can we store and/or retrieve a stream (file of text) of XML file into the database XML field?
The answer is: we can use what is known Character Large Objects (CLOBs) field. It is a stream
of text. We may also use XML data type fields. Not all databases support such fields, but the one that
does, may store data ranging in size from zero bytes to 2 gigabytes.
|
|
|
What can we do with XML Field?:
Before databases exists, developers used text as well as binary files to store data
to hard drives (Persistence). All the search, updates and other functionality were
done on these text or binary files. With the new XML field and database support for
handling this type of field, the query calls to this field would open doors that help
eliminate numerous tables and overkill of fields and redundancies. See the Design
Criteria for more details.
|
|
|
Design Criteria for Database Tables and Java Data Objects:
The best way to illustrate the design criteria is present our approach to Credit Repair
Project. The project basically communicates with the three credit bureaus, but for our
illustration example we are presenting the TransUnion bureau request-respond using the
following:
• Fixed Format Inquiries (FFIs)
• Fixed Format Responses (FFRs)
The FFR may contain up to 80 segments and each segment may have up to 360 fields and each
field have up to 15 possible choices. To parse one FFR, our design can have up to 80 Java
class and each class have a number of array lists with different Java data objects. To store
these classes into database tables may result into hundreds of tables and their complex data
types. In this system, the real-time SQL calls and database services may have serious issues with performance
specially if the system's goal is having up to 100 million records.
The Normalization and Denormalization of the database table can be another performance
concern. Our approach was to convert the Java data objects into XML stream (text) and
store the XML stream into the database XML data type field. The reverse is very much
the way from XML data field to XML stream and XML stream to Java data objects. This is
very simple and direct, but we need to have our database tables are as follows:
• Index Table
• Report Table
• Audit trail Table
• Audit trail Index Table
Our approach is move the data into Java data objects in memory for direct processing without
any database processing or conversion (Normalization and Denormalization). We moved the entire
processes into Java control and the database processes and conversion are eliminated to XML retrieval.
See the Database Services for handling the XML editing.
|
|
|
Index Table:
It has record ID, and most of the quick lookup fields and the number of fields should be small.
|
|
|
Report Table:
It has record ID, and the report (XML stream) field.
|
|
|
Audit trail Table:
It has record ID, audit trail (data and ID), user ID and time stamp fields.
|
|
|
Audit trail Index Table:
It has record ID, audit trail index, user ID and time stamp fields.
|
|
|
Logical Business Unit:
Logical Business Unit for our TransUnion Credit Repair Project was FFR with all its Java classes and the four database tables.
|
|
|
Database Services:
The database services should be a collection of SQL calls that service the four tables and
the outside world (different companies and platforms).
These database services should implement the system dynamic business rules and create JARs
files and their documentation which would be given to other venders and companies to use.
|
go to top
The Code and JARS
To show the details of how our approach is done in Java using both Reflection, SAXP
and DOM, we need to present the actual Java code. Our one-to-one conversion from
MyFirstBean Class to MyFirstBeanXMLFileConversion.xml in the Data Objects section
is a good example of how we did the conversion.
The code is actually is very simple and straight forward.
Constants.java
MyFirstBean.java
MyFirstBeanDOM_XML_Converter.java
PrimitiveFieldTypeDataObject.java
SAXParseDataObject.java
FieldsParser.java
SAXParse2MyFirstBean.java
Readers my request the JAR files for the more complex conversion by emailing a request to:
go to top
Pros & Cons
This is a new concept and approach and we are trying to help clear important points and concerns by providing the Pros and Cons.
|
Pros
|
Cons
|
Number of Tables:
The goal of using the XML Report field or CLOB is to reduce the number of tables and with that accessing data would be faster and easier.
|
The search and editing of data may need special care and code and reusability may be difficult and more complex. |
Master Index and Reports Tables:
Reducing the number of tables to only two is definitely a big plus. The Mater
Index table should contains the most requested data to help reduce the retrieval
of the Report table and creation of XML stream. For example, last name or credit
score can be frequently accessed, but the rest of credit card information may
not have the same frequency as the credit score or the last name.
|
The design of data objects and services would require special care and if the
structuring of data and fields are not done well then such code and tables may
not be of use to other projects or data may become application dependent. For
example, creation of data objects has to be design for reusability and can be
used in other applications. The Report table should not contain all the fields
which would result in an overkill of fields within the Report and looking for
simple data would mean the conversion all the XML Field into a number of data
objects that are not needed but takes time and occupy memory space.
|
Speed:
The speed is definitely on the side of the two table access.
|
Special care must be taken.
|
Java and Database Conversion:
There are no conversion (Normalization and Denormalization). We would move the entire processes
into Java control and the database processes and conversion are eliminated to XML retrieval.
|
None, but reusability may be an issue.
|
Thinking in Business Unit:
Thinking in Business Unit in my opinion is the best approach to handle business units and data access.
|
Thinking in Business Unit is a concern and things can get messy and reusability can
be more complex than it should. For example, of think of name, address, SS number and
age as a base business unit that may fit in other the business cases then we need build
base business units with business units. This may make life more complex, application
dependency may result of such structure and reusability may be difficult to implement.
|
Creating Structured Business Units:
OO, Structured and Reusability are the way to go and applying the same approaches to
business units is definitely the best practices. This may be a new start of Object Oriented
Business Units and a new standards of looking at data.
|
Analysts may not think in these terms - OO, Structured and Reusability.
|
Data Access (Editing and Search):
Faster and SQL services is the key in making it a success.
|
Special care must be taken.
|
Inheritance, Utilities, Reusability, Scalability and Expandability:
Moving fields from the database into data object running in memory is the key
advantage of our approach, which will help Inheritance, Reusability, Scalability
and Expandability. For example, creating a utility that would load up a number of
base data object can boost Reusability. These base object can be part of bigger
applications which boots Scalability and Expandability. As for inheritance, the
creation of base classes that can used within the SQL services as well as database
access services.
|
No one may think in these terms when come to database services.
|
Database Services (Queries and Calls):
It is a new approach and database teams' ingenuity is the key.
|
New thinking.
|
Security:
Not an issue as far as we can see.
|
No comments.
|
