
Sam Eldin |
CV - Resume | Tools 4 Sharing | Architects 2 Show | Big Data Presentation | Android Training | Java-Unix Code Templates | Interviews QA & Code |
|---|
|
|---|
|
Machine Learning
Any architect and technical lead must address and keep up with latest and the greatest. We architect-develop Intelligent System, Automation, Virtualization, Business Intelligence and Data Streaming. Now we need to address Machine Learning and see how can we contribute to such new tool. What differentiate our architect from what the world is offering is Intelligence. Therefore, we are present our Intelligent Machine Learning and the following is our view point and approach including developing Intelligent Machine Learning code. • IT Dilemma • Chicken or Egg: Which Came First? Data Mining or Machine Learning • What is the difference between Data Mining or Machine Learning? • Algorithms and Model • Data Bias or Real World Data • Data Parsers and Convertors • Intelligent Machine Learning IT Dilemma: For years, the big players in the Information Technology have been renaming the same technologies and methodologies with hardly any new improvement and then they would sell these new tools (toys) back to the IT community. We are not sure why such a pattern is done. There is a number of possibilities such as keeping the IT community from getting bored, or it is a marketing technique to keep the IT community buying their new products. Sadly, the IT community buys these renamed products (toys) and also start demanding everyone to have the skills with these new tools or products. Not to mention, companies race to be the leader of these new toys. Take Java as an example, there is a divide-line in the IT community between having Core Java skills or new Java. Now, Machine Learning is coming on the scene, we also would ask: What is the difference between Data Mining and Machine Learning? Chicken or Egg: Which Came First? Data Mining or Machine Learning: Data Mining: Data mining is the process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems. Data mining is the analysis step of the "knowledge discovery in databases" process or KDD. Aside from the raw analysis step, it also involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating. Machine learning (ML): Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and deduction instead. It is seen as a subset of artificial intelligence. Machine learning algorithms build a mathematical model based on sample data, known as "training data", in order to make predictions or decisions without being explicitly programmed to perform the task. There are many different types of machine learning algorithms, with hundreds published each day, and they are typically grouped by either learning style (i.e. supervised learning, unsupervised learning, semi-supervised learning) or by similarity in form or function (i.e. classification, regression, decision tree, clustering, deep learning, etc.). What is the difference between Data Mining and Machine Learning? Both data mining and machine learning fall under the guidance of Data Science, which makes sense since they both use data. Both processes are used for solving complex problems, so consequently, many people use the two terms interchangeably. Considering that machine learning is sometimes used as a means of conducting useful data mining. While data gathered from data mining can be used to teach machines, so the lines between the two concepts become a bit blurred. Furthermore, both processes employ the same critical algorithms for discovering data patterns. Sadly, almost every article written is trying very hard to convince us that Data Mining is NOT Machine Learning, but the reality is they both produce the same results. In short, both are nothing but processes of "discovering data patterns" or finding repeated patterns in given data sets. Machine Learning Algorithms and Model Search the internet for Machine Learning Algorithms and Model principles, we found the Images #1 and #2 presenting the components of Learning Algorithms. Sadly, we do not believe these Machine Learning approaches would work with real world diverse and complicated data. Therefore, we will not spend any energy on these approaches and we will be presenting our intelligent, dynamic and flexible Machine learning processes. 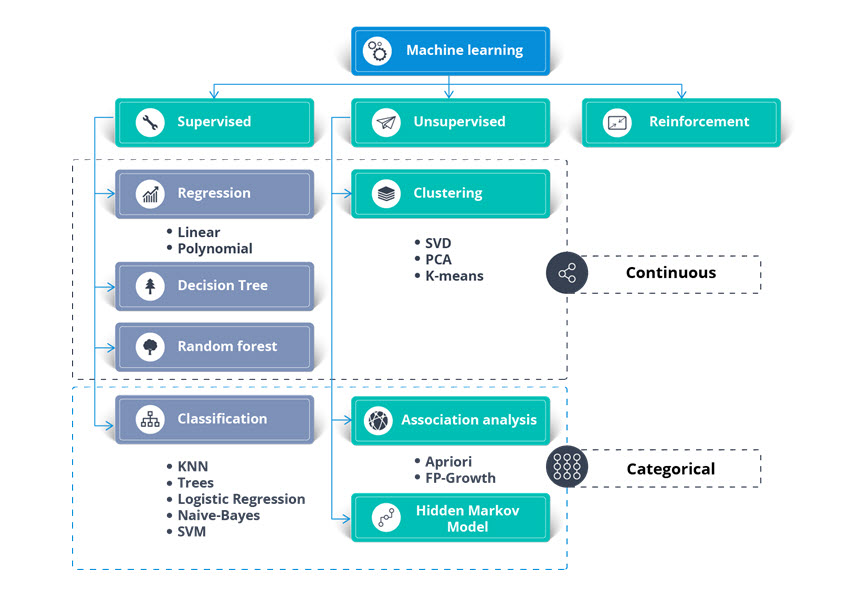
