Tests and Interview Questions Recycling (over 1,500 questions)
Executive Summary - Definition
Recycling : convert (waste) into reusable material.
Synonyms: reuse, reprocess, reclaim, recover; upcycle; salvage, save.
Object Oriented Design (OOD): Recycling in OOD could also mean reusability.
In reality, Recycling is the process of making use of items thrown away.
Recycling can also be translated into using templates and nothing is wasted, but can be reused at a later time.
Tests and Interview Questions: Tests and Interview Questions are a necessary evil that job seekers have to perform to show their talents.
Sadly, most interviews' material is a total waste.
With over 15 years in the IT field, I have taken my fair share of Tests and Interview Questions.
So, I decided to recycle all of them and post them on my site for
the potential employers, colleagues and myself as both a testing-questions-training and review of interviews.
Note:
My attempt is to make my Recycling simple and short otherwise I need to write
over 50 books. My presentation would be as follows:
Q&A + Short Explanation
Java Projects or Packages
Templates
Sample Code within a Java project or Java package.
Architect Image
Sam's Tests and Interview Questions Recycling List:
go to top
Abstract Classes and Interfaces
What's the difference between an interface and an abstract class?
This question has two part, the Concept of both of an interface and
an abstract class and the second is what I call the Mechanics.
Concept:
Java interface is a user defined data type composed of zero or more “final static” data
member (constants) and zero or more “abstract” member methods. It is more of a Java class
with constant data members and member method signatures.
An abstract class is a class that is declared abstract—it may or may not include abstract
methods. Abstract classes cannot be instantiated, but they can be sub-classed.
Interface is used for the following:
Consistency: By implementing an interface, that would grantee consistence.
For example, to implement a Java Virtual Machine (JVM) and have the same looks and
feel, Sun Microsystems had required JVM vendors to implement a number of interfaces
regardless of the language used (Assembly, C, C++, or even Java) to build the JVM.
Grouping:
By implementing an interface, the implementer become a member of a group. For example, Cloneable interface is:
Cloneable{}
Any Java Class is implementing Cloneable interface is stating that it can be cloned by other classes.
Implementation dependency:
Abstract Class helps with implementation dependency plus an abstract may contain code for reusability.
For example, AluminumCan Class can be implemented as an abstract class with setProductName() "Abstract" method, which forces the child class to
to set the product to be Coke, 7UP or Pepsi.
Mechanics (what can be done):
An Interface can only declare constants and instance methods, but cannot implement default behavior.
Interfaces provide a form of multiple inheritance.
Interfaces are limited to public methods and constants with no implementation.
A class can extend only one other class.
Abstract classes can have a partial implementation, protected parts, static methods, etc.
A Class may implement several interfaces. But in case of abstract class, a class may extend only one abstract class.
Abstract class may contain code.
Neither Abstract classes or Interface can be instantiated.
Interfaces should NOT be used as constants declaration, there should be Constant Classes for constants.
What is OOPS?
OOP is the common abbreviation for Object-Oriented Programming.
What are the principles of OOPS?
There are three main principals of oops which are called:
• Polymorphism
• Inheritance
• Encapsulation
What is Encapsulation principle?
Encapsulation is a process of binding or wrapping the data and the codes that operates on the data into a single entity. This keeps the data safe from outside interface and misuse. One way to think about encapsulation is as a protective wrapper that prevents code and data from being arbitrarily accessed by other code defined outside the wrapper.
What is the Inheritance principle?
Inheritance is the process by which one object acquires the properties of another object.
Explain the Polymorphism principle.
The meaning of Polymorphism is something like one name many forms. Polymorphism enables one entity to be used as general category for different types of actions. The specific action is determined by the exact nature of the situation. The concept of polymorphism can be explained as "one interface, multiple methods".
What are the different forms of Polymorphism?
From a practical programming viewpoint, polymorphism exists in three distinct forms in Java:
• Method overloading
• Method overriding through inheritance
• Method overriding through the Java interface
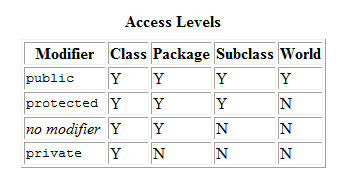
Controlling Access to Members of a Class
Access level modifiers determine whether other classes can use a particular field or invoke a particular method.
"public":
Public class is visible in other packages, field is visible everywhere (class must be public too).
"private":
Private variables or methods may be used only by an instance of the same class that
declares the variable or method, A private feature may only be accessed by the class
that owns the feature.
"protected":
protected is available to all classes in the same package and also available to all
subclasses of the class that owns the protected feature.This access is provided even
to subclasses that reside in a different package from the class that owns the protected feature.
default - no modifier:
A default is without any access modifier (public, private or protected).
It means that it is visible to all within a particular package.
go to top
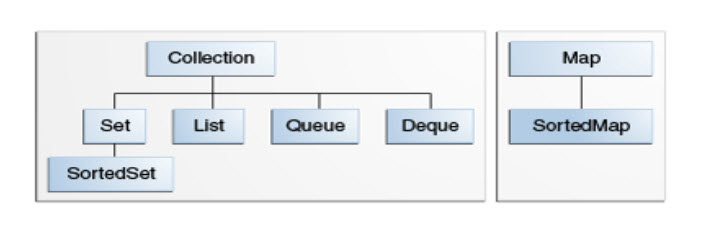
Java Collection
Java Collections framework is a new data structure to handle new programming trends
and replacement of the old data structures. It is a new release of data structure
that replace the old (HashTable, Vector, Stack, Array) with flexibilities and enforces
strong type language. Its new feature such as Generic and Concurrent Collection classes.
Although referred to as a framework, it works in a manner of a library.
List out some benefits and usage of Collections framework?
Consistency, strong type language where errors are corrected at compile time, reusability,
new looping features. It is a set of the following:
Collection Interfaces:
Set, List, Queue and SortedSet
Map, SortedMap
Implementation Classes of the Collection Interfaces:
HashSet (no dulpicate, TreeSet, LindedHasSet)
ArrayList, LinedList
HashMap, TreeMap, LinkedHashMap
Synchronization Wrappers (Synchronizing collection - Design Patterns - decorator):
The synchronization wrappers add automatic synchronization (thread-safety) to an
arbitrary collection. Each of the six core collection interfaces — Collection, Set,
List, Map, SortedSet, and SortedMap — has one static factory method.
public static <T> Collection<T> synchronizedCollection(Collection<T> c);
public static <T> Set<T> synchronizedSet(Set<T> s);
public static <T> List<T> synchronizedList(List<T> list);
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m);
public static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T> s);
public static <K,V> SortedMap<K,V> synchronizedSortedMap(SortedMap<K,V> m);
Each of these methods returns a synchronized (thread-safe) Collection backed up by the specified
collection. To guarantee serial access, all access to the backing collection must be accomplished
through the returned collection. The easy way to guarantee this is not to keep a reference to the
backing collection.
Create the synchronized collection with the following trick:
List<Type> list = Collections.synchronizedList(new ArrayList<Type>());
A collection created in this fashion is every bit as thread-safe as a normally synchronized collection, such as a Vector.
Vendors (Hibernate):
Hibernate uses Java Collection interfaces such as java.util.Set, java.util.Collection,
java.util.List, java.util.Map, java.util.SortedSet, java.util.SortedMap.
I personaly used the following:
hibernate-mapping
Set
List
Developers Implementations Questions:
What is the hash Concept?
It is an algorithm or a function that turns value into a number that is can be used to get back the value.
It is used to accelerate table lookup in database.
What is HashTable?
It the old Java data structure for key-value lookup. It is synchronized and it cannot take NULL as value.
What is Iterable?
Java Interface that extend by the Java Collection interface and provide a way to iterate (loop) within the collection elements.
public interface Collection extends Iterable
{ ...}
What is Iterator?
Iterator is an object that enable you to traverse through a collection, and remove elements from the collection
public interface Iterator<E>
{
boolean hasNext();
E Next;
void remove;
}
What is Generic in The Collection Framework?
Generics: are a part of J2SE 5.0. They allow "a type or method to operate on objects
of various types while providing compile-time type safety." Java Collection that can hold
objects of any type, to specify the specific type of object stored in it.
void printCollection(Collection<?> passedCollection)
{
for (Object element : passedCollection)
{
System.out.println(element);
}
}
What is the benefits of Generic in Collection Framework?
•
It also adds up to runtime benefit because the bytecode instructions that do type checking are not generated
•
Generics makes collection strongly typed language.
•
Generics allow us to provide the type of Object that a collection can contain, so if you try to add any element of other type it throws compile time error.
•
This avoids ClassCastException at Runtime because you will get the error at compilation.
•
Also Generics make code clean since we don’t need to use casting and instanceof operator.
•
Generics add stability to your code by making more of your bugs detectable at compile time.
•
Eliminate casting.
•
A generic type declaration is compiled once and for all, and turned into a single class file, just like an ordinary class or interface declaration.
What is difference between Enumeration and Iterator interface?
Enumeration is the old Java code and Iterator is designed for the collection where you can remove elements from the collection.
Iterator is designed to work with threads.
What si the difference between Iterator and List Iterator?
Iterator can be used by any collection, while ListIterator is used with the Lists only.
Iterator is more thread -safe.
What is the difference between HashTable, HashMap?
HashMap allows null and not synchronized
HashTable does not allow Null and synchronized.
What is the difference between fail-fast, and fail-safe?
Fail-fast Iterators throws ConcurrentModificationException when one Thread is iterating over collection
object and other thread structurally modify Collection either by adding, removing or modifying objects
on underlying collection. They are called fail-fast because they try to immediately throw Exception
when they encounter failure. On the other hand fail-safe Iterators works on copy of collection instead
of original collection.
Fail-safe:
Iterator fail-safe property work with the clone of underlying collection, hence it’s not affected
by any modification in the collection. By design, all the collection classes in java.util package
are fail-fast whereas collection classes in java.util.concurrent are fail-safe.
Fail-fast iterators throw ConcurrentModificationException whereas fail-safe iterator
never throws ConcurrentModificationException.
How HashMap works in Java?
Once you put(key, value), the key is hashed, which means it si converted to a number. That number is the ID for the value.
This the reason where hashCode() and equals() methods come in play.
Each of the general-purpose implementations provides all optional operations contained in its
interface. All permit null elements, keys, and values. None are synchronized (thread-safe). All
have fail-fast iterators, which detect illegal concurrent modification during iteration and fail
quickly and cleanly rather than risking arbitrary, nondeterministic behavior at an undetermined
time in the future. All are Serializable and all support a public clone method.
The Java super class java.lang.Object has two very important methods defined in it. They are:
public boolean equals(Object obj)
public int hashCode()
These methods prove very important when user classes are confronted with other Java
classes, when objects of such classes are added to collections:
public boolean equals(Object obj)
This method checks if some other object passed to it as an argument is equal to the object
on which this method is invoked. The default implementation of this method in Object class
simply checks if two object references x and y refer to the same object. i.e. It
checks if x == y. This particular comparison is also known as "shallow comparison". However,
the classes providing their own implementations of the equals method are supposed to perform
a "deep comparison"; by actually comparing the relevant data members. Since Object class has
no data members that define its state, it simply performs shallow comparison.
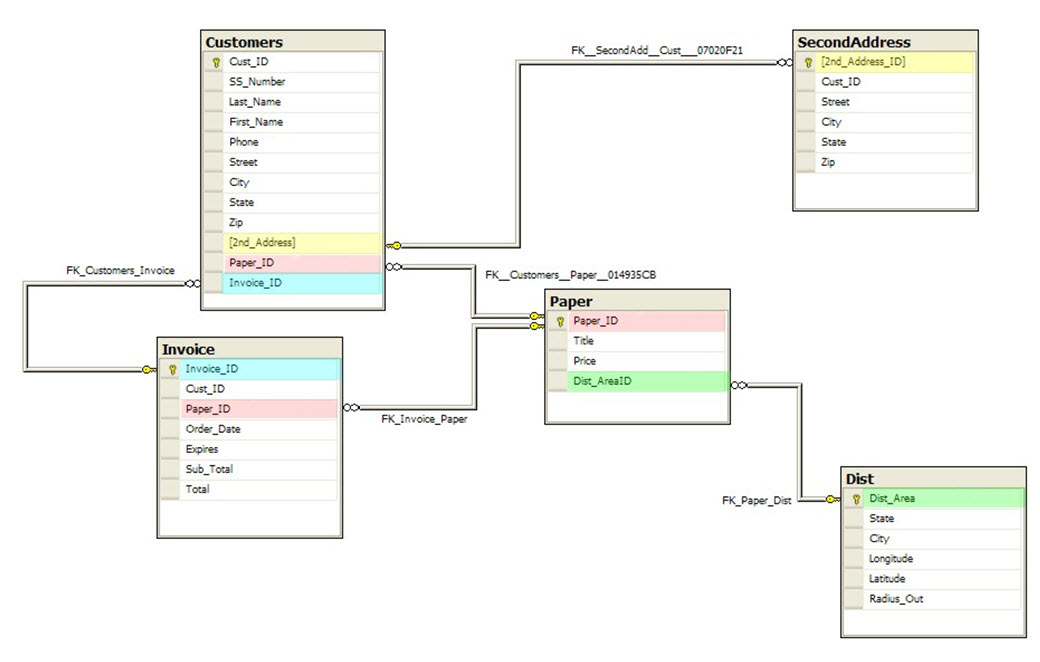
The following Java classes are part of the Credit Repair Project (http://attorneysasp.com/CreditRepairArchitect.html) where they are used to
map the Business Rules into the Business processes. The main object is see how the
Java code-syntax is done for HashTables, an some of the Collection classes.
Employee Class has the equals() and hashCode() methods.
go to top
Linked Lists and Trees
How does Java pass an object as method arguments? Pass by Value or Reference.
To understand the answer to this question better, we need know the following:
Object Passed:
The object passed to the method has a reference with the value of the actual
address of the object in memory (heap).
As long as any reference is still pointing to the object, the JVM garbage
collector would not delete or free the memory space of the object.
Address of Object Passed:
The address of the object can be passed around to other object to access the
object fields as the object allows it.
Method parameter is a local variable to the method:
passedProduct is a local parameter and local variable to the method and it will be destroyed once the method is done.
Setting passedProduct to null does not do anything to object, it is just set the local variable passedProduct to null and no value is passed back to object.
In conclusion, Java is Pass-By-Value Only
Linked Lists and Trees
Linked lists are among the simplest and most common data structures. They can
be used to implement several other common abstract data types, including the following:
Lists
Stacks
Queues
Arrays
ArrayList
Singly linked list
Doubly linked list
Multiply linked list
Circular list
Hash linking
Trees
Binary trees
Java has number of built-in (Java Collections Framework) and we will present code for some of the following:
javax.swing.tree.DefaultMutableTreeNode
Java Collection - java.util Class LinkedList
User Defined Binary Tree and the Use of Java Reflection
Code for "javax.swing.tree.DefaultMutableTreeNode"
Simple DefaultMutableTreeNode with personal information.
