
Sam Eldin |
CV - Resume | Tools 4 Sharing | Architects 2 Show | Big Data Presentation | Android Training | Java-Unix Code Templates | Interviews QA & Code |
|---|
|
|---|
|
Vertical Scaling of Data Centers
Introduction: Both Vertical and Horizontal Scaling is not fully understood by the IT community: • Vertical means each Unit is modified to have more power, functionality, production, flexibility, .. etc. • Horizontal means add more units. They can be applied to both the hardware (bare-metal) and the software. 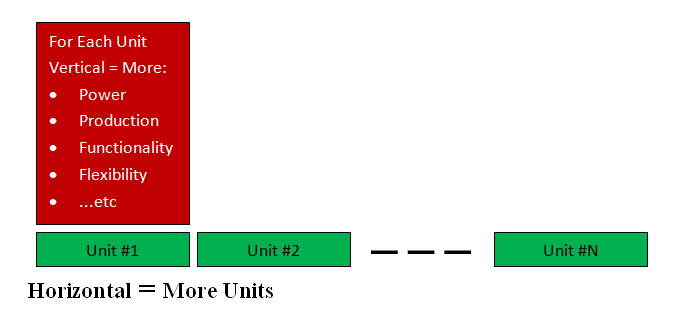
Image #1 Their cost in term of money, time and resources can get out of control with negative results. For example, personally, I would always purchase my laptops with two hard-drives, max number processors-Cache-core memory and a CD reader. I would have both Windows and Linux running independently plus a number of Java (not any more C-C++) and other development environments. These features are the Vertical Scaling of one of my laptops. Buying two laptops would be the Horizontal Scaling. I would also use my old laptops as servers, independent testing and training units. The hard-drives of these laptops would be used as source code backups (filing system) which are Horizontal Scaling. Vertical Scaling of Data Centers: Vertical Scaling of Data Center is very complex and costly undertaking, but the cost of building (bare-metal and software) and running-maintaining (utilities, manpower, ... etc) of data centers is in the $billions. Vertical Scaling is worth the investment. The question is how to Vertically Scale existing data centers? Vertical Scaling as Promoted on the Web (Amazon Web Services and Microsoft Azure): Cloud Vertical Scaling refers to adding more CPU, memory, or I/O resources to an existing server, or replacing one server with a more powerful server. Amazon Web Services (AWS) vertical scaling and Microsoft Azure vertical scaling can be accomplished by changing instance sizes, or in a data center by purchasing a new, more powerful appliance and discarding the old one. AWS and Azure cloud services have many different instance sizes, so scaling vertically is possible for everything from Elastic Compute Cloud (EC2) instances to Amazon Relational Databases (RDS). Our Way of Thinking When It Comes to Vertical Scaling: To simplify our vertical scaling, let us look at the following data and assume that the data is correct for our argument sake. We can see the number of servers and their configuration as follows: • Google: 900,000 server • Amazon: 454,400 servers How much RAM do Google servers have? • 512 MB • 2 X 300 MHz dual Pentium II servers donated by Intel, they included 512 MB of RAM • 10 X 9 GB hard drives between the two. What factors would be considered to make Vertical Scaling economically feasible? CPU, core, clock speed, cache memory, core memory, bus, chip manufacture support, software support, VM, labor, time, testing and cost. Possible Bare-Metal Server Contents: Each of these bare-metal server may have a number of virtual servers running within it. For the sake of our illustration, let us say one bare-metal server has 20 independent virtual server running within it. Lets us call this server "Sam Server." Our question is: Ley us assume we have a Data Centers with one million bare-metal server. How can we vertically scale this data center 4,8,16 or 32 virtual million servers? What we mean is how to vertically scale one million "Sam Server" into: • 4 million "Sam Server" • 8 million "Sam Server" • 16 million "Sam Server" • 32 million "Sam Server" • 64 million "Sam Server" - far fetch Our DevOps and DataOps: Scaling 32 million "Sam Server" would require configuring the following: (32 million "Sam Server") X 20 Virtual servers running within "Sam Server" = 640 million setting Daily-Manual-Physical configuring of 640 million setting without automation and intelligence would be impossible if not ridicules. Any data center requires constant monitoring and configuring 24X7 with rollback plans and processes. Therefore, intelligence and automation are a must in managing and running any data center. Our DevOps and DataOps would be the missing links in automating such Vertical Scaling. In general, an editor refers to any program capable of editing files. Good examples are image editors, such as Adobe Photoshop, and sound editors, such as Audacity or for text editor such as Microsoft Word or WordPerfect. We have architect and built prototypes for the following categories of intelligent automated DevOps and DataOps Editors. Our Editors are developed for two different users: 1) Infrastructure Teams: To build and monitors and maintain all the infrastructure support such as servers, networks, clusters, routers .. etc plus testing. 2) End Users (Development or any department): To build virtual servers (containers) with any number of applications or services (components). DevOps is for all purpose of building infrastructure DataOps is the data support for DevOps since handling data would require special processes. Before we can start any analyses or Proof of Concept, there is a number of questions needs to be addressed first. As an outsider looking in, sadly the politics associated with these questions would make their answers quite inaccurate. The following are the main obstacles which we need to address before performing the vertical scaling: 1. Accurate Data Center infrastructure management 2. Using Software to perform inventory of every components (hardware and software) of the data center 3. Redundancies (good and bad) 4. Working with Hardware vendors to customize the Hardware upgrade 5. What are Data Center management hidden secrets? 6. Migration issues 7. Staff talents, communication and issues (on/offshore) 8. Testing 9. Training 10. Automated and Intelligent DevOps and DataOps We would be more than happy to provide Proof of Concepts (POC) and Business Plan Summary. |
|---|