Image #1 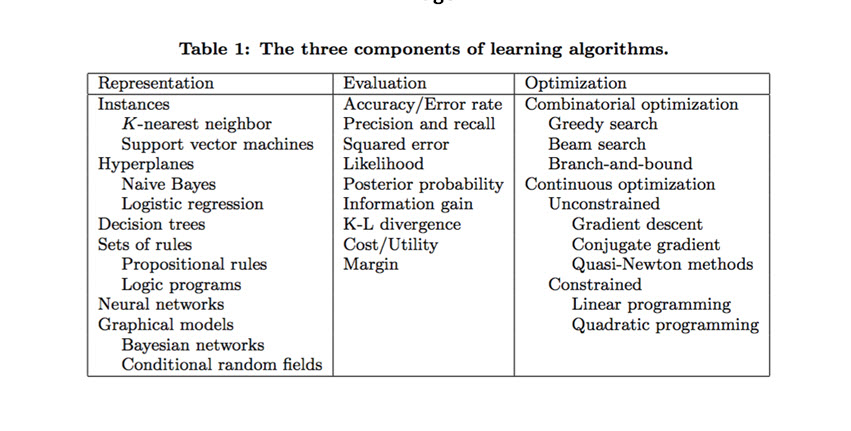
Image #2 Data Bias or Real World Data 
Image #3 Looking at Image #3, we need to ask the following: • How would Machine Learning find this specific Donald in the two toys bags? • How would Machine Learning find any toy which resembles Donald toy in the two toys bags? • Data Bias is where data is very much fabricated for the algorithms and models to succeed. • How to handle real world data and all of its complexities? When it comes to real world data, we have to deal with data capture, type, size, complexity, format, storage, analysis, data creation, search, sharing, transfer, visualization, querying, updating and information privacy. Therefore, we do have the challenge of preparing data for our Machine Learning processes or tools to perform the discovering patterns. Data Parsers and Convertors We have written a number of web pages on Data Parses, Convertors and Intelligent Data Access Objects (IDAO). http://crmmetadata.com/IntelligentParsersPage.html http://crmmetadata.com/IntelligentConvertorsPage.html http://crmmetadata.com/DataIssuesPage.html http://gdprarchitects.com/IntelligentDAOPage.html Our Intelligent Machine Learning: Our Intelligent Machine Learning has the following structure: • Our Zeros and Ones Concept and Components • Pattern Building Matrices • Build Precision Scale • Fine Tune Pattern using Dynamic Business Rules • Library of Patterns (Using History and Lessons Learned) • Data Preparation • Pattern Discovery • Optimization • Build Reports • Data Visualizations • Developing Machine Leading Code • Testing Our Zeros and Ones Concept and Components The basic concept of any computer is the binary bit (0,1). Computer Science was able to turn this binary 0s and 1s into a revolution of technologies that we are using today. With the same thinking, we use the concept of 0s and 1s to build search patterns. We would also use Dynamic Business Rules as guidance in building the search patterns. We build from Zeros and Ones a Byte, then use bytes to build a word and use words to build patterns. The best way to make our concept more clear is by present Donald toy as an example. The following images are Bits which would be used to build one Byte For Donald: 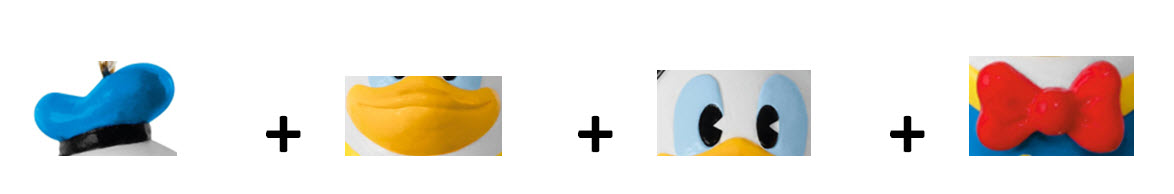
Image #4 The following would be some of possible Bytes which is built from these bits: 
Image #5 The Dynamic Business Rules would help in fine tuning the building of the Bytes, the Words, and finally the Target Pattern(s). The Target Patterns can be scaled, rotated, (side way, upside down, left, mirror image, etc) 
Image #6 The sky is the limit when it comes to build the the Target Pattern(s) and with the speed of the computer processes there is no issues by going "coco" - crazy. Zeros and Ones would be used to build the bytes, then bytes build words and words build patterns - does not make any difference if the data is text, graphic images, sounds waive, etc. The question is: how to develop a Machine Learning Tool which would create the "Bits" and then build the "Bytes, Words and Patterns". Machine Learning Tool Concept: Developing " Machine Learning Tool " is knowledge and subject dependent. For example, in the case of Donald toy, we have some distinct features which can be used to build the First Donald toy Byte. The same thing would be in finding software virus, worm or Trojans, we need to have their distinct features and develop the Bits, Bytes, Words and Patterns. We would build a dynamic libraries of these software virus, worm and Trojans which our Intelligent Machine Learning Tool would use. We would also build Pattern Matrices of these software virus, worm and Trojans. These Matrices can have any number of possible software virus, worm and Trojans, but each possibility has a weight or a score of its accuracy. The history of finding what type of software virus, worm and Trojans would also aid in building the accuracy score or the weight and the possibilities of being used or not used. These Matrices would grow and become diverse to help build possibilities with high score and build intelligence. These Matrices would teach our Intelligence Machine Learning Tool the new or possible occurrences of software virus, worm and Trojans. Matrices crossing would also help create new high score possibilities. Pattern Building Matrices: Tables or Matrices are good tool of presenting possibilities, visions or viewing value, patterns, errors, choices, etc. We recommend the following features plus others features based on the type of business and mapping: 1. We recommend two dimensional Matrices or arrays. 