Structural Design Patterns - Composite Design Pattern using Java swing "jTree1":
This Java swing package is a quick demo of creating a GUI folder representation of the following serivces:
int returnValue = CompositeNodeBase.NOT_NORMAL_RUN;
switch(serviceID)
{
case CompositeNodeBase.STRING_ARRAY_TREE_SERVICE_INDEX: // Array of strings
CompositeNodeServices stringArrayTreeServicesHandle = new StringArrayTreeServices();
passedObject = (CompositeNode) stringArrayTreeServicesHandle.PollingTree();
returnValue = CompositeNodeBase.NORMAL_RUN;
break;
case CompositeNodeBase.FILE_FOLDER_TREE_SERVICE_INDEX: // file folder
CompositeNodeServices fileFolderTreeServicesHandle = new FileFolderTreeServices();
passedObject = (CompositeNode) fileFolderTreeServicesHandle.PollingTree();
returnValue = CompositeNodeBase.NORMAL_RUN;
break;
case CompositeNodeBase.JNDI_TREE_SERVICE_INDEX: // JNDI - not done
break;
case CompositeNodeBase.EMAIL_SERVER_TREE_SERVICE_INDEX: // Email - not done
break;
default:
}
java.util Class LinkedList
I do admit that I have not use Collection LinkedList, but we are
presenting a quick code examples for how to use LinkedList, java.util.Comparator
and Iterator.
User Defined Binary Tree and the Use of Java Reflection
Coding Questions:
Write down a simple code to look for an instance of Product that is in a binary
tree. The product is identified by an int id property. Write the class that can
implement this binary tree (don't worry about balancing).
public class Product
{
private final int id;
public Product (int id)
{
this.id = id;
}
}
We used Java java.lang.reflect to populate the Data Objects.
go to top
Threads
Questions and Answers:
What is the difference between Process and Thread?
A process is a self contained execution environment and it can be seen
as a program or application whereas Thread is a single task of execution
within the process. Java runtime environment runs as a single process which
contains different classes and programs as processes. Thread can be called lightweight process. Thread requires less resources to create and exists in the process, thread shares the process resources.
What are the benefits of multi-threaded programming?
In Multi-Threaded programming, multiple threads are executing concurrently
that improves the performance because CPU is not idle incase some thread is
waiting to get some resources. Multiple threads share the heap memory, so it’s
good to create multiple threads to execute some task rather than creating multiple
processes. For example, Servlets are better in performance than CGI because Servlet
support multi-threading but CGI doesn’t.
What is difference between user Thread and daemon Thread?
When we create a Thread in java program, it’s known as user thread. A daemon
thread runs in background and doesn’t prevent JVM from terminating. When there
are no user threads running, JVM shutdown the program and quits. A child thread
created from daemon thread is also a daemon thread.
How can we create a Thread in Java?
There are two ways to create Thread in Java – first by implementing
Runnable interface and then creating a Thread object from it and second
is to extend the Thread Class.
What are different states in lifecycle of Thread?
When we create a Thread in java program, its state is New. Then we
start the thread that change it’s state to Runnable. Thread Scheduler
is responsible to allocate CPU to threads in Runnable thread pool and
change their state to Running. Other Thread states are Waiting, Blocked
and Dead.
Can we call run() method of a Thread class?
Yes, we can call run() method of a Thread class but then it will behave
like a normal method. To actually execute it in a Thread, we need to start
it using Thread.start() method.
What do you understand about Thread Priority?
Every thread has a priority, usually higher priority thread gets precedence in
execution but it depends on Thread Scheduler implementation that is OS dependent. We
can specify the priority of thread but it doesn’t guarantee that higher priority thread
will get executed before lower priority thread. Thread priority is an int whose value
varies from 1 to 10 where 1 is the lowest priority thread and 10 is the highest priority thread.
What is Thread Scheduler and Time Slicing?
Thread Scheduler is the Operating System service that allocates the CPU time to
the available runnable threads. Once we create and start a thread, it’s execution
depends on the implementation of Thread Scheduler. Time Slicing is the process to
divide the available CPU time to the available runnable threads. Allocation of CPU time
to threads can be based on thread priority or the thread waiting for longer time will get
more priority in getting CPU time. Thread scheduling can’t be controlled by java, so it’s
always better to control it from application itself.
What is context-switching in multi-threading?
Context Switching is the process of storing and restoring of CPU state so that Thread
execution can be resumed from the same point at a later point of time. Context Switching
is the essential feature for multitasking operating system and support for multi-threaded environment.
How can we make sure main() is the last thread to finish in Java Program?
We can use Thread join() method to make sure all the threads created by the program is dead before finishing the main function.
How does thread communicate with each other?
When threads share resources, communication between Threads is important to coordinate their
efforts. Object class wait(), notify() and notifyAll() methods allows threads to communicate
about the lock status of a resource.
what is Volatile ?
This guarantees that in the case of ready the reader will get the most recent value in that volatile field.
Other threads see the changes to the field.
public class ThreadTest
{
volatile boolean running = true;
...
}
Atomic:
Each action takes place in one step cannot be interrupted.
All primitive types (except long and Double) are not atomic.
Loop++ is not atomic.
Using volatile eliminate any possible memory error or overwrites.
Long and double are 64 bit which they take 2(32 bit operations) that may cause one operation write 32 bit and second is done by another thread.
Deadlock?
Is where two or more thread are locked forever.
Liveleness:
The current process is running without any error or locks.
Thread Pool:
A collection of running threads or a collection of Runnable Workers.
The is the difference between a Thread and a Process:
A process may have one or more threads running inside it. They do not share data.
what happen when you call the method "start();"?
The thread will be ready for JVM to run. The scheduler will check to see if it running, then it schedule it to run.
How methods you need to overwrite when implementing the Runnable Interface?
the run() method only. It is the standard entry point of execution for Runnable object.
which way would prefer to create a thread?
using the Runnable interface is better that extending the Thread class due Java single inheritance.
what is the difference states of a thread:
Running
waiting, sleep, suspended, blocked
ready state
dead- finished.
what is yield() method do?
It move the running thread to the ready state and allows the read thread to execute.
It gives the ability to get other thread to execute.
which thread methods does the Object class have?
wait(), notify() and notifyall().
what is the difference between preemptive and time slice?
Time slice is give X time to run
Preemptive is higher priority threads run first.
what is the difference between start()and run() methods?
Start() starts the execution of the thread by calling the run() method. start() ends while the run() keeps executing.
How do you prevent deadlock?
Using the following:
• volatile
• atomic
• synchronizing the following:
o method
o code segment
o data
o variables
Coding Questions:
Given a class that reads data from a stream with given method: byte[] read10bytes().
Using multithread programming, write a code to read 100 bytes of 10 different streams
(one thread per stream). After code execution, we must have a byte array with all data
read from these 10 streams. Use the best way to do that. The result array must have the 100
bytes of first stream followed by 100 of second and so on.
public class ReaderClass
{
private String streamName;
public ReaderClass(String name)
{
this.streamName = name;
}
public byte[] read10bytes()
{
//reads 10 bytes and returns only when all 10 bytes have been filled.
}
}
go to top
SQL and Tables Design
This section has two parts as follows:
• The Immerging New Importance of SQL Queries and Tables Design
• Interview SQL Questions & Answers plus Java code
The Immerging New Importance of SQL and Tables Design:
Now, the emerging of new Intelligent systems, Customer Relationship Management (CRM) system, search engines and
personalized web pages demand that the Database, Queries and Database
Table Design must have some type of Intelligence and not just a dummy data permanent storage.
In short, databases, data, tables, queries and processes are taking a new way
of thinking and approach.
The only way to explain my point is to show an example. To make my point easier,
my example would be a simple question about "Banana" search.
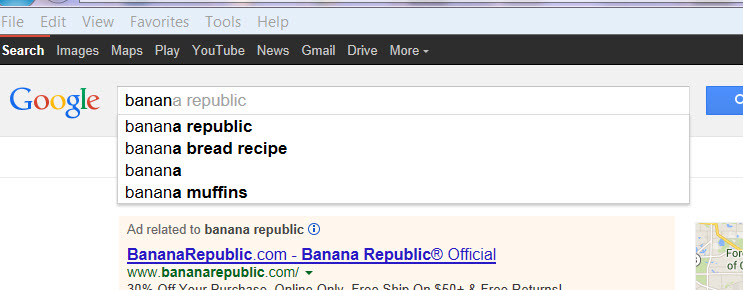
Let us start by typing the word "Banana" in the Google search page and see the result.
The output is shown in the Google image #1.
Google image #1
The result of typing "Banana" is an arbitrary suggestions to help with the search.
Personalizing the "Banana" Search
To make such a search more personalized, we may need to design the tables-data and
the site software to perform a number of cooperative tasks. For our illustration, let
us assume that the personal data in these tables based on outside vendors that do
their market research. Please note that the data presented is for our illustration
purpose and "no pun intended". Table design-contents are as follows:
Banana Questions - Search Index:
This table has market research data and index of what messages and images that search code should present to the site visitor.
Banana Questions - Index Table:
This table has the messages based on market research had suggested to be displayed to the site visitor
Banana Images - Index Table:
This table has the image based on market research had suggested to be displayed to the site visitor.
Banana Questions - Search Index Table
Gender
Professional Index
Income
DOB
City-State
Season Index
Purchase Index
Image Index
Questions Index
Female
1021(Teacher)
$65,000
10/12/1970
Chicago, IL
F
8
1,2,3
1,2,3,5,6,7
Male
9021(IT Architect)
$125,000
11/12/1982
Schaumburg, IL
S
10
2,4,5
1,4,6,7,8
Female
3021(Student-Dependent)
$95,000
11/12/1996
Chicago, IL
W
9
2,3,5
3,4,5
Female
6021(Homemaker )
$75,000
06/12/1969
Chicago, IL
F
9
4,5
1,2,3,4
Male
5021(Admin Assistance)
$55,000
10/12/1975
Chicago, IL
F
4
1,2,5
1,4,5
Banana Questions - Index Table
Index
Questions
1
buying Chiquita banana
2
banana bread recipe
3
banana muffin
4
banana boat trip and rental
5
Banana Republic is a clothing and accessories
6
Banana Republic locations in Santa Cruz
7
History - establishing banana plantations in Jamaica
8
Jamaica Cruise Packages
Banana Images - Index Table
Index
Image name & link
1
B_CruiseThumpnail.jpg
2
BananaMuffinThumpNail.jpg
3
BananaBoatThumpNail.jpg
4
BananaChiquitaThumpNail.jpg
5
bananaRepThumpNail.jpg
What I am presenting is not new, Google and Amazon wrote the book on that.
My main point is:
"How can we use data and databases to make our intelligent system think in abstract."
Abstract Thinking:
Our intelligent system would be doing the following:
• Does the footwork
o Use the database and other data to create processes for our intelligent system to Think in Abstract
o Provide all detail and cost needed for our client options
• Thinking in Abstract
o Recognizes a pattern
o Figure out what could be missing
o Gives options
o Suggests answers and directions
o Solves problems
o Points out bargains or savings
Let us assume that on a Friday at 4:00 PM Chicago time, our "Search Index
Table 3021(Student-Dependent)" is typing the word "Banana" on our Intelligent-Personalized
Search Engine.
What would our Intelligent-Personalized Search Engine present to her?
(I hope I will be forgiven in my choice of colors and messages in the search result)
Sam Search Engine
Food - Banana muffin
Muffin on sale at X store
Weekend Fun - Banana boat trip and rental
Friends and Family Day at Chicago Marina - special rates for families
Shopping - Banana Republic - a clothing and accessories - Sale ends Today
Movie anyone?!!
Check what is playing at theater near you.
Helping Hints:
Good Things to Do:
Under 18 years, may need to call Your Parent and let them know your plan
Routes, mileage and cost to your destinations:
XX Mall is 12 miles check the routes, directions and maps
Do you have a car?
Call parent or friends.
Also Chicago METRA has buses that you can use.
Let us check how our Intelligent-Personalized Search Engine Thinks-in-Abstract.
Recognizes a pattern
1. She is 17 years old - DOB: 11/12/1996
2. Her birthday is coming and we need to send her birthday email or card
3. Does not own a car
4. She lives with her parents
5. She is a dependent of a good income family
6. She has a valid driver license and probably can drive
7. She is a season shopper at winter time
8. Her shopping habit is high
9. Current time and day: Friday, 3:30 PM
10. She is probably not in school and looking to eat out, wants to go shopping or see a movie
What is missing:
• Parent approval
• May need transportation for shopping
Gives options:
• Food banana muffin
• banana boat trip this weekend
• Banana Republic shopping for clothing and accessories
• See a movie at theater near by
Points out bargains or savings
• Muffin on sale at X store
• Banana Republic has a special that will end today
• Latest movies at what theater
Suggests answers and directions
• store near you
• closing time for the stores
• Movies starting times
• Mileage and routes
• Online ticket booking
Solves problems
• The transportation issue and what can be an alternative
• Money issue and what would this teenager would have done in the past (credit cards history) or what most teens would do.
• Suggest to the this teenager to call and inform her parents with her plans and where she should be at what time.
In conclusion, our Intelligent system with the help of the database and data
is capable of playing parent or guardian for this teenager by helping her
with her Friday night activities with good suggestions and guidelines. Not
to mention that we also service our clients (movie theater, shopping malls
and stores, credit card companies and the list is not short).
Interview SQL Questions & Answers plus Java code
The following are Interview Questions and their answers.
What is DBMS?
A Database Management System (DBMS) is a program that controls creation, maintenance and use of a database. DBMS can be termed as File Manager that manages data in a database rather than saving it in file systems.
What is RDBMS?
RDBMS stands for Relational Database Management System. RDBMS store the data into the collection of tables, which is related by common fields between the columns of the table. It also provides relational operators to manipulate the data stored into the tables.
What is SQL?
SQL stands for Structured Query Language , and it is used to communicate with the Database. This is a standard language used to perform tasks such as retrieval, updation, insertion and deletion of data from a database.
What is a Database?
Database is nothing but an organized form of data for easy access, storing, retrieval and managing of data. This is also known as structured form of data which can be accessed in many ways.
What are tables and Fields?
A table is a set of data that are organized in a model with Columns and Rows. Columns can be categorized as vertical, and Rows are horizontal. A table has specified number of column called fields but can have any number of rows which is called record.
What is a query?
A DB query is a code written in order to get the information back from the database. Query can be designed in such a way that it matched with our expectation of the result set. Simply, a question to the Database.
What is subquery?
A subquery is a query within another query. The outer query is called as main query, and inner query is called subquery. SubQuery is always executed first, and the result of subquery is passed on to the main query.
What are the types of subquery?
There are two types of subquery – Correlated and Non-Correlated.
A correlated subquery cannot be considered as independent query, but it can refer the column in a table listed in the FROM the list of the main query.
A Non-Correlated sub query can be considered as independent query and the output of subquery are substituted in the main query.
What is a "primary" Key?
It is a constraint that show uniqueness in the column
Cannot be null
What is a unique key?
A Unique key constraint uniquely identified each record in the database. This provides uniqueness for the column or set of columns.
A Primary key constraint has automatic unique constraint defined on it. But not, in the case of Unique Key.
There can be many unique constraint defined per table, but only one Primary key constraint defined per table.
what us secondary key or foreign key?
It the primary key in another table.
what is the difference between primary key and unique key:
Primary is unique and not null
Unique can be null and may not be a primary.
what is a "constraint"?
a constrain helps you to apply a simple check for referencing tables.
Primary/Unique Key: enforces uniqueness in a particular column.
Not null - cannot have a null value
foreign key - the value exists in another table
default value - the default vale if no value is given
check - performing a check to the value that would store if following a constraint
What are methods for retrieving data?
Select - select * from myTable
Cursor - type myCursor REF CURSOR ... loop using the myCursor and close the mtTable
What Cursor Type do use to retrieve multiple record sets?
Implicit - by using "select" Statement
Explicit - by creating and open cursor.
what is the difference between "where" and having clause?
