
Sam Eldin |
CV - Resume | Tools 4 Sharing | Architects 2 Show | Big Data Presentation | Android Training | Java-Unix Code Templates | Interviews QA & Code |
|---|
|
|---|
|
Database Replacement Using XML
To make our presentation short and sweet, if anyone searches Google looking for top issues with databases and top issues with Hadoop, Google search pages will display the followings:
Database Storage and Data Objects Issues 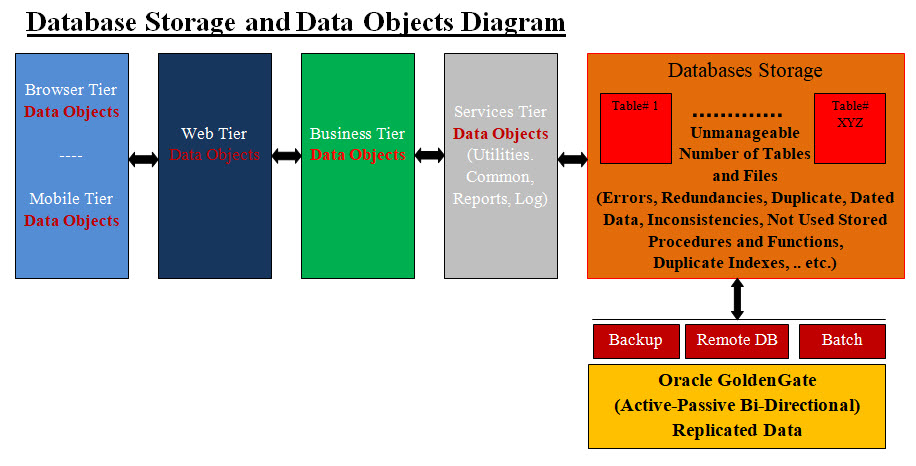
Image #1
Our Database Replacement Using XML and NAS: As we stated in the introduction of this page that data, databases and Hadoop are literally out of control with no clear solutions or answers insight. They are running in circles plus they are overwhelming the infrastructure. In short, their performance is going downhill fast. Both data vendors and the IT community need think outside the box and stop using their old database approach and tools. They should stop thinking in databases as the only data storage that can be used or worth investing into. Sadly, IT hiring managers and development teams are also stock in this old thinking, approach and technologies. We had a hard time convincing anyone (even close colleagues and friends) to view-envision any running system without tables, fields, SQL or databases. Our approach is very simple and simply put: Take data out the application and make it intelligent and self contained services. Use Data Access Objects (DAO) as storage within an Intelligent Data Access Object (IDAO). Such an intelligent independent service would free any running application from working with data, data security and data storage. It would also help standardize data as a service. When it comes to storing data or DAO we would simply store DAO in XML form. Such DAO to XML conversion using SOAP is straight and fast conversion. The reverse XML to DAO is also as fact and simple. No schema, any SQL calls or stored procedures, .. etc. To see our view point, the IT community needs to look at data services as two parts: • Data stored in XML (text) which is the standards in sharing data • Intelligent data objects (our IDAO) which provide data service to any running application The conversion of XML to DAO and DAO to XML is a straight forward process, no need to any gimmicks. Data and all its concerns is eliminated from any application. Data is stored in text files using XML (world standard). These text files can be stored on any file server and/or NAS. We have architected storage filing structure with search and fast look up design and code. The design and code are simple to develop and simpler to use. Security can be implemented using compression and encryption. Our DAO and IDAO would help standardize data usage, exchange and data communication. 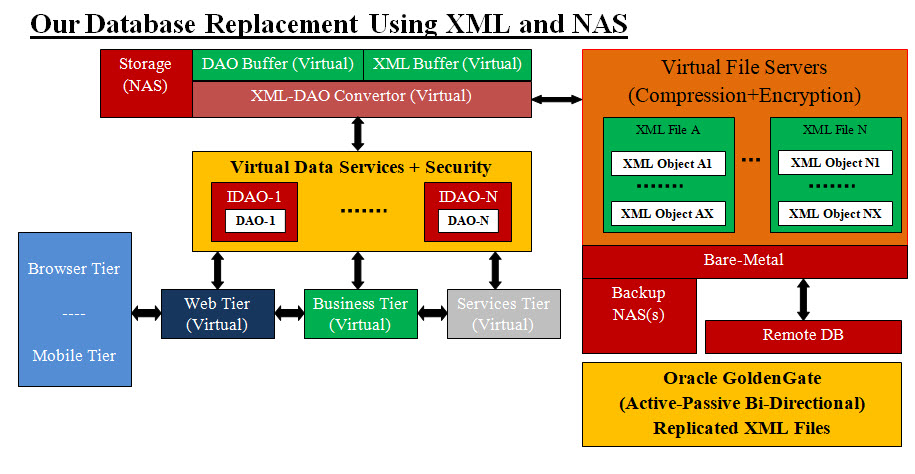
Image #2 Looking at Image #2, there is a clear line which separates data services and any running application. Our Virtual Data Services would provide both data or data answers to any running application. The fact that our Data Services is virtual, means that creating any number of its instance dynamically on the run to handle any horizontal scaling. It would be done with ease. Any real world cloud load would be handled without any issues. As for vertical scaling of our Virtual data Services would be transparent plus refactoring would not alter the external behavior. To eliminate Our Virtual XML-DAO Convertor from bring a bottleneck and impact performance, we architected our Virtual XML-DAO Convertor with buffers and NAS storage to help speed performance plus Persistence and Memento (undo or rollback) Design Pattern. Our Virtual File Servers do not require any anything which database servers would require. Our Virtual File Servers are architected with simple functionalities and services, no schema, no stored procedures, no SQL injections nor any complex access or usages. Both Bare-Metal servers and NAS are the only limiting factors in vertical and horizontal scaling. Communicating with the outside world, remote system or Oracle GoldenGate is simplified to file exchange. Comparing with Hadoop, anyone can see the simplicity and ease of using our Virtual File Servers. We can state with confidence that Big Data issues are still persisting regardless of the use of the top of the line databases or Hadoop and all Hadoop's hip. Our approach and answers to Big Data, databases and Hadoop issues are as follows:
Our approach is revolutionary and doable with low cost of development and integration. Stakeholders need to look at our approach and take the inchoative by teaming up with us. As one team, we can build a pilot project perfecting our solution. We would be taking the first steps in building intelligent data services which address Bid Data, CRM, BI and end the use of databases for good. |
|---|