2. They are easy built and used. 3. Linked Lists should be used to dynamically build these Matrices with size limit. 4. No Three dimensional arrays, they are difficult to envision and more complex to work with. 5. The size and the score of these Matrices should be developed to make search and deduction simple. 6. These Matrices are used to map the values, time and other critical elements. 7. Cross reference these Matrices would help in figuring out values, patterns, tendencies, errors, etc. These Matrices would be used to decide the bits and build bytes, words and patterns. Build Precision Scale Abstract Thinking is based on frequencies and statistics. Precisions are on based chances and frequencies. For example, if out of 100 men with age of 40 years old and older, 90 men would lose 50% of their hair. Then a 50 year old man has a 90% chance of losing 50% of his hair. Therefore based on the business and the conditions, we would be able to create score and weight of any value or state. There should be precision Matrices which they can be crossed reference to give relative accuracies. Fine Tune Patterns Using Dynamic Business Rules: Dynamic Business Rules help in giving guidance on decision-making (if-else conditions). These rules can be added at runtime without the need to change code or processes. Libraries of Patterns (Based History and Lessons Learned) These libraries are guidance in critical thinking and fast decision-making. They also can grow to make the system more intelligent and efficient with the fact: "been there and done that". Data Preparation This topic is too big to cover, but we have a number of sites which deal with data and data centers. Pattern Discovery All the previous steps would have created the stage for our Intelligent Machine Learning Tool to do its job and build reports for target results. Optimization Tracking, logs, audit trail, errors, exceptions, performance, issues and other system element should be tracked and analyzed to optimize the system and look for ways to make the system more efficient and intelligent. Automation as a feature is ideal for system performance. Build Reports Report must be customized to answer needs, request, audience, etc. Data Visualizations We need to take reports and make them visually presentable to target audience. Developing Machine Leading Code: This is a big topic to cover, but we will attempt to present 2,000 foot view of the system. For simplicity, we develop the system using reusable components. Each component runs as a virtual object, where horizontal scalability is done by creating an additional virtual object (a virtual server). Let us take the Zeros and Ones Builder component (virtual object which is a virtual server), where it is feed a number of matrices. These matrices would be: • The Zeros and Ones for the target patterns • Dynamic Business Rules • Business Type Building Map The Zeros and One Builder component has the intelligent and the know how to build Byte, Words and Patterns based on the business type map and Dynamic Business Rules. The Zeros and Ones Builder component runs independently and has only one interface. Such component would be built, updated and tested without refactoring. It would be transparent to any system components. Testing Each component is created as a virtual object and runs independently of the rest of system components. It has only a signal interface. Testing these independent components would be done with ease. Rollback would be nothing but changing the IP address to the old-previous virtual component. |
|---|