"where" is restricted by "Select" statement, where is retrieved after the "where"
"having" is used after the data is the data is retrieved.
what is the basic form to read data out of a table?
'Select * from myTable;'
the above is basic but we cannot call basic form if we are using the "where" clause.
what is a "join"?
"join" is used to connect two or more table logically with or without a common field.
This condition is called Referential integrity (RI).
It is the concept of relationships between tables, based on the definition of a primary key and a foreign key.
what types of index a data structure can you have?
Primary index or key
Bitmap - using bits to make a value
hash - integer key for value
what is Stored procedures or function?
It is sql block of code to be executed and it is stored and called.
It has signature and parameters, declaration section and body to execute - similar to Pascal procedures.
It parameters can be (by value, or by reference)
what is a "trigger"?
A trigger is a stored procedures that executed enforce a check on the following:
insert
update
delete
What is the use of preparedstatement? -
Preparedstatements are precompiled statements. It is mainly used to speed up the process of inserting/updating/deleting especially when there is a bulk processing.
What is callable statement?
Tell me the way to get the callable statement?
Callablestatements are used to invoke the stored procedures.
You can obtain the callablestatement from Connection using the following methods:
prepareCall(String sql)
prepareCall(String sql, int resultSetType, int resultSetConcurrency)
What is a View?
A view is a virtual table which consists of a subset of data contained in a table. Views are not virtually present, and it takes less space to store. View can have data of one or more tables combined, and it is depending on the relationship.
What is normalization?
Normalization is the process of minimizing redundancy and dependency by organizing fields and table of a database. The main aim of Normalization is to add, delete or modify field that can be made in a single table.
What is Denormalization.
DeNormalization is a technique used to access the data from higher to lower normal forms of database. It is also process of introducing redundancy into a table by incorporating data from the related tables.
What is an Index?
An index is performance tuning method of allowing faster retrieval of records from the table. An index creates an entry for each value and it will be faster to retrieve data.
What are all the different types of indexes?
There are three types of indexes -.
Unique Index.
This indexing does not allow the field to have duplicate values if the column is unique indexed. Unique index can be applied automatically when primary key is defined.
Clustered Index.
This type of index reorders the physical order of the table and search based on the key values. Each table can have only one clustered index.
NonClustered Index.
NonClustered Index does not alter the physical order of the table and maintains logical order of data. Each table can have 999 nonclustered indexes.
What is the difference between DELETE and TRUNCATE commands?
DELETE command is used to remove rows from the table, and WHERE clause can be used for conditional set of parameters. Commit and Rollback can be performed after delete statement.
TRUNCATE removes all rows from the table. Truncate operation cannot be rolled back.
What is a stored procedure?
Stored Procedure is a function consists of many SQL statement to access the database
system. Several SQL statements are consolidated into a stored procedure and execute
them whenever and wherever required.
A stored procedure is a group of SQL statements that form a logical unit and perform a particular
task, and they are used to encapsulate a set of operations or queries to execute on a database server.
Quick Example:
CREATE PROCEDURE sam_myStoredProcedure
@myInput int
AS
Select column1, column2 From Table1
Where column1 = @myInput
Go
Three Basic
SQL Table Design Rules.
• RULE 1: In a Table, do not repeat data.
• RULE 2: Repeated data goes in another Linked table.
• RULE 3: Row Data must only rely on the Table's Primary Key.
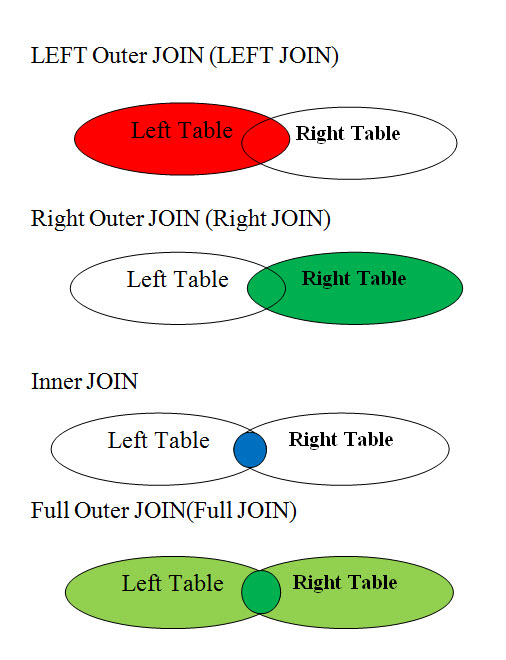
What is JOIN in SQL?
In a large application we have multiple tables in a database and they are interrelated with each other. When we are required to retrieve the data from those tables based on the relationship between them we use JOINs. So we can say Join is a method to retrieve rows from multiple tables satisfying some criteria (relationship).
How many joins are there?
There are basically two kinds of join and others are either their sub part or special cases.
Inner Join
Outer Join
Inner Join
Inner join return rows when there is at least one match of rows between the tables.
Select * FROM table1 Inner JOIN table2
ON table1.column_name=table2.column_name;
Left Outer Join
Left join return rows which are common between the tables and all rows of
Left hand side table. Simply, it returns all the rows from Left hand side
table even though there are no matches in the Right hand side table.
Select * FROM table1 LEFT OUTER JOIN table2
ON table1.column_name=table2.column_name;
Right Outer Join
Right join return rows which are common between the tables and all rows
of Right hand side table. Simply, it returns all the rows from the right
hand side table even though there are no matches in the left hand side table.
Select * FROM table1 RIGHT OUTER JOIN table2
ON table1.column_name=table2.column_name;
Full Outer Join
Full join return rows when there are matching rows in any one of the tables. This means,
it returns all the rows from the left hand side table and all the rows from the right hand side table.
SELECT * FROM employee FULL OUTER JOIN department
ON employee.DepartmentID = department.DepartmentID;
What is Query plans?
A query plan (or query execution plan) is an ordered set of steps used to access
data in a SQL relational database management system. This is a specific case of the
relational model concept of access plans.
What is Showplan?
Showplan is a feature in SQL Server to display and read query plans. It is one of the most important
diagnostic tools that is use in the query processing team to locate and identify
problems, and therefore deserves some extra exposure. Being able to collect,
read, and understand Showplan data is a critical skill to have.
What is Data striping?
Since SQL is declarative, there are typically a large number of alternative ways to execute a given
query, with widely varying performance. When a query is submitted to the database, the query optimizer
evaluates some of the different, correct possible plans for executing the query and returns what
it considers the best alternative. Because query optimizers are imperfect, database users and
administrators sometimes need to manually examine and tune the plans produced by the optimizer to
get better performance.
In computer data storage, data striping is the technique of segmenting logically sequential
data, such as a file, so that consecutive segments are stored on different physical storage
devices. Striping is useful when a processing device requests data more quickly than a single
storage device can provide it. By spreading segments across multiple devices which can be
accessed concurrently, total data throughput is increased. It is also a useful method for
balancing I/O load across an array of disks. Striping is used across disk drives in redundant
array of independent disks (RAID) storage, network interface controllers, different computers
in clustered file systems and grid-oriented storage, and RAM in some systems
What is Replication?
Replication is a set of technologies for copying and distributing data and database objects
from one database to another and then synchronizing between databases to maintain
consistency. Using replication, you can distribute data to different locations and to remote
or mobile users over local and wide area networks, dial-up connections, wireless connections,
and the Internet.
What is partitioning?
A partition is a division of a logical database or its constituting elements into distinct independent
parts. Database partitioning is normally done for manageability, performance or availability reasons.
Benefits of multiple partitions:
A popular and favourable application of partitioning is in a distributed database management
system. Each partition may be spread over multiple nodes, and users at the node can perform
local transactions on the partition. This increases performance for sites that have regular
transactions involving certain views of data, whilst maintaining availability and security.
How do you troubleshoot a slow running query:
Inadequate memory in the server computer, or not enough memory available for SQL Server.
Lack of useful statistics
Lack of useful indexes.
Lack of useful indexed views.
Lack of useful data striping.
Lack of useful partitioning.
Indexes: (Types & Usage)
Most MySQL indexes:
PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT
are stored in B-trees. Exceptions are that indexes on spatial data types
use R-trees, and that MEMORY tables also support hash indexes.
FULLTEXT:
In text retrieval, full-text search refers to techniques for searching a single
computer-stored document or a collection in a full text database. Full-text
search is distinguished from searches based on metadata or on parts of the original
texts represented in databases (such as titles, abstracts, selected sections, or
bibliographical references).
In a full-text search, the search engine examines all of the words in every
stored document as it tries to match search criteria.
Many websites and application programs (such as word processing software) provide
full-text-search capabilities. Some web search engines, such as AltaVista, employ
full-text-search techniques, while others index only a portion of the web pages
examined by their indexing systems.
How MySQL Uses Indexes
Indexes are used to find rows with specific column values quickly. Without
an index, MySQL must begin with the first row and then read through the entire
table to find the relevant rows. The larger the table, the more this costs. If the
table has an index for the columns in question, MySQL can quickly determine the
position to seek to in the middle of the data file without having to look at all
the data. If a table has 1,000 rows, this is at least 100 times faster than reading
sequentially. If you need to access most of the rows, it is faster to read
sequentially, because this minimizes disk seeks.
Find max of count - "max(count(*));":
SELECT * FROM
(
SELECT book_publisher, COUNT(DISTINCT book_author_id) author_count
FROM table1
GROUP BY book_publisher
ORDER BY author_count DESC
)
WHERE rownum = 1
How to fetch latest date in sql:
SELECT * FROM table
WHERE Dates IN (SELECT max(Dates) FROM table);
Select * FROM test_table
WHERE user_id = value
AND date_added = (select max(date_added) from test_table
where user_id = value
)
When would you do use Stored Procedure Caching?
Stored Procedures are a way to partially precompile an execution plan.
Executing a stored procedure is more efficient than executing an SQL statement because SQL Server
did not have to compile an execution plan completely, it only had to finish optimizing the stored plan
for the procedure.
Also, the fully compiled execution plan for the stored procedure is retained in the
SQL Server procedure cache, meaning that subsequent executions of the stored procedure could use the
precompiled execution plan.
Stored Procedure Caching = prepared statement
No recompilation
Delete & Truncate – difference
1.
Statement type: Delete is DML, Truncate is DDL
2.
Commit: Delete has no autocommit, a truncate is autocommited
3.
Space reclamation: Delete does not recover space, Truncate recovers space (unless you use the REUSE STORAGE clause)
4.
Row scope: Delete can remove only some rows. Truncate removes all rows except where used in a partitioning context.
5.
Object types: Delete can be applied to tables and tables inside a cluser. Truncate applies only to tables or the entire cluster
6.
Data Object ID's: Delete does not affect the data object id, but truncate assigns a new
data object id unless there has never been an insert against the table (even a single insert that is rolled back will cause a new data object id to be assigned).
7.
Rollback: In some implementations (eg. Oracle) truncate cannot be rolled back.
8.
Flashback: Flashback works across deletes, but a truncate prevents flashback operations to before the operation.
9.
Grants: Delete can be granted on a table to another user or role, but truncate cannot be without using a DROP ANY TABLE grant.
10.
Redo/Undo: Delete generates a small amount of redo and a large amount of undo. Truncate generates a negligible amount of each.
11.
Indexes: A truncate operation renders unusable indexes usable again. Delete does not.
12.
Foreign Keys: A truncate cannot be applied when an enabled foreign key references the table. Treatment with delete depends on the configuration of the foreign keys
13.
Locking: Truncate requires an exclusive table lock, delete requires a shared table lock.
14.
Triggers: DML triggers do not fire on a truncate.
Schema:
Databases contain collections of independent schemas. A schema is a logical grouping of
tables, indexes, triggers, routines, and other data objects under one qualifying name. Internationalization
characteristics and user-level security can also be defined for schema objects.
In computer programming, a schema (pronounced SKEE-mah) is the organization or structure
for a database. The activity of data modeling leads to a schema. (The plural form is
schemata. The term is from a Greek word for "form" or "figure." Another word from the same
source is "schematic.") The term is used in discussing both relational databases and
object-oriented databases. The term sometimes seems to refer to a visualization
of a structure and sometimes to a formal text-oriented description.
data object:
The database itself is a data object that encompasses all other data objects. A database
contains Schema objects, which in turn contain Table objects. Tables whose values are
derived from other tables are called Derived Tables or Views. Finally, a Column is located
within a Table. Columns are the smallest data object within PointBase RDBMS.
Two common types of database schemata are the star schema and the snowflake schema
schema creation:
When a database is created using PointBase Commander, PointBase Console, or the JDBC API,
the PointBase RDBMS creates two schemas:
1. An internal schema called POINTBASE, in which the system keeps all of the system catalogs and tables
2. A default schema called PBPUBLIC
You cannot create any user-defined data objects within the POINTBASE schema. For a list
of predefined system tables and their attributes within the POINTBASE schema, please refer
to "Appendix A: System Tables" in the PointBase System Guide.
The following are sample code for Database Adapter package using SQL call.
go to top
Architect - Tiers Way of Thinking
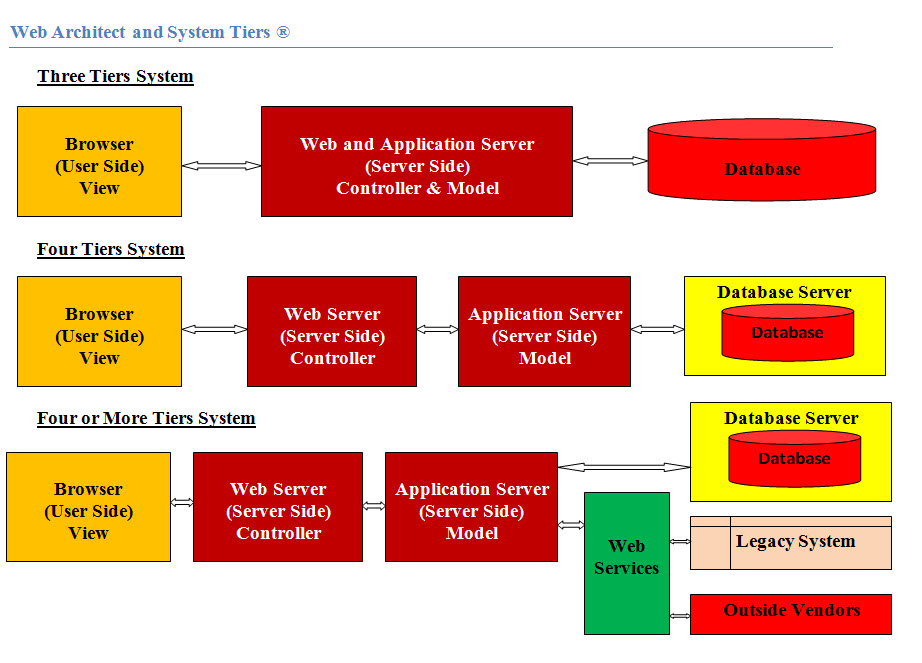
What is the advantage of using n-tier architecture system?
Client Tier:
Client tier represents Web browser, a Java or other application, Applet, WAP phone etc. The
client tier makes requests to the Web server who will be serving the request by either returning
static content if it is present in the Web server or forwards the request to either Servlet
or JSP in the application server for either static or dynamic content.
Web Server (Presentation) tier:
Presentation tier encapsulates the presentation logic required to serve clients. A Servlet or
JSP in the presentation tier intercepts client requests, manages logons, sessions, accesses
the business services, and finally constructs a response, which gets delivered to client.
Business (Application) Tier:
Business tier provides the business services. This tier contains the business logic and the
business data. All the business logic is centralized into this tier where the business
logic is scattered between the front end and the backend. The benefit of having a centralized
business tier is that same business logic can support different types of clients like
browser, WAP (Wireless Application Protocol) client, other stand-alone applications written
in Java, C++, C# etc.
Resource Tier or Data Tier:
Resource tier is the external resource such as a database, ERP system, Mainframe system etc.
It is responsible for storing the data. This tier is also known as Data Tier or EIS (Enterprise Information System) Tier.
Data tier can be part of the business or application tier, but we do recommend that it would be
an independent tier for reusability and scalability.
Integration:
Integration tier is responsible for communicating with external resources such as databases, legacy systems, ERP systems, messaging systems like MQSeries etc. The components in this tier use JDBC, JMS, J2EE Connector Architecture (JCA) and some proprietary middleware to access the resource tier.
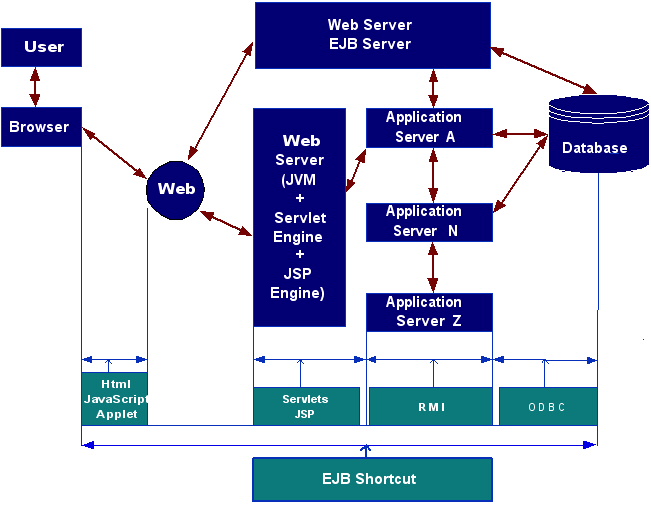
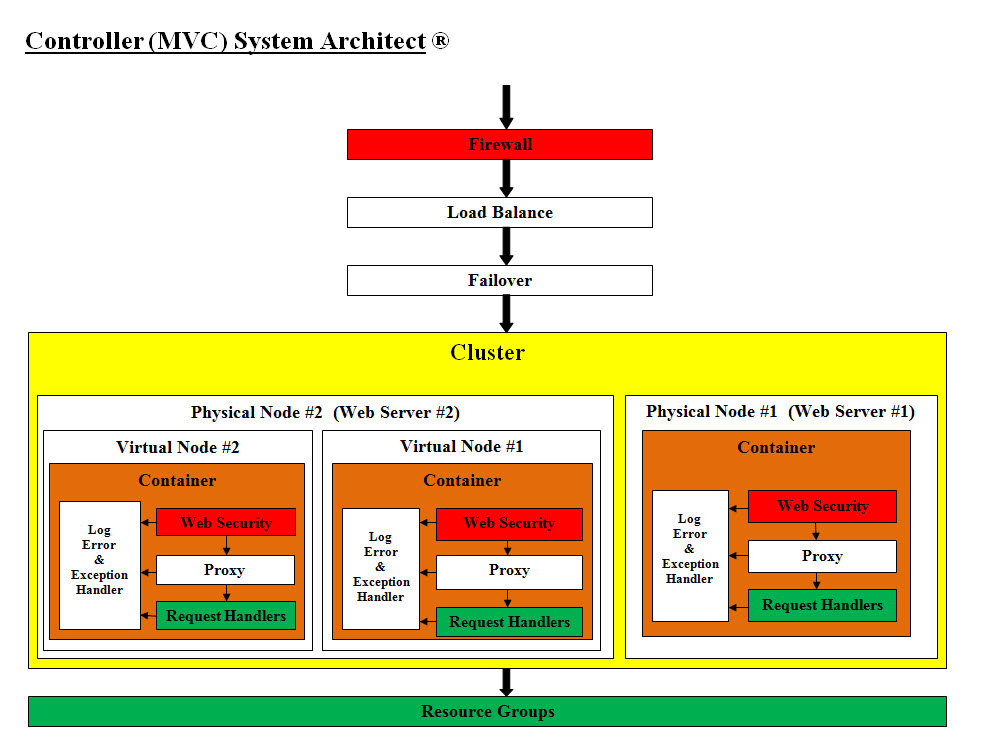
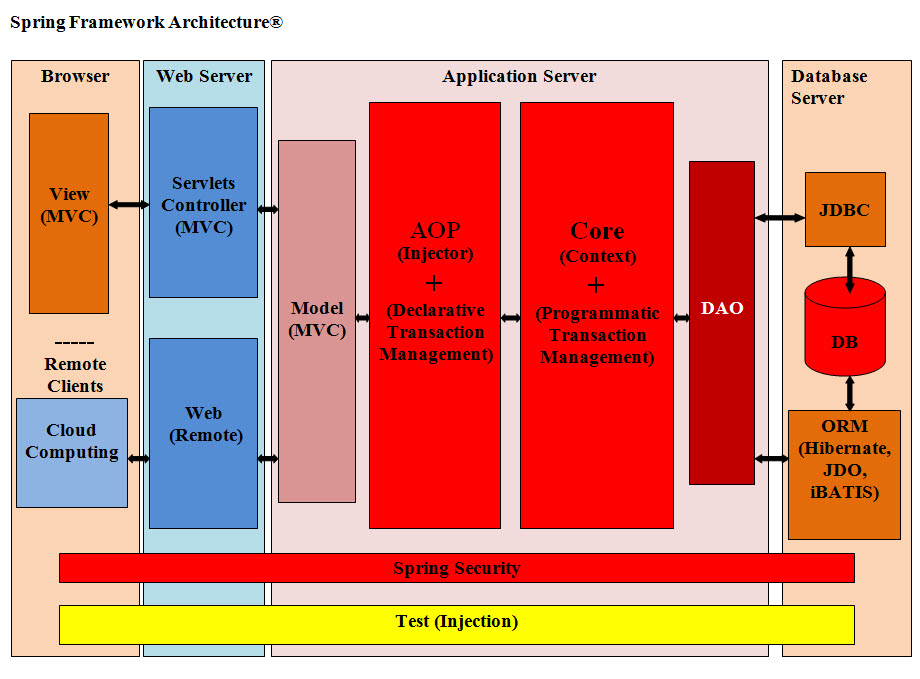
MVC: Model – (data and Business classes), View (User Interface), Controller (enterprise web application)
A web application is a number of programs that handle all the transactions from the users
front-end to the database the back-end. A web application is composed of several types of
programs and each has its unique functionality and link to the other programs. The following
image presents how Java solution handles such a web application.
The Controller is basically the front gateway of any web system to World Wide Web. It is
also the safeguard and the front security for Model Components. It is a combination of
venders software (such as Apache Tomcat, or WebSphere) and customized software built by
the domain website owners. The controller can be as simple as HTML pages on the domain
website or as complicated as B2B web system.
Clustering allows us to run one application on several parallel servers (a.k.a cluster nodes). The
load is distributed across different servers, and even if any of the servers fails, the application
is still accessible via other cluster nodes. Clustering is crucial for scalable enterprise
applications, as you can improve performance by simply adding more nodes to the cluster.
JBoss and Hibernate:
Hibernate is a popular persistence engine that provides a simple, yet powerful, alternative
to using standard entity beans. Hibernate runs in almost any application server, or even
outside of an application server completely. However, when running inside of JBoss, you
can choose to deploy your application as a Hibernate archive, called a HAR file, and make
Hibernate's simple usage even simpler. JBoss can manage your Hibernate session and other
configuration details, allowing you to use Hibernate objects with minimal setup.
What is Transient variable?
Transient variable can't be serialize. For example if a variable is declared as transient
in a Serializable class and the class is written to an ObjectStream, the value of the
variable can't be written to the stream instead when the class is retrieved from the ObjectStream
the value of the variable becomes null.
Transient
Transient instance fields are neither saved nor restored by the standard serialisation
mechanism. You have to handle restoring them yourself.
Design patterns
Design pattern(s) is a combination of UML approach and algorithm systematic steps to
provide a universal problem solving tool or mythology, where technical individuals such
as architects, designers, developers, managers, and analysts can use Design Patterns tool
or mythology to help with development and communication in building software.
Behavior Patterns:
Observer
The Observer pattern defines the way a number of classes can be notified of a change.
Mediator
The Mediator defines how communication between classes can be simplified by using another class to keep all classes from having to know about each other.
Chain of Responsibility
The Chain of Responsibility allows an even further decoupling between classes, by passing a request between classes until it is recognized.
Template
The Template pattern provides an abstract definition of an algorithm.
Interpreter
The Interpreter provides a definition of how to include language elements in a program.
Strategy
The Strategy pattern encapsulates an algorithm inside a class.
Visitor
The Visitor pattern adds function to a class.
State
The State pattern provides a memory for a class’s instance variables.
Command
The Command pattern provides a simple way to separate execution of a command from the interface environment that produced it.
Iterator
The Iterator pattern formalizes the way we move through a list of data within a class.
Creational Patterns:
Factory
The Factory Method provides a simple decision making class which returns one of several possible subclasses of an abstract base class depending on data it is provided.
Abstract Factory Method
The Abstract Factory Method provides an interface to create and return one of several families of related objects.
Builder
The Builder Pattern separates the construction of a complex object from its representation, so that several different representations can be created depending on the needs of the program.
Prototype
The Prototype Pattern starts with an initialized and instantiated class and copies or clones it to make new instances rather than creating new instances.
Singleton
The Singleton Pattern provides a class of which there can be no more than instance, and provides a single global point of access to that instance.
Structural Patterns:
Adapter
The Adapter Pattern is used to change the interface of one class to that of another one.
Bridge
The Bridge Pattern is intended to keep the interface to your client program constant while allowing you to change the actual kind of class you display or use. You can then change the interface and the underlying class separately.
Composite
The Composite Pattern is a collection of objects, any one of which may be either itself a Composite, or just a primitive object.
Decorator
The Decorator Pattern is a class that surrounds a given class, adds new capabilities to it, and passes all the unchanged methods to the underlying class.
Façade
The Façade Pattern groups a complex object hierarchy and provides a new, simpler interface to access those data.
Flyweight
The Flyweight pattern provides a way to limit the proliferation of small, similar class instances by moving some of the class data outside the class and passing it in during various execution methods.
Proxy
The Proxy pattern provides a simple place-holder class for a more complex class which is expensive to instantiate.
Interview Questions (Servlet Performance Question)
As an engineer you have volunteered to re-design the website platform which is
not scaling to meet customer demand. Your research shows that the current
platform of 1 server and 1 database scales linearly where 1 request equals
one 1% CPU/IO utilization on both the server and database. You are not able
to improve on the linear scalability and the hardware is already top of the
line (you cannot get anything faster).
1) Describe how you would re-design the platform to improve scalability.
Answer:
Vertical scalability:
• Increase main memory
• Cashing frequently-use tables and files
• Use Cache-oblivious algorithm
• Using sessions to keep data on the user-side
• Using JavaScript to do more processing on the client-side rather than server-side
• Servlets - Speed and performance
o use : HttpSession, Hidden fields, Cookies, URL rewriting, the persistency mechanism.
o Tune the thread pool size
o Minimize Java synchronization in servlets.
o Don’t use the single thread model for servlets.
o Use the servlet’s init() method to perform expensive one-time initialization.
o Avoid using System.out.println() calls.
• Fine-tune database table
o Use PreparedStatment
o Run statistic and move the frequently-used tables to memory or Cashe.
o Mapped Index for faster search
Using the Log:
Using the log on JSP and servlets would help track errors:
• Transport exceptions
• Protocol exceptions
• HTTP transport safety
• Automatic exception recovery
• Custom exception handler
Using Exceptions:
There are two main type of exceptions that the user of HttpClient may encounter when executing HTTP methods:
1. transport exceptions
2. protocol exceptions
HttpClient:
Generic transport exceptions in HttpClient are represented by the standard Java java.io.IOException
class or its sub classes such as java.net.SocketException and java.net.InterruptedIOException.
In addition to standard input/output exception classes HttpClient defines several custom transport
exceptions that convey HttpClient specific information.
High load web servlets Tips:
1.
Hand off requests for static resources directly to the web server by specifying the URL, not by redirecting from the servlet.
2.
Use separate webservers to deliver static and dynamic content.
3.
Eliminate all the static variables since servlets are threaded and may cause errors.
4.
Cache as much as possible. Make sure you know exactly how much RAM you can spare for caches, and have the right tools for measuring memory.
5.
Load balance the Java application using multiple JVMs.
6.
Use "ulimit"* to monitor the number of file descriptors available to the processes. Make sure this is high enough.
7.
Logging is more important than the performance saved by not logging.
8.
Monitor resources and prepare for spikes.
* The "ulimit" command provides control over the resources available to the shell and/or to processes
started by it, on systems that allow such control. The maximum number of open file descriptors
displayed with following command (login as the root user).
go to top
Service Oriented Architect (SOA)
It is very hard for a web architect to understand SOA. Not to mention you may
end up reading over 50 pages of SOA descriptions and how great SOA is and still not
have a clue what SOA is. What is more confusing is that no one can put a picture
to SOA and you may see a 1,000 image of SOA with nothing in common.
The reason is that a web architect is looking for structure with database,
GUI front, Servlets, servers, firewall and so on and a web architect wants to see
interfaces and data flow.
The reality is that SOA has a basic structure, interfaces, communication and
data flow. To make it easier on how to understand SOA, we need to give an
analogy. Let assume that a person named Sam moved into a new neighborhood and
needs to know where the closest pizza place, Laundromat and gas station. The
best way for him to find out about these places is to do the following:
• Look them up in the local phone directory
• Call them up or read their ads in the directory
• Know what to order and how to order
• Start communicating with them directly.
• Calling, ordering and delivery of service are messages between Sam and the stores
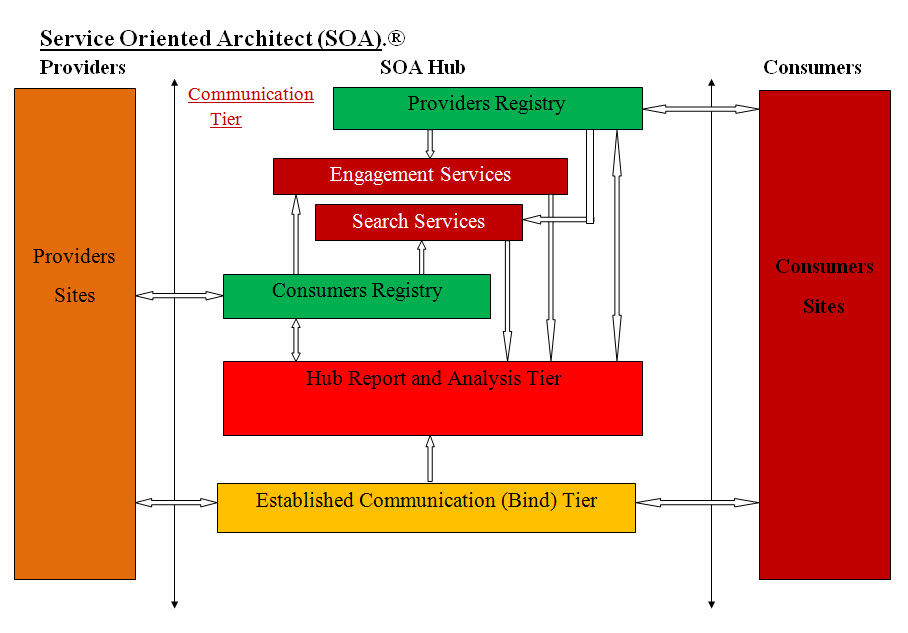
My understanding of SOA is that it is composed of the following:
• Service providers (pizza place, Laundromat and gas station)
• Service consumers (Sam)
• Registry (phone directory)
• Binding (Know what to order and how to order)
• Communication (can be SOAP, web services, REST, ...)
• Data Flow of messages between Service providers and Service consumers
Advantage of SOA:
With SOA structure, anything can be sold and or exchanged, once the discovery
and communication are established. Both server providers and service consumers
can start doing business. The following are the advantage of SOA:
• Standardized service communication
• Service loose coupling
• Service abstraction
• Service reusability
• Service independence
• Service statelessness
• Service discoverability
• Service normalization
• Service optimization
• Service relevance
• Service encapsulation
• Service location transparency
SOA Communication:
SOA can operate independently of specific technologies and can therefore be
implemented using a wide range of technologies, including:
• SOAP, RPC
• Web services
• REST
• DCOM
• CORBA
• DDS
• Java RMI
• WCF (Microsoft's implementation of web services now forms a part of WCF)
• Apache Thrift
SOA is not Web Services:
SOA can be a printing shop service, where service consumers upload a set of files which
would be printed with the description of how the printing should be done and where prints
would be mailed to. The Printing service provider will print the files according to the
printing description and mail them to service consumers clients. NO XML is used
whatsoever. Therefore, SOA is not Web Services, but can use Web Services as a communication means.
Thinking in SOA:
Thinking in J2EE terms of Components (your code), Containers (Servlets) and Connectors (JDBC)
and also MVC (Model, View and Controller) is easy for a Java-Web, or a J2EE architect.
How do we think in SOA?
SOA Thinking would be in term of the following:
• Service Providers
• Service Consumers
• Registry
• Binding
• Communication
• Data flow
Service Providers:
Service Providers must design their service as a simple function or a business
process that is well-defined, self-contained, and does not depend on the context or
state of other services. An example of Services would be a printing Service, which
can be self-contained unit of filling out a printing form and upload such form with
files to be printed (let say Microsoft word, or PDF format) to Service Provider server.
Service Consumers:
A service consumer or a web service client locates entries in the broker registry using
various find operations and then binds to the service provider in order to invoke one
of its web services. One Service provider may provide multiple services.
therefore, a service-consumer has do the following:
• Finds the service in the registry
• Binds the service with the service provider
• Accesses the service
Registry:
Registry (SOA registry) is a resource that sets access rights for data that is
necessary for service-oriented architecture projects. An SOA registry allows service
providers to discover and communicate with consumers efficiently, creating a link
between service providers and service customers.
The registry is an information catalog that is constantly updated with information
about the different services in a service-oriented architecture project. The target
goal of an SOA registry is to provide fast, easy access to communication, and to operate
among different applications with limited human intervention.
Implementers commonly build SOAs using web services standards (for example, SOAP) that
have gained broad industry acceptance. There also a lot of standards also provide greater
interoperability and some protection from lock-in to proprietary vendor software. Both
Service Providers and Consumers can implement SOA using any service-based technology,
such as CORBA, Web Services or REST.
The benefits of an SOA registry include:
• Provides comprehensive and integrated SOA governance solution management
• Provides reliability and scalability with performance to all participating enterprises
• Prevents unauthorized access to critical services with the help of object-based scrutiny
• Provides integration with enterprise and partner service registries using standard models
• Reduces the cost involved with the use of universal description, discovery and integration-based consoles
• Provides access to Java and .NET advanced software developer kits in case of
delivering complex registry and repository services to developers and applications
• Provides access to search and browsing facilities, notification services, and API support
• Makes a shared registry and repository services available to deliver comprehensive solutions
• Version management and approval points are involved in workflow processes
Form of Registry or types:
Again, we need to put a structure to a Registry, so what would be a possible structure to a Registry?
Since Registry is a resource that sets access rights for data between Consumers and Providers, then
we may define a Registry as a Structural Metadata which is "data about the containers of data". We may
also categorize them as follows:
• Consumer
• Providers
Registry Services:
We can further defined a Registry to have the following functionalities:
• Search Services
Help with search for Consumers or Providers
• Engagement Services
Help with the engagement between Consumers and Providers
Binding:
The relationship between a service provider and consumer is dynamic;
it is established at runtime by a binding mechanism.
Binding is done in what form? Or what are the possible forms of Binding?
The answer here depends on what type of engagement is it B2B or B2C.
The Binding may need a more complex structure than the Registry (Structural Metadata).
Communication:
The choice of communication will changes and evolves as technology and services changes.
This is a never-end task.
Data flow:
Once communication between Providers and Consumers is established, the flow of
ordering and receiving must be documented and logged for statistic reports,
analysis and evaluation of the SOA a system.
Soliciting and Denying Services:
The question of Providers soliciting Consumers and Providers denying services to certain Consumers needs to be addressed.
We were trying to brainstorm the stage for SOA existence.
Thinking in Term of Tiers:
Dividing an architect into tiers helps with functionality, reusability, scalability, expandability and security.
Looking at our SOA system diagram, we divided the system into the following tiers and sub-tiers:
• Consumers
• Producers
• SOA Hub
o Communication
o Reports and Analysis (the system brain and coordinator)
o Established Communication (Binding)
Consumers Tier:
The entry point for Consumers and need to be managed independently
Producers Tier:
The entry point for Producers and need to be managed independently
SOA Hub Tier:
The Hub is the umbrella that encapsulates all the actions and has sub tiers with each
has specific roles
Communication Sub-Tier:
This sub-tier host all the SOA Hub services and communication. It feeds the Report and
Analysis sub-tier with every transaction with a time stamps.
Reports and Analysis (the system brain and coordinator) Sub-Tier:
This sub-tier is the brain and coordinator of the entire system. It should have some sort of
intelligence and be able to create reports and help with issues and disputes. It manages
security. For example, authentication is run by the communication tier, but access is approved
only by the Reports and Analysis sub-tier.
Established Communication (Binding) Sub-Tier:
This tier helps with Consumers-Producers bind and communicate and also monitor all the
transactions for system statistics and performance. It feeds the Report and Analysis sub-tier with
every transaction with a time stamps.
Questions and Concerns on the following:
• Managing Services
• Testing in SOA space
• Appropriate levels of security
• Higher level of change management governance
Managing Services
both Consumers and Producers must go through a number of processing levels:
• Search - Discover
• Engagement
• Binding
• Established Communication (Binding) -Doing business under the watchful eyes of our Reports and Analysis.
Testing in SOA Space:
With Reports and Analysis keeping track of all transactions and their time stamps, it can
create a true picture of how the system is running. It can also perform analysis, produce
reports, statistics, issues and system performance.
Appropriate levels of Security:
With tiers approach, access can be controlled with Reports and Analysis sub-tier
and we can place Authenticated gates at any entry or processes.
Higher level of change management governance
Reports and Analysis is the boss and no one can dispute its levels of control over the entire system.
go to top
Cloud Computing
A short definition of Cloud computing would be:
•
The practice of using a network of remote servers hosted on the Internet
to store, manage, and process data, rather than a local server or a personal computer.
•
Cloud computing is an expression used to describe a variety of computing concepts
that involve a large number of computers connected through a real-time communication
network such as the Internet.
•
In science, cloud computing is a synonym for distributed computing over a network, and
means the ability to run a program or application on many connected computers at the same
time. The phrase also more commonly refers to network-based services, which appear to be
provided by real server hardware, and are in fact served up by virtual hardware, simulated
by software running on one or more real machines. Such virtual servers do not physically
exist and can therefore be moved around and scaled up (or down) on the fly without
affecting the end user - arguably, rather like a cloud.
As it was mentioned in the definition:
"Cloud computing is an expression used to describe a variety of computing concepts"
We need to quickly cover the definitions of a number of concepts. The reader
may skip the definition table and go to our Cloud Computing presentation.
LAN:
A local-area network (LAN) is a computer network that spans a relatively small area. Most
LANs are confined to a single building or group of buildings, however, one LAN can be
connected to other LANs over any distance via telephone lines and radio waves. A system
of LANs connected in this way is called a wide-area network (WAN).
WAN:
(Wide Area Network) A long-distance communications network that covers a wide geographic
area, such as a state or country. The telephone companies and cellular carriers deploy
WANs to service large regional areas or the entire nation. Large enterprises have their
own private WANs to link remote offices, or they use the Internet for connectivity. Of
course, the Internet is the world's largest WAN.
MAN:
A LAN (local area network) is contained within a building or complex. A MAN (metropolitan
area network) generally covers a city or suburb.
Web Hosting:
A web hosting service is a type of Internet hosting service that allows individuals and
organizations to make their website accessible via the World Wide Web. Web hosts are
companies that provide space on a server owned or leased for use by clients, as well
as providing Internet connectivity, typically in a data center.
Colocation:
Colocation (or co-location) is the act of placing multiple (sometimes related) entities
within a single location.
Colocation is often used in the data sourcing industry to mean off-site data storage,
usually in a data center. This is very important for businesses since the loss of data
can be crucial for companies of any size, up to and including disciplinary action for
employees or loss of their job. An unexpected loss in data can result from fires,
earthquakes, floods, or any sort of natural disaster.
Web Servers:
The term web server can refer to either the hardware or the software that helps to deliver
web content that can be accessed through the Internet. The most common use of web servers
is to host websites, but there are other uses such as gaming, data storage or running
enterprise applications.
XML Web Services:
XML web services use eXtensible Markup Language (XML) messages that follow the SOAP
standard and have been popular with traditional enterprises. In such systems, there
is often a machine-readable description of the operations offered by the service written
in Web Services Description Language (WSDL).
The term Web services describes a standardized way of integrating Web-based applications
using the XML, SOAP, WSDL and UDDI open standards over an Internet protocol backbone. XML
is used to tag the data, SOAP is used to transfer the data, WSDL is used for describing
the services available and UDDI is used for listing what services are available. Used
primarily as a means for businesses to communicate with each other and with clients, Web
services allow organizations to communicate data without intimate knowledge of each
other's IT systems behind the firewall.
Business Services:
Business services is a general term that describes work that supports a business but does
not produce a tangible commodity. Information technology (IT) is an important business
service that supports many other business services such as procurement, shipping and
finance.
Business Service - A service that is delivered to business customers by business
units. For example, delivery of financial services to customers of a bank, or goods to
the customers of a retail store. Successful delivery of business services often depends
on one or more IT services. A business service may consist almost entirely of an IT
service – for example, an online banking service or an external website where product
orders can be placed by business customers.
Application Service Provider (ASP):
Internet hosting provides computer-based services to customers over a network. Software
offered using an ASP model is also sometimes called on-demand software or software
as a service (SaaS). The most limited sense of this business is that of providing access
to a particular application program (such as customer relationship management)
using a standard protocol such as HTTP.
The need for ASPs has evolved from the increasing costs of specialized software that
have far exceeded the price range of small to medium sized businesses. As well, the
growing complexities of software have led to huge costs in distributing the software
to end-users.
eCommerce:
Electronic commerce, commonly known as e-commerce or eCommerce, is a type of industry
where the buying and selling of products or services is conducted over electronic systems
such as the Internet and other computer networks. Electronic commerce draws on
technologies such as mobile commerce, electronic funds transfer, supply chain
management, Internet marketing, online transaction processing, electronic data interchange
(EDI), inventory management systems, and automated data collection systems. Modern
electronic commerce typically uses the World Wide Web at least at one point in the
transaction's life-cycle, although it may encompass a wider range of technologies such
as e-mail, mobile devices, social media, and telephones as well.
Electronic commerce is generally considered to be the sales aspect of e-business. It also
consists of the exchange of data to facilitate the financing and payment aspects of
business transactions. This is an effective and efficient way of communicating within an
organization and one of the most effective and useful ways of conducting business.
Business-to-Consumer (B2C):
B2C is short for business-to-consumer, or the retailing part of e-commerce on the Internet.
Business-to-business (B2B):
Business-to-business (B2B) describes commerce transactions between businesses, such as
between a manufacturer and a wholesaler, or between a wholesaler
and a retailer. Contrasting terms are business-to-consumer (B2C) and
business-to-government (B2G). B2B branding is a term used in marketing.
The overall volume of B2B (Business-to-Business) transactions is much higher than the
volume of B2C transactions. The primary reason for this is that in a typical supply
chain there will be many B2B transactions involving sub components or raw materials,
and only one B2C transaction, specifically sale of the finished product to the end
customer. For example, an automobile manufacturer makes several B2B transactions such
as buying tires, glass for windscreens, and rubber hoses for its vehicles. The final
transaction, a finished vehicle sold to the consumer, is a single (B2C) transaction.
Distributed System:
A distributed system is a software system in which components located on networked
computers communicate and coordinate their actions by passing messages. The components
interact with each other in order to achieve a common goal. There are many alternatives
for the message passing mechanism, including RPC-like connectors and message queues. Three
significant characteristics of distributed systems are: concurrency of components, lack
of a global clock, and independent failure of components. An important goal and challenge
of distributed systems is location transparency. Examples of distributed systems vary
from SOA-based systems to massively multiplayer online games to peer-to-peer applications.
A computer program that runs in a distributed system is called a distributed program, and
distributed programming is the process of writing such programs.
Distributed computing also refers to the use of distributed systems to solve computational
problems. In distributed computing, a problem is divided into many tasks, each of which
is solved by one or more computers, which communicate with each other by message passing.
Infrastructure as a service (IaaS):
In the most basic service model, providers of IaaS offer computers – physical or (more
often) virtual machines – and other resources. IaaS often offer additional resources
such as a virtual-machine disk image library, raw (block) and file-based storage,
firewalls, load balancers, IP addresses, virtual local area networks (VLANs), and software
bundles.
IaaS providers supply these resources on-demand from their large pools installed in data
centers. For wide-area connectivity, customers can use either the Internet or carrier
(dedicated virtual private networks).
Platform as a service (PaaS):
In the PaaS model providers deliver a computing platform, typically including operating
system, programming language execution environment, database, and web server. Application
developers can develop and run their software solutions on a cloud platform without the
cost and complexity of buying and managing the underlying hardware and software
layers. With some PaaS offers (like Windows Azure, the underlying computer and storage
resources scale automatically to match application demand so that the cloud user does not
have to allocate resources manually.
Software as a service (SaaS):
In the business model using software as a service (SaaS), users are provided access to
application software and databases. SaaS is sometimes referred to as "on-demand
software" and is usually priced on a pay-per-use basis. SaaS providers generally price
applications using a subscription fee.
Network as a service (NaaS):
A category of services where the capability provided to the service user is to use
network/transport connectivity services and/or inter network connectivity services. NaaS
involves the optimization of resource allocations by considering network and computing
resources as a unified whole. Traditional NaaS services include flexible and extended
VPN, and bandwidth on demand. NaaS concept materialization also includes the provision
of a virtual network service by the owners of the network infrastructure to a third
party (VNP – VNO).
Service Oriented Architect (SOA):
Service-oriented architecture (SOA) is a software design and software architecture design
pattern based on discrete pieces of software providing application functionality as
services to other applications. This is known as Service-orientation. It is independent
of any vendor, product or technology.
SOA, an application architecture in which all functions, or services, are defined
using a description language and have invokable interfaces that are called to perform
business processes. Each interaction is independent of each and every other interaction
and the interconnect protocols of the communicating devices (i.e., the infrastructure
components that determine the communication system do not affect the interfaces). Because
interfaces are platform-independent, a client from any device using any operating system
in any language can use the service.
Web Architect:
Website architecture is an approach to the design and planning of websites that involves
technical, aesthetic and functional criteria. As in traditional architecture, the focus
is on the user and on user requirements. This requires particular attention to web
content, the business plan, usability, interaction design, information architecture and
web design.
The term architecture can refer to either hardware or software, or to a combination of
hardware and software. The architecture of a system always defines its broad outlines,
and may define precise mechanisms as well.
An open architecture allows the system to be connected easily to devices and programs
made by other manufacturers. Open architectures use off-the-shelf components and conform
to approved standards. A system with a closed architecture, on the other hand, is one
whose design is proprietary, making it difficult to connect the system to other systems.
J2EE:
Java 2 Platform, Enterprise Edition (J2EE) is a platform that enables application
developers to develop, deploy, and manage multi-tier, server-centric, enterprise level
applications.
Data Centers:
A large group of networked computer servers typically used by organizations for the
remote storage, processing, or distribution of large amounts of data.
A data center (sometimes spelled datacenter) is a centralized repository, either physical
or virtual, for the storage, management, and dissemination of data and information
organized around a particular body of knowledge or pertaining to a particular business.
Data Warehouse:
A data warehouse or enterprise data warehouse (DW, DWH, or EDW) is a database used for
reporting and data analysis. It is a central repository of data which is created by
integrating data from one or more disparate sources. Data warehouses store current as
well as historical data and are used for creating trending reports for senior management
reporting such as annual and quarterly comparisons.
Extract, transform, and load (ETL) refers to a process in database usage and especially
in data warehousing that:
Extracts data from outside sources
Transforms it to fit operational needs, which can include quality levels
Loads it into the end target (database, more specifically, operational data store, data
mart, or data warehouse)
ETL systems are commonly used to integrate data from multiple applications, typically
developed and supported by different vendors or hosted on separate computer hardware. The
disparate systems containing the original data are frequently managed and operated by
different employees. For example a cost accounting system may combine data from payroll,
sales and purchasing.
Cloud Computing:
To understand Cloud Computing better we need to look at the following tasks, resources, risks,
cost and companies-individuals needs. Any software team would be working in terms of the categories listed in the following table:
System
Features
Data
Clients
Return On Investment (ROI)
Technologies
Access and Control
Services - software and hardware
Hosting
Testing and Integration
Security
Individuals
Small Companies
Midsize Companies
Large Companies
Cost
Risks
The questions would be:
How can cloud computing helps with these categories
What is the Return On Investment (ROI)?
Let us look at what Google Could - Products is offering at first glance:
• Compute Engine - Infrastructure-as-a-Service (IaaS)
• App Engine - Platform-as-a-Service (PaaS)
• Storage Cloud SQL - Store and manage data
• Cloud Storage - object storage service
• Cloud Datastore - NoSQL, schemaless database
We will let the readers judge for themselves on what Google's Products are offering.
Our challenge is to create guidelines and a scale of evaluating cloud computing services or products.
The best way is to present one my project as an example.
go to top
String Manipulation
Strings are sequences of characters and string manipulation is key when dealing with strings.
Java has number of built-in APIs that developers may use.
Most of interview questions about strings targeting some of the code in the following list of Java classes.
Coding Questions:
Implement code to calculate the value of string “-123456.89” or “123,456.789”. Make
your code extensible and able to parse all strings that can be converted to a numerical
value. Do not use or assume availability of Java parsing libraries.
Implement code which will calculate the value of 2^(3^(4^(5^6))) two different ways.
Do not use or assume availability of math function libraries.
For note, this is a mathematical and not a bitwise operator.
As an example, 2^3 = 8.
We coded this question with:
Coding using String Parsing
Under Construction - "patience is a virtue"
Coming soon
go to top
Recursion
Recursion is simply is when a function calls itself.
Recursion provides an elegant code, but the price for that is that Recursion may end
up in an infinite loop and system may freeze. The code sometimes is hard to understand
especially when dealing with complex trees and linked lists.
Every recursion should have the following characteristics.
• A simple base case which we have a solution for and a return value.
• A way of getting our problem closer to the base case.
Every recursive call must get closer to the goal or end or base case
• A recursive call which passes the simpler problem back into the method.
go to top
Conversions and utils
Under Construction - "patience is a virtue"
These are quick examples' code and we will be adding our notes later.
Coming soon
go to top
Divide and Conquer
Asking academic questions in an interview is not what I am hoping for, since my software skills and real world knowledge are my biggest assests.
Academia verse the Real World
Being an Architect, Project Manager, Developer, Analyst, Consultant, Trainer,
Teacher and also a former professor of computer science had shaped my thinking and
attitude toward many things. I had a fair share of discussions on the question
of "Academia verse the Real World".
Now as a software architect, my answer to the "Academia verse the Real World" question is:
Academia gives us 10% of what the Real World demands out of our work.
The following table has what I deal with on a daily basis:
Hardware & Software
Technologies
Plans
Clients & Teams
Hardware Set up, Environment Set Up, Servers, web browsers, security, log, Clusters (Nodes), firewalls, Proxy servers, memory, databases
Model, View, Controller, J2EE, Java, Mobile technologies, SOA, Design Patterns, RUP, UML, XML, Web services
PM Plans, Models & Standards, Calendar, Tracking, Assessment, Project Check List,
Project Set up, Procurement, Time lines, Deliverables, Work Breakdown Structure, Master Scheduler, Phase & Milestones
Training, Testing, QA, Documentation, Resources,
Analysis, Build Project, budget, business plan
My Divide and Conquer
In computer science, divide and conquer (D&C) is an important algorithm design paradigm
based on multi-branched recursion. A divide and conquer algorithm works by recursively
breaking down a problem into two or more sub-problems of the same (or related) type,
until these become simple enough to be solved directly. The solutions to the sub-problems
are then combined to give a solution to the original problem.
How do I implement Divide and Conquer?
For Divide and Conquer, the following are my tactics:
• Algorithms
• Data and Data Structure
• Techniques and strategies
• Nice to have and have to have
• Common sense
• Reusability
• Architect Templates
• Business Plan Templates
• Do not reinvent the wheel
• If it works do not fix it
• What is the latest and the greatest
• Ask the experts
• Get help if help is needed
• Consult your managers and clients
• Work and brainstorm the architect with your team
We will cover some the tactics rather quickly:
• Algorithms
• Data and Data Structure
• Short Architect Templates
• Short business plan
Algorithms
Algorithm definition:
A step-by-step problem-solving procedure, especially an established, recursive
computational procedure for solving a problem in a finite number of steps.
Algorithm Name
Algorithm definition
Big O notation
Big O notation is used in Computer Science to describe the performance or complexity of
an algorithm. Big O specifically describes the worst-case scenario, and can be used to
describe the execution time required or the space used (e.g. in memory or on disk) by an algorithm.
With this notation an algorithm is said to have a O(n) runtime if the runtime increases linear
with the number of input elements. It has O(n^2) if the runtime increases quadratic, etc.
Producer-Consumers
The producer–consumer problem (also known as the bounded-buffer problem) is a classic example
of a multi-process synchronization problem. The problem describes two processes, the producer
and the consumer, who share a common, fixed-size buffer used as a queue. The producer's job is
to generate a piece of data, put it into the buffer and start again. At the same time, the
consumer is consuming the data (i.e., removing it from the buffer) one piece at a time. The
problem is to make sure that the producer won't try to add data into the buffer if it's full
and that the consumer won't try to remove data from an empty buffer.
The solution for the producer is to either go to sleep or discard data if the buffer is
full. The next time the consumer removes an item from the buffer, it notifies the producer,
who starts to fill the buffer again. In the same way, the consumer can go to sleep if it finds
the buffer to be empty. The next time the producer puts data into the buffer, it wakes up the
sleeping consumer. The solution can be reached by means of inter-process communication,
typically using semaphores. An inadequate solution could result in a deadlock where both
processes are waiting to be awakened. The problem can also be generalized to have multiple
producers and consumers.
Sort
A formula used to reorder data into a new sequence. Like all complicated problems, there are
many solutions that can achieve the same results, and one sort algorithm can re-sequence data
faster than another. Sorting is not quite as conspicuous a process as it used to be; however, reports are
still presented in sequential order, and myriad indexes to hard disk data must be maintained in a sequential order.
In-Memory Sorting:
Today's considerably larger memories enable many sorts to be performed entirely
in memory. However, if there is insufficient memory, a sort program may be able to
store data that is partially sorted temporarily on disk and merge that data later
into the final sequence.
Types of sorts: Bubble sort, insertion sort, merge sort, quick sort, selection sort, pigeonhole sort and counting sort.
Java Collections
Method Description
Collections.copy(list, list) - Copy a collection to another
Collections.reverse(list) - Reverse the order of the list
Collections.shuffle(list) - Shuffle the list
Collections.sort(list) - Sort the list
interface Comparator: public interface Comparator { int compare(T object1, T object2);}
interface Comparable: public interface Comparable { int compareTo(T o);}
Pigeonhole Sorting
Pigeonhole sorting, also known as count sort (not to be confused with counting sort), is a
sorting algorithm that is suitable for sorting lists of elements where the number of
elements (n) and the number of possible key values (N) are approximately the same. It
requires O(n + N) time.
The pigeonhole algorithm works as follows:
Given an array of values to be sorted, set up an auxiliary array of initially
empty "pigeonholes," one pigeonhole for each key through the range of the original array.
Going over the original array, put each value into the pigeonhole corresponding to
its key, such that each pigeonhole eventually contains a list of all values with that key.
Iterate over the pigeonhole array in order, and put elements from non-empty pigeonholes
back into the original array.
Search
In computer science, a search algorithm is an algorithm for finding an item
with specified properties among a collection of items. The items may be stored
individually as records in a database; or may be elements of a search space defined
by a mathematical formula or procedure, such as the roots of an equation with
integer variables; or a combination of the two, such as the Hamiltonian circuits of a graph.
Binary Search
A binary search or half-interval search algorithm finds the position of a specified
input value (the search "key") within an array sorted by key value. In each step, the
algorithm compares the search key value with the key value of the middle element of
the array. If the keys match, then a matching element has been found and its index,
or position, is returned. Otherwise, if the search key is less than the middle
element's key, then the algorithm repeats its action on the sub-array to the left
of the middle element or, if the search key is greater, on the sub-array to the
right. If the remaining array to be searched is empty, then the key cannot be found
in the array and a special "not found" indication is returned.
A binary search halves the number of items to check with each iteration, so
locating an item (or determining its absence) takes logarithmic time. A binary
search is a dichotomic divide and conquer search algorithm.
Traversal
Tree traversal (also known as tree search) refers to the
process of visiting (examining and/or updating) each node in a tree data
structure, exactly once, in a systematic way. Such traversals are classified by
the order in which the nodes are visited. The following algorithms are described
for a binary tree, but they may be generalized to other trees as well.
Depth-First search
Beyond these basic traversals, various more complex or hybrid schemes are
possible, such as depth-limited searches such as iterative deepening depth-first search.
Breadth-First
Trees can also be traversed in level-order, where we visit every node on a level before going to a lower level.
Preorder Traversal
Preorder traversal gets its name from the fact that it visits the root first. In the case of a binary tree, the algorithm becomes:
Visit the root first; traverse the left subtree; and then traverse the right subtree.
Post-order
Post-order traversal visits the root first. In the case of a binary tree, the algorithm becomes:
Visit the root first; traverse the right subtree and then traverse the left subtree.
in-Order
To traverse a binary tree in Inorder, following operations are carried-out:
1) Traverse the left most subtree starting at the left external node,
2) Visit the root
3) Traverse the right subtree starting at the left external node.
Lower Common Ancestor
The lowest common ancestor (LCA) is a concept in graph theory and computer science. Let T
be a rooted tree with n nodes. The lowest common ancestor between two nodes v and w is
defined as the lowest node in T that has both v and w as descendants (where we allow a node
to be a descendant of itself).
The LCA of v and w in T is the shared ancestor of v and w that is located farthest from
the root. Computation of lowest common ancestors may be useful, for instance, as part
of a procedure for determining the distance between pairs of nodes in a tree: the distance
from v to w can be computed as the distance from the root to v, plus the distance from the
root to w, minus twice the distance from the root to their lowest common ancestor.
Data and Data Structure
A data structure is a particular way of storing and organizing data in a computer so that it can be used efficiently.
Different kinds of data structures are suited to different kinds of applications, and some
are highly specialized to specific tasks. Data structures provide a means to manage large amounts
of data efficiently, such as large databases and internet indexing services. Usually, efficient data
structures are a key to designing efficient algorithms. Some formal design methods and programming
languages emphasize data structures, rather than algorithms, as the key organizing factor in software
design. Storing and retrieving can be carried out on data stored in both main memory and in secondary memory.
How do we think in term of Data and its Structure?
How you manage a river and its flashfloods?
We need to cover the following to do justice to Data and Data Structure.
• Data era
• The significant of data
• Intelligence
• Speed and limitation
• Technologies
• Forms of data
• Digitizing data
• Physical and logical
• Conversions
• Normalization and de-normalization
• Input and Output
• Target Audience
• Producers-Consumers
• Data Cleansing
• Data Certification
• Memory and Secondary storages
• Transport of data
• Types of storage
• Gateways
• Hosting
• Encryption
• Security
• Language support - built-in data structure
• Hardware support (data bus)
Short Architect Templates
System Architect:
A system architecture or systems architecture is the conceptual model that defines the
structure, behavior, and more views of a system. An architecture description is a formal
description and representation of a system, organized in a way that supports reasoning
about the structures of the system,
A system architecture can comprise system components, the externally visible properties
of those components, the relationships (e.g. the behavior) between them. It can provide a plan
from which products can be procured, and systems developed, that will work together to
implement the overall system.
Architect Lead:
The Architect is the technical lead who coordinates technical activities and artifacts
throughout the project. He establishes the overall system architecture and
interfaces, provides the use-case implementation, creates plans and guidelines and
helps put together the development team.
System Architect Template:
System Architect is the overall system building blocks and interfaces. It represents
the system tiers and data flow. It should present the following views:
• Tiers
• Deployment
• Data Flow
• Interfaces
• Communication
• Subsystems
• Distributed Systems
• User Interface (UI)
• Shared libraries
• Security
• Performance
• Testing
• Assessment
Tiers:
The term Tier is synonymous with Layer. A system architect may have more that one
tier, for example, an N-Tier architect consists for N number of layers or tiers. Each
has a distinct function(s) in the architect. The following can be considered as an example of a tier:
Deployment:
This view is how system is distributed across servers, platforms or even technologies (Legacy systems, Java, Unix Box).
Data Flow:
It present how data is moved from one tier to another and if there is a need to data conversion and how it is handled.
Interfaces:
The interfaces can come in different shapes and forms. For example, the following may be some of the system interfaces:
• Browsers
• Other Applications
• Databases
• Application Servers
• Web (HTTP) Servers
• LAN
• Different Platforms
• Different Technologies (Legacy systems, Java, JNDI, Unix Box)
Communication:
Tiers, interfaces and objects and services may need to communicate and the architect has
to address such communications. Communication may have different channels, protocols and
forms. For example, the following are some of the communication types:
• HTTP
• FTP
• IMAP
• Sockets
• XML
• COBRA
Subsystems:
A software system can be partitioned into a number of subsystems or units. Each subsystem can be development independently; it may require the development of a number of interfaces. Depending on the design and the partitioning of the system, this may be an advantageous and reduce time, effort and cost. The architect and system analyst may need to address partition question.
Distributed Systems:
Distributed systems provide sharing of resources and information over a computer network, remote sites and databases. Distributed system can open (Internet), closed (LAN) or some thing in between. Architecting such system may need to address the following:
• Performance
• Security
• Errors
• Scalability
• Flexibility
• Transparency (no control, no knowledge or ways test or how to resolve issues)
User Interface (UI):
UI is also known as View Tier. Such tier or an interface may run on LAN, browsers, PCs,
or any where the users will be able to access the system. Architect may need to address UI
and its accessibility.
Shared Libraries:
Shared Libraries can be addressed in the architect or design.
Security:
Security may be provided, by the system platforms, companies’ firewalls and security
systems. The architect may have one or more tiers take on the system security
responsibilities. Servlets, Database objects may perform some security tasks.
Performance:
Identify the system bottlenecks and how are handled.
Testing:
Testing is a crucial part of any system developments. The architect may need to address testing and it could be conducted on each of the system tiers, interfaces. He should flag if system testing may require special equipments. Risks and concerns should be also discussed.
Pros and Cons:
The architect should prepare a Pro and Con Sheet, where he would be playing the devil advocate.
The team members should be involved in the architect designs and give their feedback.
Assessment:
Assessment is the process of documenting, usually in measurable terms, knowledge,
skills, attitudes and beliefs. Project assessment may include the following:
• Project objectives have been met
• Project artifacts have been completed
• Project models and schedules have been updated.
• Should the project move to the next phase
Questions:
• Do we have a clear proposed project?
• Could we have a better project design?
• What are project strengths and weaknesses?
• What aspects of the project that might have been missed?
• If we rewind the project tape (go back in time), what should we have done differently?
• Return on the investment?
Objective and Subjective Assessment:
Objective:
Objective assessment has a form of questioning which has a single correct answer. It is
becoming more popular due to the increased use of online assessment and its questions
are easy to answer. The questions would include true/false answers, multiple choice,
multiple-response and matching questions.
Subjective:
Subjective assessment has a form of questioning which may have more than one correct
answer or more than one way of expressing the correct answer. Its questions include
extended-response questions and essays.
Short Business Plan
What is a Business Plan?
According to Wikipedia, the free encyclopedia:
“A business plan is a formal statement of a set of business goals, the reasons why they are
believed attainable, and the plan for reaching those goals. It may also contain background
information about the organization or team attempting to reach those goals.
The business goals may be defined for for-profit or for non-profit organization. For-profit
business plans typically focus on financial goals, such as profit or creation of wealth.
Non-profit and government agency business plans tend to focus on organizational mission
which is the basis for their governmental status or their non-profit, tax-exempt status,
respectively—although non-profits may also focus on optimizing revenue. In non-profit
organizations, creative tensions may develop in the effort to balance mission
with "margin" (or revenue). Business plans may also target changes in perception and
branding by the customer, client, tax-payer, or larger community. A business plan
having changes in perception and branding as its primary goals is called a marketing plan.
Marketing Plan:
A marketing plan is a written document that details the necessary actions to achieve one
or more marketing objectives. It can be for a product or service, a brand, or a product
line. Marketing plans cover between one and five years. A marketing plan may be part of
an overall business plan. Solid marketing strategy is the foundation of a well-written
marketing plan. While a marketing plan contains a list of actions, a marketing plan
without a sound strategic foundation is of little use.”
Summary of Our Business:
We are presenting a Summary of our Business and Marketing Plans to help our supporters
and investors perceive our project without overwhelming technical details that we have
in our detailed Business and Marketing plans. Our Business and Marketing Plans will
include the requirement, architect/design, budget, deliverables, management plans and
milestones. We as a team believe that the business plan(s) should be the creation of
our project on paper. This means that the project should be created on paper first, before
the development of the project. Such creation will help eliminate errors,
misunderstandings, bugs, overdesign, overlooked issues and items, and a number of
business and architect-design-development issues. The creation may take more time and
effort, but the overall saving of money, effort and time is well worth it.
The following are the topics in the summary of a Business Plan:
• Introduction
• Executive Summary
• Proposed System
• Technology Used
• Business Description
• Products/Services
• Building a Running Model
• System Components
• Management Plan
• Milestones
• Competition
• Risk Assessment
• Business Position
• Marketing Plan
• Cost
• Balance Sheet
go to top
Browser Side verse Server Side
As a web architect, the question of Browser Side verse Server Side is part of the architect strategies.
How much coding load (calculation, error checking, processes, online help, etc) does the client wants
to move from the server to browser-side. Moving the code to the browser-side and letting site visitor's
computer does the work for your application is definitely a plus. But there is nothing for free.
The price or the disadvantages are developing client-side which requires scripting languages plus
more development time and effort. Not to mention the code on the browser-side must support different browsers
and must work with different browser's type, Firefox, MS Explorer, Google Chrome and the list is not short.
The disadvantage of server-side processing is the page postback: it can introduce processing overhead that
can decrease performance and force the user to wait for the page to be processed and recreated.
Once the page is posted back to the server, the client must wait for the server to process the
request and send the page back to the client.
There are many advantages to client-side scripting including faster response times, a more
interactive application, and less overhead on the web server. Client-side code is ideal when
the page elements need to be changed without the need to accessing the database. A good example
would be to dynamically show and hide elements based on user inputs. One of the most common
examples is input validation and Microsoft’s Visual Studio includes a set of client-side
validation controls.
Coding Questions:
Please write a simple Java web application, which prompts the user for series
of 5 digit numbers and then outputs a set of two values based on those numbers. The
first value o the set outputted should be the average and the second should be
the median. The average is simply adding up all the entries and dividing them
by the number of entries. The median is the middle value of the series, if the
series is sorted from highest to lowest value. If there is an even number of
entries, then the median is the average of the middle two numbers in a sorted series.
For example, if the user enters: 55555 66666 77777; the application should output:
Average: 66666
Median: 66666
Th application should contain at least on JS file and at least one Servlet. To
kick off the application the user must view and submit a web form, which posts
t the application. The application will then generate the set o two values using
an efficient algorithm and display the result back to the user on the browser. Extensive
work on the style of the user interface is not required, because the backend
application is the essential element of this task. Using industry standards and
recommended solutions is expected. Also the submission needs to be a fully compilable
and runnable application. Only the .java and .jsp files need to be submitted (and
any .js, .html and .css files if available), no configuration o XML files ar necessar
either. Consider this a production level application, where proper commenting and
robustness is expected. Also consider future extensions, enhancements and scaling.
The following code has two JSP pages that illustrate the difference strategies of Browser
Side verse Server Side in term code and process time.
go to top
Java Side verse Database Side
Java Side verse Database Side which one would you selected in your architect-design?
Our answer: which side totally depends on the case at hand.
Let us looking at the following SQL code:
SELECT column_name FROM table_name ORDER BY column_name DESC;
Let us address that SQL code in term of the following criteria?
Size of the table, type of the data, time to process, resources (servers, memory for
cashing), effort, debugging, security, reusability, maintenance, object caching
mechanism, packaging and deployment, Threads, Persistent Session, Connection Pooling,
Internationalization, Localization and Debugging.
Based on the case, an architect-design would be hopping between Java-side and database-side.
Well, we are not stopping at this issue, but we are introducing our concept
of Data Services Object (not to be confused with web services). Hibernate
eliminated JDBC out of the Java code and provided caching mechanism and data persistent.
Our Data Services Object comes from a box (with both java-side and Database-side code) where it
provides services to help Intelligent systems have all the possible data and options
to present to business objects and/or clients.
looking at our example of "Banana" search (done by our "Search Index Table 3021(Student-Dependent) -
on Friday at 4:00 PM Chicago time") in our "SQL and Tables Design" section, the developer will
be filling out a form (Data Object) with keys and IDs for our Data Services to return a Data Services Object with all of the following:
Array List of Images
Array list of Questions
Array list of options
Arrays list of malls, stores, traveling distance and directions
Arrays list of METRA schedules and prices.
Array list of events
Also possible data object with instructions on how to use these arrays lists.
Our data base will also have all data provided by the outside vendors that had done their market research.
In conclusion, we would be turning any database into an Intelligent Data Services Object that Think-in-Abstract.
The reusability of such Data Services Object is the icing on the cake.
go to top
Testing, Logger and Architect
There is new title called Test Architect. The primary responsibility of a test architect is
to provide technical leadership and strategic direction for their testing organization. Test
architects focus on a diverse set of goals and perform a wide variety of tasks. Some spend
time developing testing infrastructure, test authoring frameworks, or evaluating features
in order to create complex tests. Some are in charge of a particular technology for their
group. A test architect has in-depth knowledge of a variety of testing techniques and methodologies
used. A test architect often provides technical assistance and/or advice to the test Manager.
What Software Testing?
Testing is the process of achieving error free system.
There should be a test plan, which includes unit test, stage development testing and system testing.
The design should include testing stages and plans. Testing teams and tools should be available.
Usecase Testing:
Usecase testing is a technique that helps software team identify test cases that exercise
the whole system on a transaction by transaction basis from start to finish.
Unit Testing:
Unit test spec is a document, which is for programmers as a guideline on how to test code module.
Unit testing may involve the programmer, group manager and client.
White-box Testing:
White-box testing (also known as clear box testing, glass box testing, transparent box testing and
structural testing) tests internal structures or workings of a program, as opposed to the functionality
exposed to the end-user. In white-box testing an internal perspective of the system, as well as
programming skills, are used to design test cases.
While white-box testing can be applied at the unit, integration and system levels of the software
testing process, it is usually done at the unit level.
Black-box testing:
Black-box testing treats the software as a "black box", examining functionality without any knowledge
of internal implementation. The tester is only aware of what the software is supposed to do, not how it
does it.
Black-box testing methods include:
Equivalence partitioning, boundary value analysis, all-pairs
testing, state transition tables, decision table testing, fuzz testing, model-based testing, use case
testing, exploratory testing and specification-based testing.
QA testing – Integration Testing:
Unit testing does not take care of all errors due to interfaces and different module calling.
Testing all the modules at once is called integration testing.
Persons other than programmers should do this testing.
There should be dedicated testers whom are part of Quality Assurance group (QA).
QA should be an independent group from the client side, who will sign off on whatever they have tested.
QA testing should be part of the design and planned ahead of time.
Benchmark Testing:
A benchmark testing is to compare the testing performance of the developed system
to a previously developed or an existing system testing as reference.
Functionality:
There are certain standards which are followed in almost all the software testing. Having
these standards makes life easier for use, because these standards can be converted into
checklist and the software testing can be used easily against the checklist. Functionality
Tests may include the following tests types.
Stress Testing:
A stress test is to focus on running abnormal conditions as well extreme values that the system may encounter.
Stresses on the system may include the following:
1. Extreme workloads including max and min integers or floats
2. Insufficient memory and memory management
3. Unavailable services and hardware
4. Infinite loops
5. Accessing resource that may not be available or limited.
6. Stress the bottlenecks of the system.
7. Time Stamp
Structural Testing:
White box testing technique which takes into account the internal structure of a system or
component and ensures that each program statement performs its intended function. It is
usually performed by the software developers.
System Testing:
The process of testing an integrated hardware and software system to verify that the system
meets its specified requirements. It is conducted by the testing teams in both development
and target environment.
System Integration Testing:
Testing process that exercises a software system's coexistence with others.
Performance Testing:
Functional testing conducted to evaluate the compliance of a system or component with specified performance requirements.
Breadth Testing:
A test suite that exercises the full functionality of a product but does not test features in detail.
Reliability:
Reliability testing is used to determine the system reliability such as Boundary , Special Case, and Build Verification test (BVT).
What is Boundary Testing?
A test data selection technique in which values are chosen to lie along data extremes. Boundary values include maximum, minimum, just inside/outside boundaries, typical values, and error values. The hope is that, if a systems works correctly for these special values then it will work correctly for all values in between.
Special case:
This used for testing cases that may require special data, values and or sequence of steps.
What is BVT?
Build Verification test is a set of tests run on every new build to verify that build is testable before it is released to test team for further testing. These test cases are core functionality test cases that ensure application is stable and can be tested thoroughly. Typically BVT process is automated. If BVT fails that build is again get assigned to developer for fix.
Thread Testing:
Test for Thread-Safe run. For example, 10 threads would be created and tested to check for deadlock, errors or side effects.
Regression Testing:
Type of software testing that seeks to uncover software errors after changes to
the program (e.g. bug fixes or new functionality) have been made, by retesting the program.
Security Testing:
A process to determine that an information system protects data and maintains functionality as intended.
It may have a list of security check points that the system must pass and errors and exceptions handling.
Top Down Integration Testing:
Testing technique that involves starting at the stop of a system hierarchy at the user
interface and using stubs to test from the top down until the entire system has been implemented.
Regression Testing:
Type of software testing that seeks to uncover software errors after changes to the
program (e.g. bug fixes or new functionality) have been made, by retesting the program.
Logger:
What is Logging?
Logging refers to the recording of activity. Logging is a common issue for development
teams. In the past, write lines or print statements were the only logging tools, but currently
there is a number of logging tools such as Log4J, and java.util.logging.Logger. They also come
with helpful APIs and structures that can be used with any Java code.
Logging and Testing:
Testing is the process of achieving error free system.
Logging is the process of writing messages to an output (screen, files, SMTP-Mail, sockets
or any printable media).
Testing may benefits greatly from logging as a form of tracing tool for errors, warnings, data
dump and processing time.
Sadly logging comes with a performance overhead and may be a bottleneck if the media for writing
messages would have performance issues. For example, Logging is an I/O intensive activity and can get in the way of the application's performance. With the fact that logging code is synchronized may lead to slowing the system even more.
Using Assertions:
Assertions ensure a program’s validity by catching potential bugs and identifying possible logic errors during development.
To enable assertions at runtime, -ea command-line option is used.
The following is quick example:
go to top
System Performance and Bottlenecks
As I mentioned in the "Architect 2 Show" section: To me architecting
is a tool, God-given-talent, an art, an expression and a communication
media. Knowledge, experience and an open mind to other views are key ingredients.
My analogy of an architect role is that of a Football Quarterback, who
is the center of the entire offense. The Quarterback not only manages his
team mates, but also has his eyes and ears on the opponent defense and their tactics.
The Quarterback knows he cannot do the job alone and his success is tied to
his team members' performance.
Therefore, what would an architect would looking at when it comes to System
Performance and Bottlenecks.
The following is project components and theirs
Risks (high in red color)
and Bottlenecks (underlined) associated with them:
Workers
Artifacts - Data
Resources
Technologies and Approaches
Clients:
• Business-clients-stakeholders
• Timeline
• Change Control
• Training
• Marketing
• Engagement
Team:
• PM
• Developers
• Testers
• QA
Task at Hand
• Budget
• Data (may not be available)
• Documentation (Requirement, Analysis,...)
• Standards
• Development
• Security
• Risks
• Testing
Software and Hardware
• Tiers (MVC)
• Frameworks
• Components
• Containers - Vendors
• Servers - Browsers
• Interfaces
• Databases
• Legacy System
• Training
Approach:
• Java
• Web
• Mobile
• Web Services
• Rational Unified Process (RUP)
• Agile - Scrum
• Waterfall
Model:
• Business Model
• Data Models
• Deign Model
• Testing Model
Any of the items in the table can turn into a High Risk and or a Bottleneck.
From the table we can see that the following can be both High Risks and also Bottlenecks:
• Business-clients-stakeholders
• Security
• Interfaces
• Legacy System
How to handle Risks and Bottlenecks?
Experience shows that most issues are kind of unique, but they do have a number of similarities.
The following is our guidelines of how to handle issues in general:
• A good architect-design would eliminate most of the Risks and Bottlenecks.
• Must identify the Risks and have both Risk analysis and handling
• Must identify the Bottlenecks and the their cause.
• The first answer is team work and brainstorm each issue with your team.
• Work with your supervisors and the clients and keep them informed.
• Look at previous experiences that are similar and how they were handled in the past.
• Work the issue backward and try to find an answers - Critical Path approach.
• Search the web for possible solution or an alternative.
• Brainstorm Risk Acceptance, Risk Avoidance and Risk Transference.
• Call friends and colleagues for help.
go to top
Intelligent System
How to define an Intelligent System?
First Issue:
There is a lack of understanding or the knowledge of Intelligent Systems. This is very
obvious in any software system discussion. For example, when discussing Intelligent
System with colleagues or interviewers, my personal observation
is that the their body language, complete silence and no further questioning or
discussion indicates their uneasiness discussing such subject.
The issue here is:
How would anyone be able to present Intelligent Systems to these IT professionals?
Sadly, Hollywood has painted a very farfetched image of Intelligent Systems and one
day, Intelligent Systems will take over the world.
Looking at the following animals:
Chimps, Elephants and Crows
Are these animals considered intelligent?
When describing someone as "bird brain" would that be considered a complement?
These animals show a level of intelligence based on their ability to reason, solve problems,
count, communicate, self awareness, and some scientists have equated them with the intelligence
level of 4-6 years old human children.
Do we need to rank the intelligence of a computer system and how?
Intelligence has been defined in many different ways including, but not limited to:
1. Abstract thought
2. Understanding
3. Self-awareness
4. Communication
5. Reasoning
6. Learning
7. Having emotional knowledge
8. Retaining
9. Planning
10. Problem solving.
Intelligence is most widely studied in humans, but has also been observed in animals and in plants.
Artificial intelligence is the simulation of intelligence in machines. Within the
discipline of psychology, various approaches to human intelligence have been adopted.
What is an Intelligent Software System?
We as human beings, when we address anything as intelligent, we are implying that
thing has human-like characteristics as mentioned above.
We need to identify what makes a software system intelligent?
The following software capabilities define any software as "Intelligent:"
1. Plans
2. Solves problems
3. Does the footwork
a. Calculates values
b. Checks errors
c. Flags errors
d. Tracks
e. Corrects - example: corrects your spelling, etc.
4. Creates reports and statistics
5. Reminds - calendar
6. Gives choices
7. Searches
8. Compares products - processes
9. Communicates
10. Performs abstract thinking
11. Understanding - parsing
12. Self-awareness
example: system parts are not working - find errors, exceptions and misuse
13. Reasoning
example: figure bargains based on user income and shopping habits
14. Learning
15. Retaining - self correcting
16. Has dynamic business rules
Assume that each category is equal to 5% (100 / 21 = 4.76%) of intelligence, then
we can use such measures to scale the percentage of the system intelligence.
go to top
Miscellaneous
Under Construction - "patience is a virtue"
Coming soon
go to top
Spring Framework
Spring Framework and EJB are some of the frameworks that I never had the chance to work or even
worked on a project that is based on them. Therefore, Our attempt to present Spring is based on
my academic view and not the real world view.
What is Spring Framework?
It is a replacement of EJB by Rod Johnson who is an Australian computer specialist who created
the Spring Framework and co-founded SpringSource.
Spring is a framework for development of Enterprise applications.
Spring framework can be used in modular fashion (loosely coupled), it allows to use in parts and
leave the other components which is not required by the application.
The following are the basic structure of any Spring Framework:
What are the basic structure of any Spring Framework Application?
Searching the web, the Spring documentation and architecture images are overwhelming and very confusing and not to mention the new Spring buzzwords are kind of misleading. For example, the word "Aspect" has the following synonymous meanings:
So "Aspect Oriented Programming (AOP)" could have been called "Feature Oriented Programming (FOP)" based Feature and not Aspect. Therefore the Aspect of Spring Framework may not be simple to understand.
Our approach to any structure is to draw a picture of the components and their functionalities and communication. The following image is our take on Spring Framework Architecture.
Tiers, Servers and Components (plus a review material for other concepts):
Component Name
Definition
Browser
Browser regardless of the browsers' vendor is the main user's access to any web system.
It also can be a part that accesses cloud computing services.
View (MVC)
MVC: View is the User Interface on the browser side.
Remote Clients
Clients may have access to spring framework using a number of technologies such as Web Services, Cloud Computing of even Service Oriented Architect (SOA).
Could Computing
A Spring Framework can also work a cloud computing services.
Web Server
A web server is a server that has the World Wide Web's Hypertext Transfer Protocol (HTTP).
It also can serve as an application server and database server as most of hosting services are.
Servlets
A Java application that runs in a Web server or application server and provides server-side
processing such as accessing a database and e-commerce transactions. Widely used for Web
processing, servlets are designed to handle HTTP requests (get, post, etc.) and are the
standard Java replacement for a variety of other methods, including CGI scripts, Active
Server Pages (ASPs) and proprietary C/C++ plug-ins for specific Web servers (ISAPI, NSAPI).
Servlets are written in Java, servlets are portable between servers and operating
systems. The servlet programming interface (Java Servlet API) is a standard part of the
Java EE platform. If a Web server, such as Microsoft's Internet Information Server
(IIS), does not run servlets natively, a third-party servlet plug-in can be installed
to add the runtime support.
Tomcat is an application server from the Apache Software Foundation that executes Java
servlets and renders Web pages that include Java Server Page coding.
Controller (MVC)
MVC: Controller (enterprise web application)
Tomcat can be the enterprise web container that executes Java
servlets and renders Web pages that include Java Server Page coding.
Web (remote)
Spring features integration classes for remoting support using various technologies.
The remoting support eases the development of remote-enabled services, implemented by your usual (Spring) POJOs.
Currently, Spring supports four remoting technologies:
Remote Method Invocation (RMI). Through the use of the RmiProxyFactoryBean and
the RmiServiceExporter Spring supports both traditional RMI (with java.rmi.Remote interfaces
and java.rmi.RemoteException) and transparent remoting via RMI invokers (with any Java interface).
Spring's HTTP invoker. Spring provides a special remoting strategy which allows for Java
serialization via HTTP, supporting any Java interface (just like the RMI invoker). The corresponding
support classes are HttpInvokerProxyFactoryBean and HttpInvokerServiceExporter.
Hessian. By using Spring's HessianProxyFactoryBean and the HessianServiceExporter you can transparently
expose your services using the lightweight binary HTTP-based protocol provided by Caucho.
Burlap. Burlap is Caucho's XML-based alternative to Hessian. Spring provides support classes such as BurlapProxyFactoryBean and BurlapServiceExporter.
JAX-RPC. Spring provides remoting support for web services via JAX-RPC (J2EE 1.4's web service API).
JAX-WS. Spring provides remoting support for web services via
JAX-WS (the successor of JAX-RPC, as introduced in Java EE 5 and Java 6).
JMS. Remoting using JMS as the underlying protocol is supported via
the JmsInvokerServiceExporter and JmsInvokerProxyFactoryBean classes
Application Server
Application Services are the main workhorse for any system.
It is the organization's backend business applications and/or databases.
Application servers have two meaning, the first is actual physical server that have all
your software running for internal use. The second is that An application server (software program)
provides a generalized approach to creating an application-server implementation, without
regard to what the application functions are, or the server portion of a specific
implementation instance. In either case, the server's function is dedicated to the efficient
execution of procedures (programs, routines, scripts) for supporting its applied applications.
Model (MVC)
MVC: Model – (data and Business classes)
Looking at our diagram, the Model can be the entire organization business code that is required to service the front tiers.
AOP
One view of aspect-oriented software development is that an Aspect can be:
• Every major feature of the program
• Core concern (business logic)
• Cross-cutting concern (additional features)
By weaving them together (a process also called composition), one finally produces a whole
out of the separate aspect. This approach is known as pure aspect programming, but hybrid
approaches are more commonly used, perhaps since there is less of a paradigm shift between
object- and aspect-oriented programming.
Injector
Dependency Injection (DI):
Dependency injection is a software design pattern that allows the removal of hard-coded
dependencies and makes it possible to change them, whether at run-time or compile-time.
This can be used, for example, as a simple way to load plugins dynamically or to choose
stubs or mock objects in test environments vs. real objects in production environments.
One of its core principles is the separation of behavior from dependency resolution.
Definition:
Dependency injection involves at least three elements:
1. a dependent consumer,
2. a declaration of a component's dependencies, defined as interface contracts,
3. an
injector
(sometimes referred to as a provider or container) that creates instances of classes that implement a given dependency interface on request.
Declarative Transaction Management
Declarative Transaction Management
This means you separate transaction management from the business code.
You only use annotations or XML based configuration to manage the transactions.
Declarative transaction management is preferable over programmatic transaction
management though it is less flexible than programmatic transaction management, which
allows you to control transactions through your code. But as a kind of crosscutting
concern, declarative transaction management can be modularized with the AOP approach. Spring
supports declarative transaction management through the Spring AOP framework.
Core
The Core Container consists of the Core, Beans, Context, and Expression Language modules.
The Core and Beans modules provide the fundamental parts of the framework, including the IoC and Dependency Injection features.
Context
Context
The Context module builds on the solid base provided by the Core and Beans modules: it
is a means to access objects in a framework-style manner that is similar to a JNDI
registry. The Context module inherits its features from the Beans module and adds
support for internationalization, event-propagation, resource-loading, and the transparent
creation of contexts by, for example, a Servlet container.
Beans
Beans:
The objects that form the backbone of your application and that are managed by the
Spring IoC container are called beans. A bean is an object that is instantiated,
assembled, and otherwise managed by a Spring IoC container. These beans are created
with the configuration metadata that you supply to the container.
The bean definition contains the information called configuration metadata which is
needed for the container to know the followings:
• How to create a bean
• Bean's lifecycle details
• Bean's dependencies
All the above configuration metadata translates into a set of the following properties that make up each bean definition.
IoC Container
The interface org.springframework.context.ApplicationContext represents the Spring IoC container
and is responsible for instantiating, configuring, and assembling the aforementioned
beans. The container gets its instructions on what objects to instantiate, configure, and
assemble by reading configuration metadata. The configuration metadata is represented in
XML, Java annotations, or Java code. It allows you to express the objects that compose your
application and the rich interdependencies between such objects.
Programmatic Transaction Management
Programmatic Transaction Management
This means that you have manage the transaction with the help of programming. That gives
you extreme flexibility, but it is difficult to maintain. Spring provides two means
of programmatic transaction management:
• Using the TransactionTemplate
• Using a PlatformTransactionManager implementation directly
Programmatic transaction management is usually a good idea only if you have a small
number of transactional operations.
DAO
Data Access Object (DAO)
DAO stands for data access object which is commonly used for database interaction. DAOs exist
to provide a means to read and write data to the database and they should expose this functionality
through an interface by which the rest of the application will access them.
The Data Access Object (DAO) support in Spring makes it easy to work with data access technologies
like JDBC, Hibernate, JPA or JDO in a consistent way.
Database Server
A database server is a computer program that provides database services to other computer
programs or computers, as defined by the client–server model. The term may also refer
to a computer dedicated to running such a program. Database management systems frequently
provide database server functionality, and some DBMSs (e.g., MySQL) rely exclusively on
the client–server model for database access.
JDBC (MVC Controller)
JDBC is a Java-based data access technology (Java Standard Edition platform) from
Oracle Corporation. This technology is an API for the Java programming language that
defines how a client may access a database. It provides methods for querying and
updating data in a database. JDBC is oriented towards relational databases. A JDBC-to-ODBC
bridge enables connections to any ODBC-accessible data source in the JVM host environment.
ORM
Object Relational Mapping (ORM) data access
The Spring Framework provides integration with Hibernate, JDO, Oracle TopLink, iBATIS
SQL Maps and JPA: in terms of resource management, DAO implementation support, and transaction strategies.
Hibernate
Hibernate an open source Java persistence framework project. Perform powerful object relational mapping and query databases using HQL and SQL.
JDO
Java Data Objects (JDO) is a specification of Java object persistence. One of its
features is a transparency of the persistence services to the domain model. JDO
persistent objects are ordinary Java programming language classes (POJOs); there
is no requirement for them to implement certain interfaces or extend from special classes.
iBATIS
iBATIS is a persistence framework which automates the mapping between SQL databases and
objects in Java, .NET, and Ruby on Rails. In Java, the objects are POJOs (Plain Old Java
Objects). The mappings are decoupled from the application logic by packaging the SQL
statements in XML configuration files. The result is a significant reduction in the amount
of code that a developer needs to access a relational database using lower level APIs like JDBC and ODBC.
Spring Security
Spring Security is a Java/Java EE framework that provides authentication, authorization and other security features for enterprise applications.
Test
Spring provides a comprehensive support for unit and integration testing – through
annotations to load up a Spring application context, integrate with unit testing
frameworks like JUnit and TestNG.
Test (Injection)
When Spring integration testing support frameworks load your application context, they
can optionally configure instances of your test classes via Dependency Injection. This
provides a convenient mechanism for setting up test fixtures using pre-configured beans
from your application context. A strong benefit here is that you can reuse application
contexts across various testing scenarios, thus avoiding the need to duplicate complex
test fixture set up for individual test cases.
Concern
In computer science, a concern is a particular set of information that has an effect
on the code of a computer program. A concern can be as general as the details of
database interaction or as specific as performing a primitive calculation, depending
on the level of conversation between developers and the program being discussed.
Cross-cutting
In computer science, cross-cutting concerns are aspects of a program that affect
other concerns. These concerns often cannot be cleanly decomposed from the rest of
the system in both the design and implementation, and can result in either
scattering (code duplication), tangling (significant dependencies between systems), or both.
BeanFactory Container
This is the simplest container providing basic support for Dependency Injection (DI) and defined by
the org.springframework.beans.factory.BeanFactory interface. The BeanFactory
and related interfaces, such as BeanFactoryAware, InitializingBean,
DisposableBean, are still present in Spring for the purposes of backward
compatibility with the large number of third-party frameworks that integrate with Spring.
ApplicationContext
The ApplicationContext includes all functionality of the BeanFactory, it is generally
recommended over the BeanFactory. BeanFactory can still be used for light weight
applications like mobile devices or applet based applications.
ApplicationContext
vs BeanFactory
ApplicationContext vs BeanFactory
BeanFactory is a subset of ApplicaitonContext and provides lesser functionalities. When we
need full capabilities with respect to configuration handling then we go for ApplicationContext.
go to top
Code Assignment by Interviewers
Interviewers do sometimes ask the job seeking candidates to perform a code assignment as a proof
of the candidate's talent. This is definitely a good thing but most of the time the interviews are
looking for what is often not clear to the candidates. Therefore, the best way to present my
talent, show knowledge and capabilities is to create an Overkill of the assignment hoping such
an Overkill would answer all the interviewers' expectations.
To save me and you time, effort and space on my web page, the following are zipped projects that you
are free to download and check them on your own time and machines. I would be more than happy to answer any question.
The following are coding assignments for the following companies: